Configurar a alta disponibilidade e recuperação de desastre
Uma parte importante da configuração de soluções de alta disponibilidade e recuperação de desastre no SQL Server permanece a mesma no SQL Server em execução na Máquina Virtual do Azure. A solução de alta disponibilidade foi projetada para garantir que nenhum dado confirmado seja perdido devido a falhas, que sua carga de trabalho não seja afetada pelas operações de manutenção e que o banco de dados não se torne um ponto único de falha em sua arquitetura de software.
A maioria das camadas de serviço do SQL do Azure oferece uma variedade de opções de alta disponibilidade, desde redundância local até modelos de redundância de zona.
Em seguida, exploraremos as soluções específicas para recuperação de desastre e alta disponibilidade para as ofertas de PaaS do Azure.
Backup contínuo
O Banco de Dados SQL do Azure garante backups regulares e contínuos de bancos de dados, que são replicados para um armazenamento com redundância geográfica com acesso de leitura (RA-GRS).
Backups completos semanais, backups diferenciais a cada 12 a 24 horas e backups de log de transações a cada 5 a 10 minutos fazem parte da estratégia de backup automatizado. Para disponibilidade de backup estendida (até 10 anos), a retenção de longo prazo (LTR) pode ser configurada para bancos de dados individuais e em pool.
LTR (retenção de longo prazo)
O Azure oferece uma política de retenção que você pode definir além dos limites usuais, o que é útil para cenários que exigem retenção de longo prazo. Você pode definir uma política de retenção por até 10 anos, e essa opção é desabilitada por padrão.

A imagem mostra como configurar políticas de retenção de longo prazo no portal do Azure. Depois de escolher o banco de dados, um painel aparecerá no lado direito da tela, onde você poderá alterar as configurações padrão.
Para obter mais informações sobre retenção de longo prazo, confira Retenção de longo prazo – Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure.
Restauração geográfica
Os backups de Banco de Dados SQL e Instância Gerenciada de SQL têm redundância geográfica por padrão. Isso permite que você restaure facilmente bancos de dados para uma região geográfica diferente, um recurso que é útil para cenários de recuperação de desastre menos rigorosos.
O armazenamento de backup é cobrado além de um armazenamento de arquivos de banco de dados normal. Porém, ao provisionar um Banco de Dados SQL, o armazenamento de backup é criado com o tamanho máximo da camada de dados selecionada para seu banco de dado sem custo adicional.
A duração de uma operação de restauração geográfica pode ser afetada por vários componentes subjacentes, incluindo o tamanho do banco de dados, o número de logs de transações envolvidos em uma operação de restauração e a quantidade de solicitações de restauração simultâneas que estão sendo processadas na região de destino.
PITR (Restauração pontual)
Você pode restaurar seus bancos de dados para um ponto específico no tempo, de acordo com a retenção definida, mas só haverá suporte para PITR se você estiver restaurando um banco de dados no mesmo servidor no qual o backup foi originado. Você pode usar o portal do Azure, o Azure PowerShell, a CLI do Azure ou a API REST para restaurar um Banco de Dados SQL.
Replicação geográfica ativa
Um método para aumentar a disponibilidade do banco de dados SQL do Azure é usar a replicação geográfica ativa. Ela cria réplica do banco de dados secundário em outra região que é atualizada de forma assíncrona.
Essa réplica é legível, semelhante a um grupo de disponibilidade AlwaysOn no SQL Server. Abaixo da superfície, o Azure usa grupos de disponibilidade para manter essa funcionalidade, por isso algumas das terminologias são semelhantes.
A replicação geográfica ativa fornece continuidade dos negócios, permitindo que os clientes façam failover de forma programática ou manual dos bancos de dados primários para regiões secundárias durante um grande desastre.
Observação
A Instância Gerenciada de SQL do Azure não dá suporte à replicação geográfica ativa. Em vez disso, você deve usar grupos de failover automático, um tópico que exploraremos mais adiante nesta unidade.
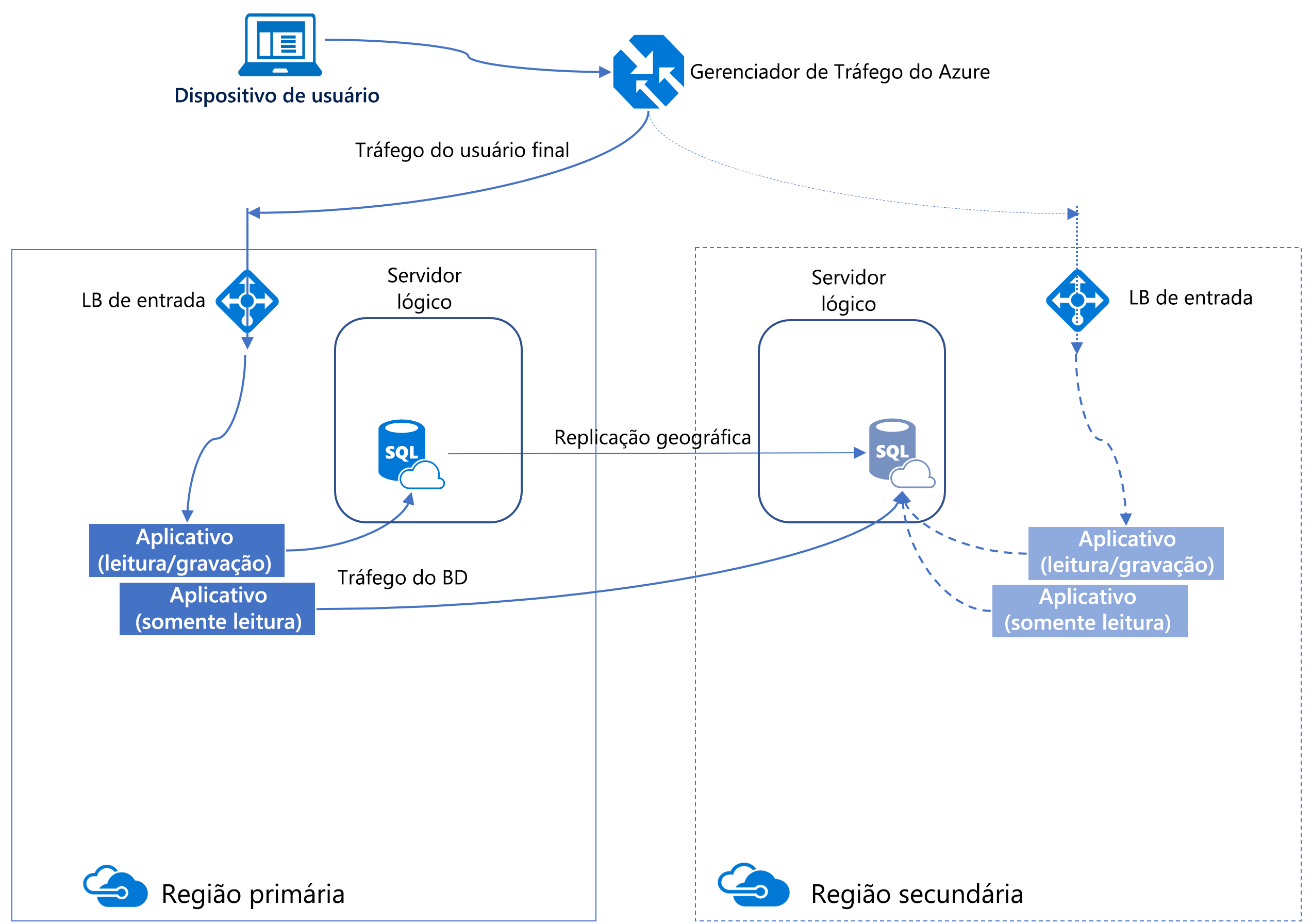
Todos os bancos de dados envolvidos em uma relação de replicação geográfica são necessários para ter a mesma camada de serviço. Além disso, para evitar problemas de desempenho de replicação devido a uma carga de trabalho de gravação pesada, recomendamos configurar a réplica secundária com o mesmo tamanho de computação que a primária.

É possível configurar manualmente a replicação geográfica para o Banco de Dados SQL do Azure acessando a folha do banco de dados, na seção Gerenciamento de dados, e selecionando Réplicas e + Criar réplica.

Depois que a réplica secundária for estabelecida, você terá a opção de iniciar um failover manualmente. Nesse processo, as funções são invertidas – a réplica secundária assume a função da primária, enquanto a primária original se torna a secundária.
Replicação geográfica entre assinaturas
Em determinados cenários, pode ser necessário configurar uma réplica secundária em uma assinatura diferente do banco de dados primário. É aí que entra em jogo o recurso de replicação geográfica entre assinaturas.
Observação
A replicação geográfica entre assinaturas só está disponível programaticamente.
Para saber mais sobre as etapas necessárias para configurar uma replicação geográfica entre assinaturas, confira Replicação geográfica entre assinaturas.
Grupos de failover automático
Um grupo de failover automático é um recurso de alta disponibilidade compatível com o Banco de Dados SQL do Azure e a Instância Gerenciada de SQL do Azure. Os grupos de failover automático permitem gerenciar como os bancos de dados são replicados para outra região e como o failover pode acontecer. O nome atribuído ao grupo de failover automático deve ser exclusivo no domínio *. database.windows.net.
Um grupo de failover automático pode incluir vários bancos de dados. O primário e o secundário têm o mesmo tamanho de banco de dados.
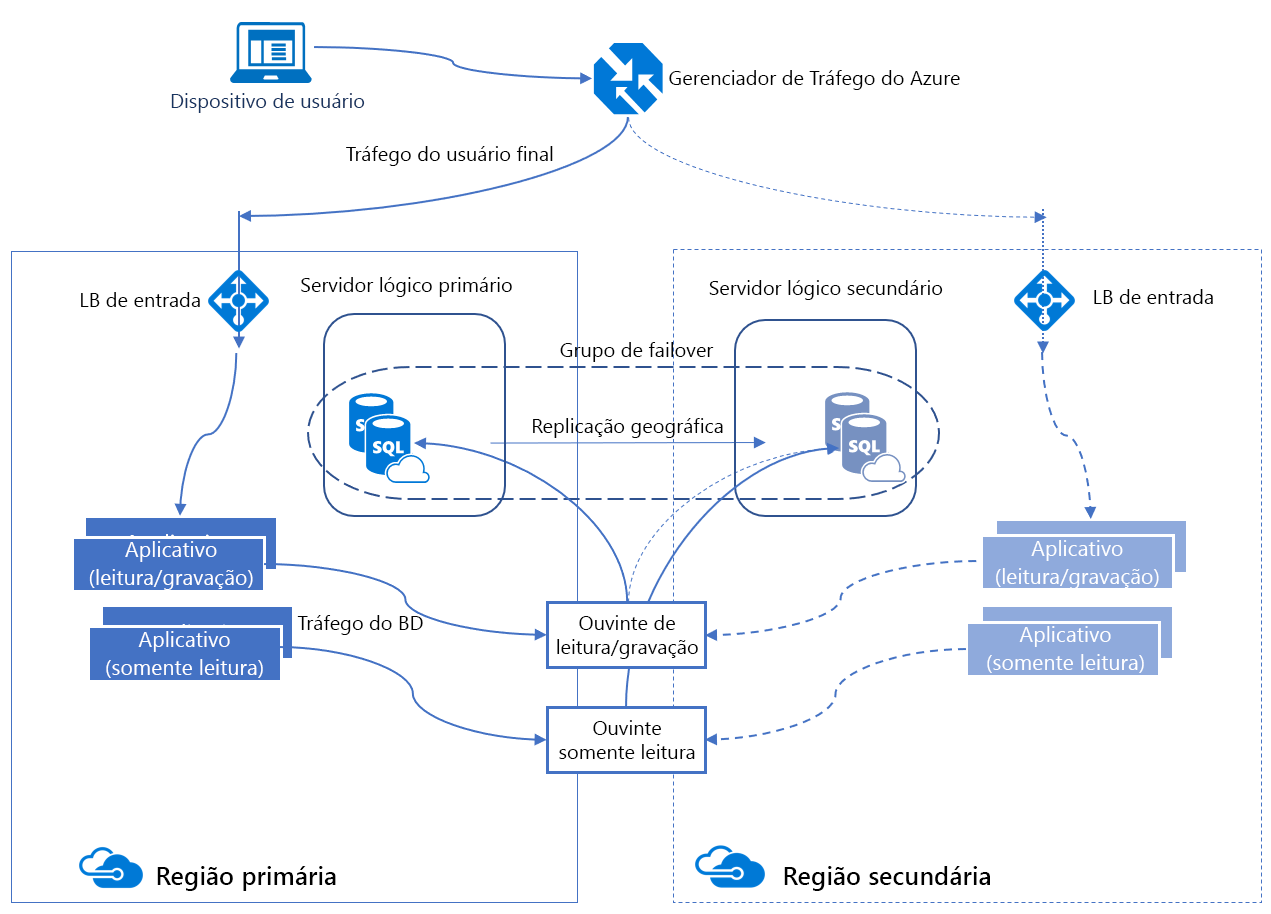
Os grupos de failover automático fornecem uma funcionalidade chamada ouvinte, semelhante ao AG, que permite as atividades de leitura/gravação e somente leitura. Há dois tipos diferentes de ouvintes: um para o tráfego de leitura/gravação e outro para o tráfego somente leitura. Em segundo plano em um failover, o DNS é atualizado para que os clientes possam apontar para o nome do ouvinte abstrato sem precisar saber mais nada. O servidor de banco de dados primário contém as cópias de leitura/gravação e o servidor secundário recebe as transações desse servidor.
Há duas políticas diferentes para grupos de failover automático.
| Tipo de Política | Descrição |
|---|---|
| Automático | Quando uma falha é detectada, o sistema dispara um failover automaticamente por padrão. No entanto, se necessário, você pode desabilitar o failover automático. |
| Somente leitura | Durante um failover, o mecanismo desabilita o ouvinte somente leitura por padrão para manter o desempenho do novo primário quando o secundário está inativo. No entanto, você pode alterar esse comportamento para permitir os dois tipos de tráfego após um failover. |
O failover é um processo que pode ser iniciado manualmente, mesmo quando o failover automático está habilitado. No entanto, o tipo de failover pode influenciar se a perda de dados ocorre. Por exemplo, um failover não planejado poderá levar à perda de dados se for forçado e o banco de dados secundário não tiver sido totalmente sincronizado com o primário.
O GracePeriodWithDataLossHours determina o tempo que o Azure aguarda antes de iniciar um failover, com o valor padrão definido como uma hora. Se o objetivo de ponto de recuperação (RPO) for rigoroso e a perda de dados não for uma opção, você poderá definir esse valor mais alto. Embora isso signifique que o Azure aguarda mais tempo antes de iniciar um failover, isso pode potencialmente reduzir a perda de dados, pois fornece mais tempo para o banco de dados secundário sincronizar totalmente com o primário.
Observação
O banco de dados secundário é criado automaticamente por meio de um processo conhecido como propagação, o que pode levar tempo dependendo do tamanho do banco de dados. Portanto, é importante planejar com antecedência, considerando fatores como a velocidade da rede.
Para saber mais sobre alta disponibilidade e recuperação de desastre para Banco de Dados SQL do Azure, confira Lista de verificação de alta disponibilidade e recuperação de desastres do Banco de Dados SQL do Azure.