Configurar o encerramento antecipado
O ajuste do hiperparâmetro ajuda você a ajustar seu modelo e selecionar os valores de hiperparâmetro que farão com que seu modelo tenha o melhor desempenho.
Encontrar o melhor modelo, porém, pode se revelar uma conquista interminável. Você sempre precisa considerar se vale a pena o tempo e a despesa de testar novos valores de hiperparâmetro para encontrar um modelo que possa ter um desempenho melhor.
Em cada avaliação de um trabalho de varredura, um novo modelo é treinado com uma nova combinação de valores de hiperparâmetro. Se o treinamento de um novo modelo não resultar em um modelo significativamente melhor, convém interromper o trabalho de varredura e usar o modelo que teve o melhor desempenho até agora.
Ao configurar um trabalho de varredura no Azure Machine Learning, você também pode definir um número máximo de avaliações. Uma abordagem mais sofisticada pode ser interromper um trabalho de varredura quando modelos mais recentes não produzem resultados significativamente melhores. Para interromper um trabalho de varredura, você pode usar uma política de interrupção antecipada com base no desempenho dos modelos .
Quando usar uma política de término antecipado
Se você deseja usar uma política de término antecipado pode depender do espaço de pesquisa e do método de amostragem com o qual você está trabalhando.
Por exemplo, você pode optar por usar um método de amostragem em grade em vez de um espaço de busca discreto , o que resulta em um máximo de seis tentativas. Com seis tentativas, serão treinados no máximo seis modelos, e uma política de término antecipado pode ser desnecessária.
Uma política de término antecipado pode ser especialmente benéfica ao trabalhar com hiperparâmetros contínuos em seu espaço de pesquisa. Hiperparâmetros contínuos apresentam um número ilimitado de valores possíveis para escolher. Você provavelmente desejará usar uma política de término antecipado ao trabalhar com hiperparâmetros contínuos e um método de amostragem aleatório ou bayesiano.
Configurar uma política de término antecipado
Há dois parâmetros principais quando você opta por usar uma política de encerramento antecipada:
-
evaluation_interval: especifica em qual intervalo você deseja que a política seja avaliada. Toda vez que a métrica primária é registrada para uma avaliação conta como um intervalo. -
delay_evaluation: especifica quando começar a avaliar a política. Esse parâmetro permite que um número mínimo de avaliações sejam completadas sem que uma política de encerramento antecipado as afete.
Os novos modelos podem continuar a ter um desempenho ligeiramente melhor do que os modelos anteriores. Para determinar até que ponto um modelo deve ter um desempenho melhor do que as avaliações anteriores, há três opções para término antecipado:
-
de política do Bandit: usa um
slack_factor(relativo) ouslack_amount(absoluto). Qualquer novo modelo deve operar dentro da faixa de tolerância do modelo de melhor desempenho. - Política de Interrupção Mediana: usa a mediana das médias da métrica primária. Qualquer novo modelo deve ter um desempenho melhor que a mediana.
- A política de seleção de truncamento: usa um
truncation_percentage, que é o percentual de testes de menor desempenho. Qualquer novo modelo deve ter um desempenho melhor do que as avaliações de menor desempenho.
Política de bandido
Você pode usar uma política de bandido para interromper um teste se a métrica de desempenho alvo estiver abaixo do desempenho da melhor tentativa até agora por uma margem especificada.
Por exemplo, o código a seguir aplica uma política de bandido com um atraso de cinco avaliações, avalia a política a cada intervalo e permite uma quantidade de margem de atraso absoluta de 0,2.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
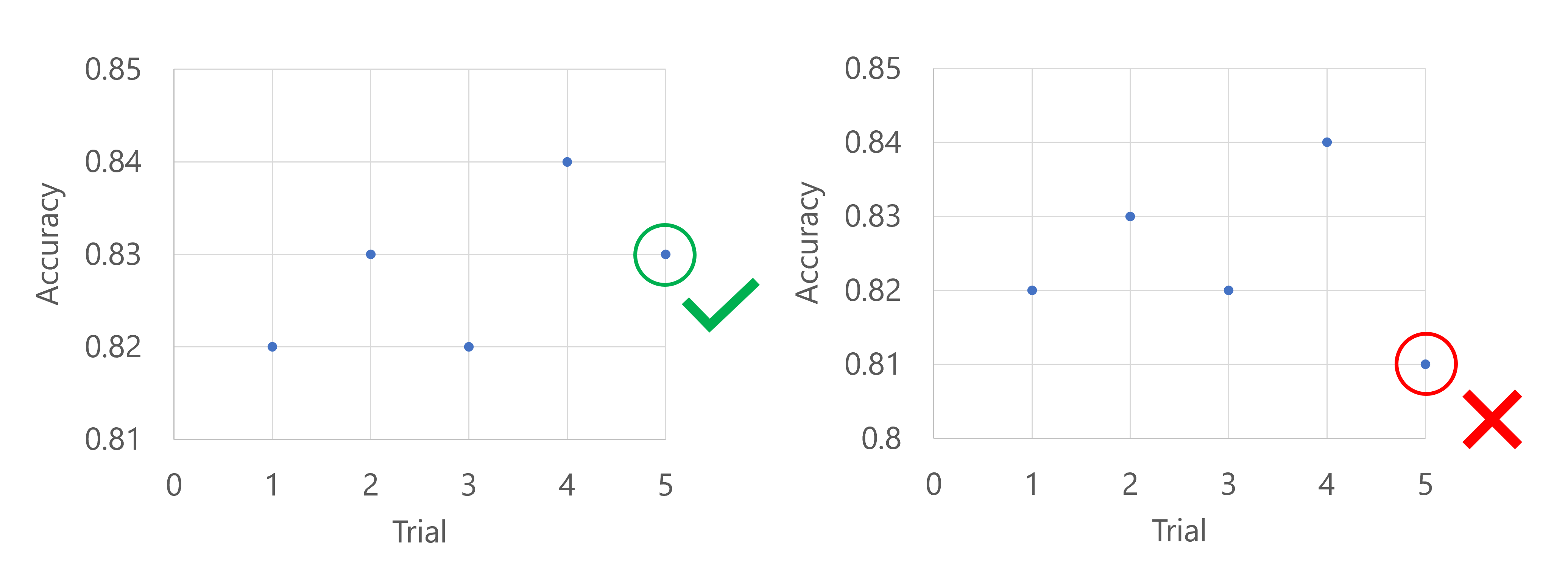
Imagine que a métrica primária é a precisão do modelo. Quando após as cinco primeiras avaliações, o modelo com melhor desempenho tem uma precisão de 0,9, qualquer novo modelo precisa ter um desempenho melhor do que (0.9-0.2) ou 0,7. Se a precisão do novo modelo for maior que 0,7, o trabalho de varredura continuará. Se o novo modelo tiver uma pontuação de precisão inferior a 0,7, a política encerrará o trabalho de varredura.
Você também pode aplicar uma política de bandido usando uma de fator dede margem de atraso, que compara a métrica de desempenho como uma taxa em vez de um valor absoluto.
Política de parada mediana
Uma política de interrupção mediana abandona experimentos em que a métrica de desempenho alvo é pior do que a mediana das médias móveis para todos os experimentos.
Por exemplo, o código a seguir aplica uma política de parada mediana com um atraso de cinco tentativas e avalia a política a cada intervalo.
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
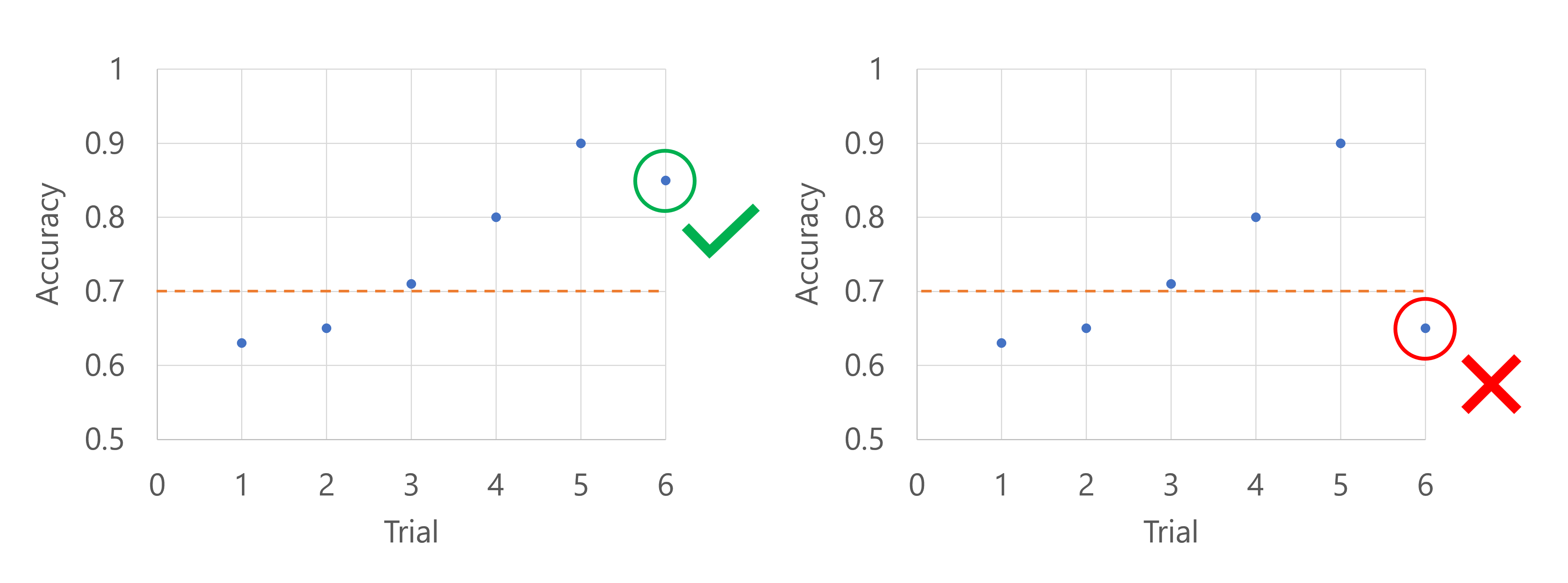
Imagine que a métrica primária é a precisão do modelo. Quando a precisão é registrada para a sexta avaliação, a métrica precisa ser maior do que a mediana das pontuações de precisão até agora. Suponha que a mediana das pontuações de precisão até agora seja 0,82. Se a precisão do novo modelo for maior que 0,82, o trabalho de varredura continuará. Se o novo modelo tiver uma pontuação de precisão inferior a 0,82, a política interromperá o trabalho de varredura e nenhum novo modelo será treinado.
Política de seleção de truncamento
Uma política de seleção de truncamento cancela os testes com o pior desempenho X% em cada intervalo de avaliação com base no valor truncation_percentage que você especificar para X.
Por exemplo, o código a seguir aplica uma política de seleção de truncamento com um atraso de quatro avaliações, avalia a política a cada intervalo e usa um percentual de truncamento de 20%.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
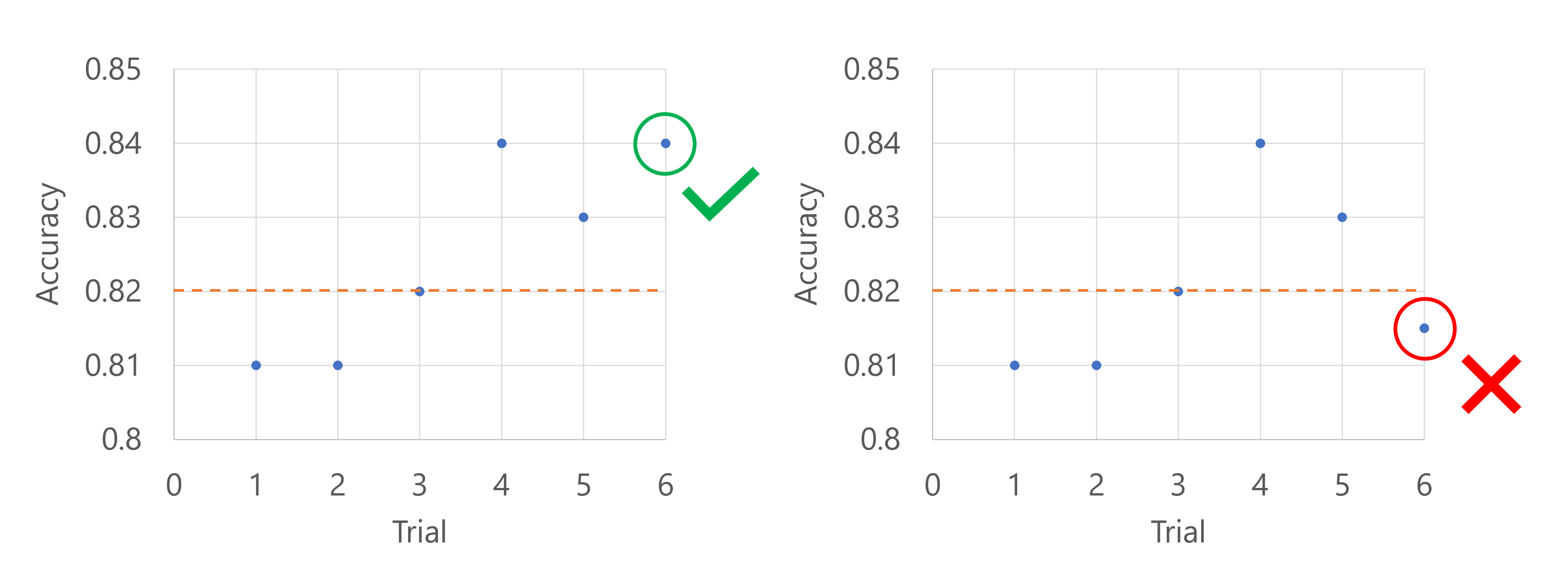
Imagine que a métrica primária é a precisão do modelo. Quando a precisão é registrada para a quinta avaliação, a métrica não deve estar nos piores 20% das avaliações até agora. Nesse caso, 20% correspondem a um ensaio. Em outras palavras, se a quinta avaliação for não o modelo com o pior desempenho até agora, o processo de varredura continuará. Se a quinta avaliação tiver a menor pontuação de precisão de todas as avaliações até agora, o trabalho de varredura será interrompido.