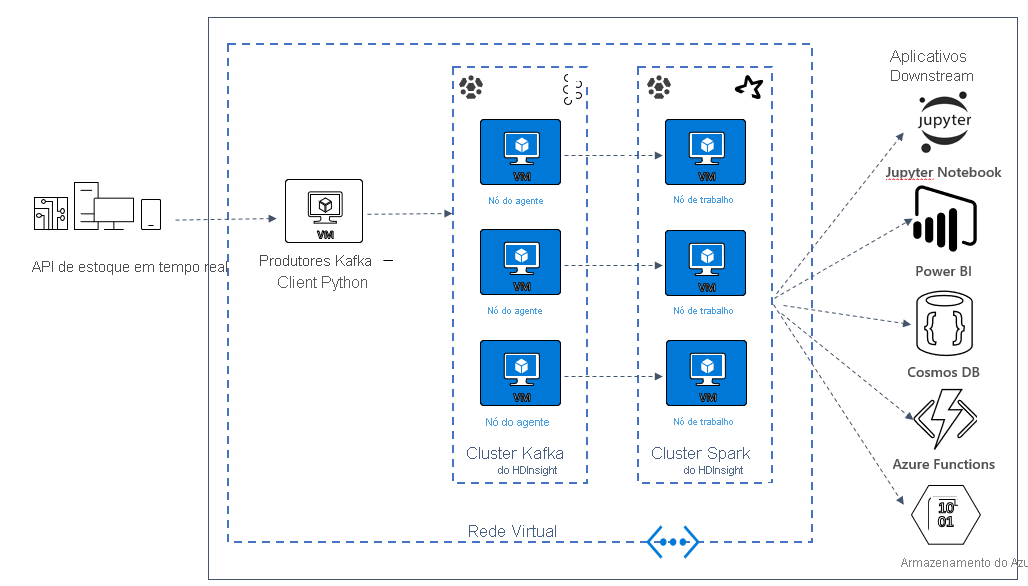
Criar uma arquitetura do Kafka e do Spark
Para usar o Kafka e o Spark juntos no Azure HDInsight, você deve colocá-los na mesma VNet ou emparelhar as VNets para que os clusters operem com a resolução de nomes DNS.
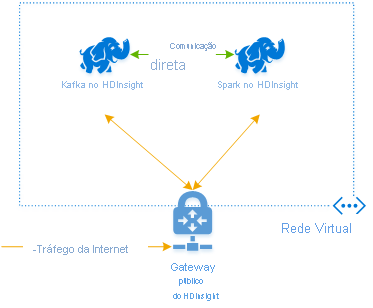
Para criar clusters na mesma VNet, o procedimento é:
- Criar um grupo de recursos
- Adicionar uma VNet ao grupo de recursos
- Adicione um cluster do Kafka e um cluster do Spark à mesma VNet ou, como alternativa, emparelhe as VNets nas quais esses serviços operam com a resolução de nomes DNS.
A maneira recomendada de conectar os clusters do Kafka e do Spark do HDInsight é o conector Spark-Kafka nativo, que permite que o cluster do Spark acesse partições individuais de dados no cluster do Kafka, aumentando o paralelismo no trabalho de processamento em tempo real, com uma taxa de transferência muito alta.
Quando ambos os clusters estão na mesma VNet, você também pode usar FQDNs do agente Kafka no código de streaming do Spark e criar regras NSG na VNet para segurança empresarial.
Arquitetura da solução
Os padrões de análise de streaming em tempo real no Azure normalmente usam a arquitetura da solução a seguir.
- Ingerir: dados não estruturados ou estruturados são ingeridos em um cluster do Kafka no Azure HDInsight.
- Preparar e treinar: os dados são preparados e treinados com o Spark no HDInsight.
- Modelar e servir: os dados são colocados em um data warehouse como o Azure Synapse ou o HDInsight Interactive Query.
- Inteligência: os dados são enviados para o painel de análise, como o Power BI ou o Tableau.
- Armazenar: os dados são colocados em uma solução de armazenamento frio, como o Armazenamento do Azure, e enviados posteriormente.
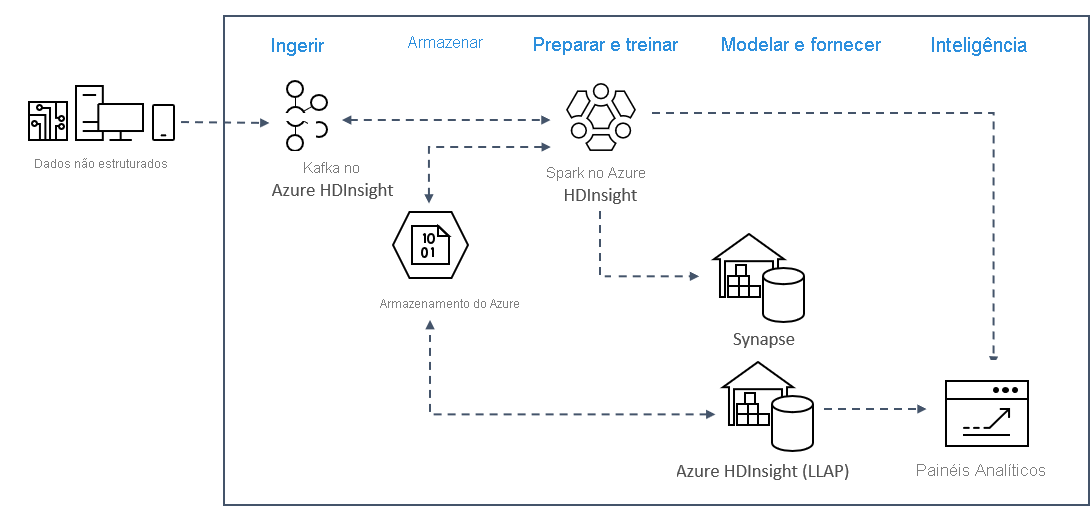
Arquitetura de cenário de exemplo
Na próxima unidade, você começará a criar a arquitetura da solução para o aplicativo de exemplo. Este exemplo usa um arquivo de modelo do Azure Resource Manager para criar o grupo de recursos, a VNet, o cluster do Spark e o cluster do Kafka.
Depois que os clusters forem implantados, você usará o ssh em um dos agentes Kafka e copiará o arquivo do produtor do Python para o cabeçalho. Esse arquivo de produtor fornece preços de ações artificiais a cada dez segundos, além de gravar o número da partição e o deslocamento da mensagem no console.
Depois que o produtor estiver em execução, você poderá carregar o Jupyter Notebook no cluster do Spark. No notebook, você conectará os clusters do Spark e do Kafka e executará algumas consultas de exemplo nos dados, incluindo localizar os valores altos e baixos de uma ação em uma janela de evento.