Considerações sobre fixação de processos
Por que fixar processos e threads?
Sempre fixe processos a núcleos específicos para ajudar a alcançar o desempenho máximo e obter desempenho mais consistente a cada execução.
Fixação de processo:
Maximiza a largura de banda da memória colocando ou fixando processos em locais que usam e distribuem todos os canais de memória igualmente entre os núcleos.
Melhora o desempenho de ponto flutuante garantindo que cada processo esteja em seu próprio núcleo. Isso elimina a possibilidade de dois processos caírem no mesmo núcleo.
Coloca os processos que se comunicam em nós de domínio NUMA (acesso não uniforme à memória) para otimizar a movimentação de dados entre eles. Isso garante que os processos tenham menor latência e largura de banda mais alta.
Reduz a sobrecarga do sistema operacional e oferece resultados mais consistentes porque o sistema operacional não pode mover processos para núcleos ou domínios NUMA diferentes.
Onde fixar processos e threads?
Para determinar onde fixar processos e threads, primeiro é necessário compreender a topologia de processador e de memória e, especificamente, o número e o local dos domínios NUMA.
O utilitário lstopo-no-graphics (do RPM hwloc) e o MLC (Memory Latency Checker) da Intel são ferramentas úteis para determinar a topologia de memória e processador. Por exemplo: quantos domínios NUMA a VM tem? Quais núcleos são membros de cada domínio NUMA? Qual é a latência e a largura de banda dos processos em cada domínio NUMA quando eles se comunicam entre si?
A imagem a seguir exibe o mapa de latência de domínios NUMA HB120_v2 gerado pelo MLC da Intel. Quanto menor for a latência entre domínios NUMA, mais rápida será a comunicação entre eles. A ilustração mostra claramente que HB120_v2 tem 30 domínios NUMA e quais domínios NUMA estão em qual soquete. Ela também mostra quais domínios NUMA podem ser agrupados para obter a menor latência de comunicação e transferência de dados.

Os processadores Intel têm seis canais de memória, e os processadores AMD EPYC têm oito. Lembre-se de usar todos os canais de memória para maximizar a largura de banda de memória disponível. Faça isso distribuindo os processos paralelos de maneira uniforme entre os domínios do nó NUMA. No caso de aplicativos paralelos híbridos, mantenha o agrupamento de processo/thread nos mesmos domínios NUMA, idealmente compartilhando o mesmo cache L3. Lembre-se de que a contagem total de threads não deve exceder o número total de núcleos.
A imagem a seguir ilustra um SKU HC44 com 2 domínios NUMA e 44 núcleos.
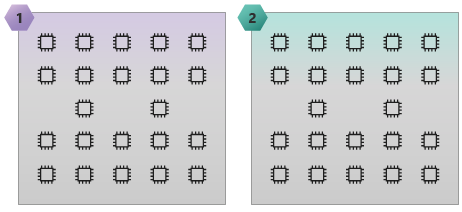
A imagem a seguir ilustra um SKU HB60 com 15 domínios NUMA e 60 núcleos.
Aplicativos limitados pela largura de banda da memória
Se você tiver um aplicativo limitado pela largura de banda de memória, poderá obter um melhor desempenho na VM reduzindo o número de threads e processos paralelos em cada domínio de nó NUMA. Isso pode fornecer mais largura de banda de memória por processo e, possivelmente, reduzir o tempo total do relógio.
Por exemplo, se estiver usando o SKU HB120_v2 com 30 domínios de nó NUMA, você poderá tentar executar 1, 2 e 3 processos e threads por domínio de nó NUMA (por exemplo, 30, 60 e 90 processos e threads por VM). Então você conseguirá ver qual configuração oferece o melhor desempenho.