Integração contínua e implantação
Integração contínua é a prática de testar cada alteração feita em sua base de código automaticamente e o mais cedo possível. A entrega contínua segue o teste que acontece durante a integração contínua e envia as alterações para um sistema de preparo ou produção.
No Azure Data Factory, CI/CD (integração e entrega contínuas) significa mover pipelines do Data Factory de um ambiente (desenvolvimento, teste, produção) para outro. O Azure Data Factory utiliza modelos do Azure Resource Manager para armazenar a configuração de suas várias entidades do Azure Data Factory (pipelines, conjuntos de dados, fluxos e assim por diante). Há dois métodos sugeridos para promover um data factory para outro ambiente:
- Implantação automatizada usando a integração do Data Factory com o Azure Pipelines.
- Carregue manualmente um modelo do Resource Manager usando a integração da UX do Data Factory ao Azure Resource Manager.
Ciclo de vida de integração contínua/entrega contínua
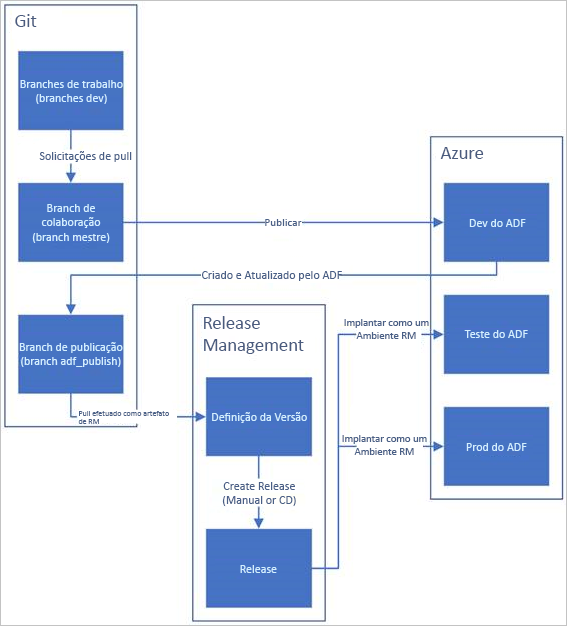
Abaixo há uma visão geral de exemplo do ciclo de vida de CI/CD em um Azure Data Factory configurado com o Git do Azure Repos.
Um data factory de desenvolvimento é criado e configurado com o Git do Azure Repos. Todos os desenvolvedores devem ter permissão para criar recursos do Data Factory como pipelines e conjuntos de dados.
Um desenvolvedor cria um branch de recurso para fazer uma alteração. Ele depura as execuções do pipeline com as alterações mais recentes.
Depois que um desenvolvedor estiver satisfeito com as alterações, poderá criar uma solicitação de pull do branch de recurso para o branch mestre ou de colaboração para que as alterações sejam examinadas por pares.
Depois que uma solicitação de pull for aprovada e as alterações forem mescladas no branch mestre, as alterações serão publicadas no alocador de desenvolvimento.
Quando a equipe estiver pronta para implantar as alterações em um alocador de teste ou UAT (teste de aceitação do usuário), ela acessará a versão do Azure Pipelines e implantará a versão desejada do alocador de desenvolvimento em UAT. Essa implantação ocorre como parte de uma tarefa do Azure Pipelines e usa parâmetros do modelo do Resource Manager para aplicar a configuração apropriada.
Depois que as alterações tiverem sido verificadas no alocador de testes, implante no alocador de produção usando a próxima tarefa da versão de pipelines.
Observação
Somente o alocador de desenvolvimento está associado a um repositório git. Os alocadores de teste e produção não devem ter um repositório git associado a eles e só devem ser atualizados por meio de um pipeline do Azure DevOps ou por meio de um modelo do Resource Manager.
A imagem abaixo realça as diferentes etapas desse ciclo de vida.
Automatizar a integração contínua usando versões do Azure Pipelines
A seguir há um guia para configurar uma versão do Azure Pipelines que automatiza a implantação de um data factory em vários ambientes.
Requisitos
Uma assinatura do Azure vinculada ao Visual Studio Team Foundation Server ou Azure Repos que usa o ponto de extremidade de serviço do Azure Resource Manager
Um data factory configurado com a integração do Git do Azure Repos.
Um Azure Key Vault que contém os segredos para cada ambiente.
Configurar um lançamento do Azure Pipelines
Em Azure DevOps, abra o projeto configurado com seu data factory.
No lado esquerdo da página, selecione Pipelines e, em seguida, selecione Versões.
Selecione Novo pipeline ou, se tiver pipelines existentes, selecione Novo e, em seguida, Novo pipeline de lançamento.
Selecione o modelo Trabalho vazio.
Na caixa Nome da fase, insira o nome do seu ambiente.
Selecione Adicionar artefato e, em seguida, selecione o repositório do git configurado com seu data factory de desenvolvimento. Selecione o branch de publicação do repositório para o Branch padrão. Por padrão, esse branch de publicação é
adf_publish. Para a Versão padrão, selecione Mais recente do branch padrão.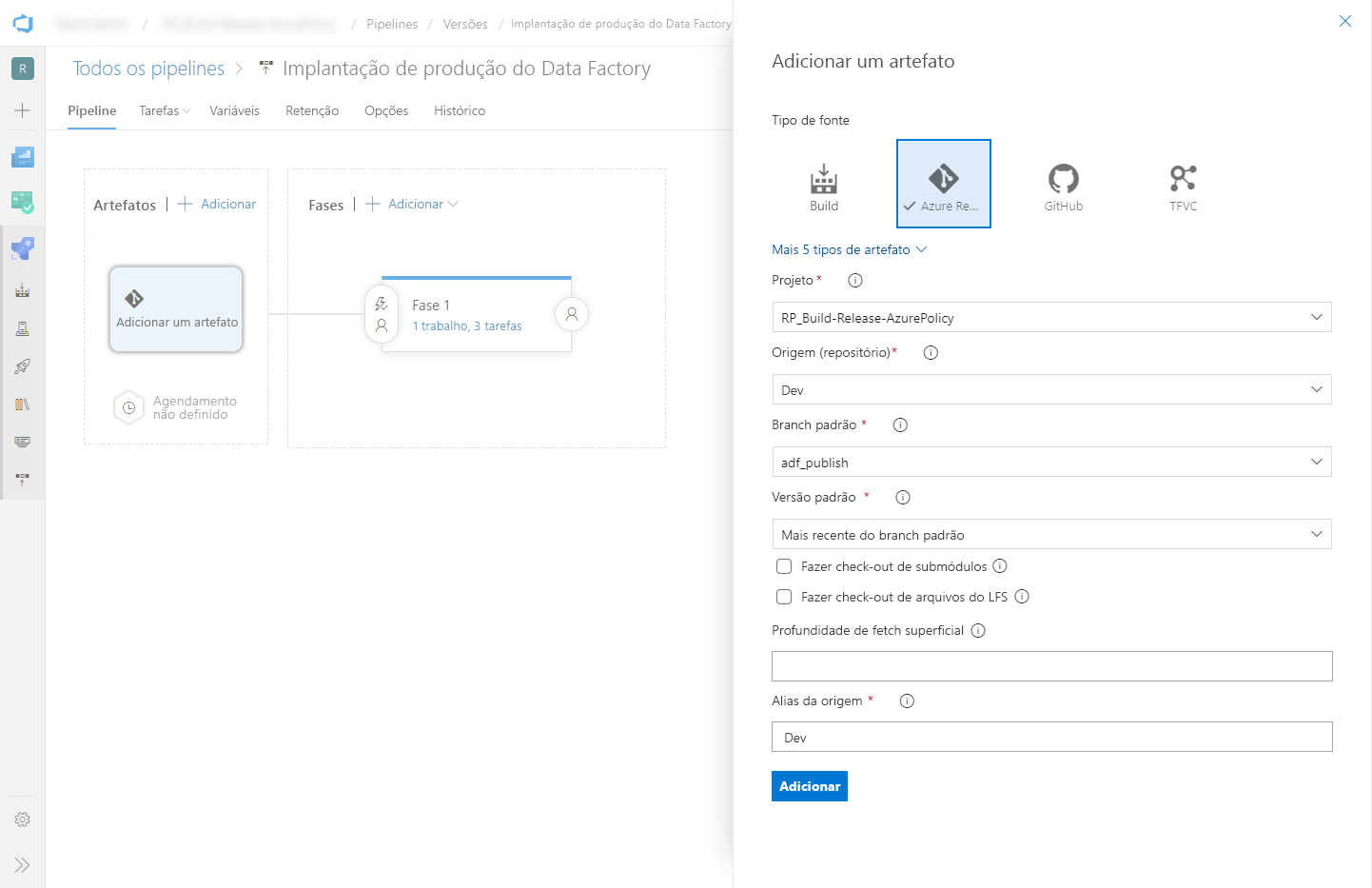
Adicione uma tarefa de Implantação do Azure Resource Manager:
a. No modo de exibição de fase, selecione Exibir tarefas da fase.
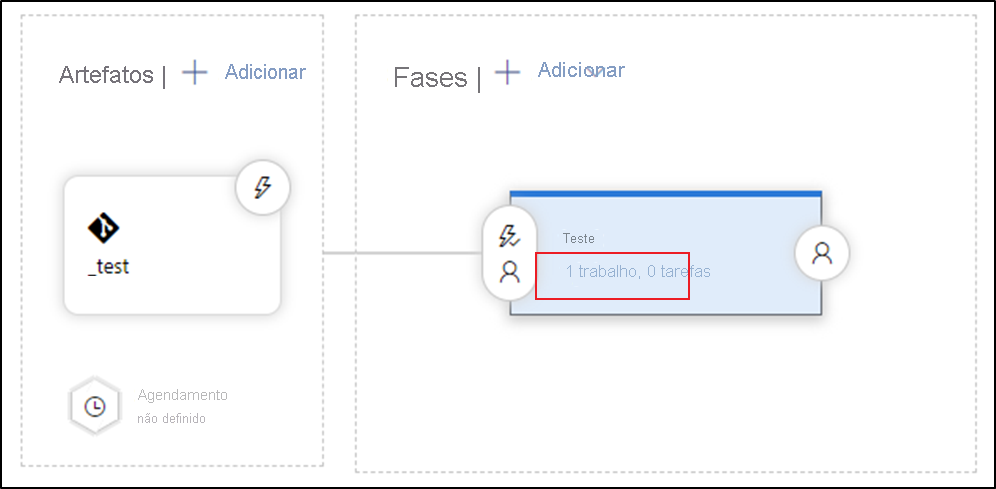
b. Crie uma tarefa. Pesquise Implantação de Modelo do ARM e Adicionar.
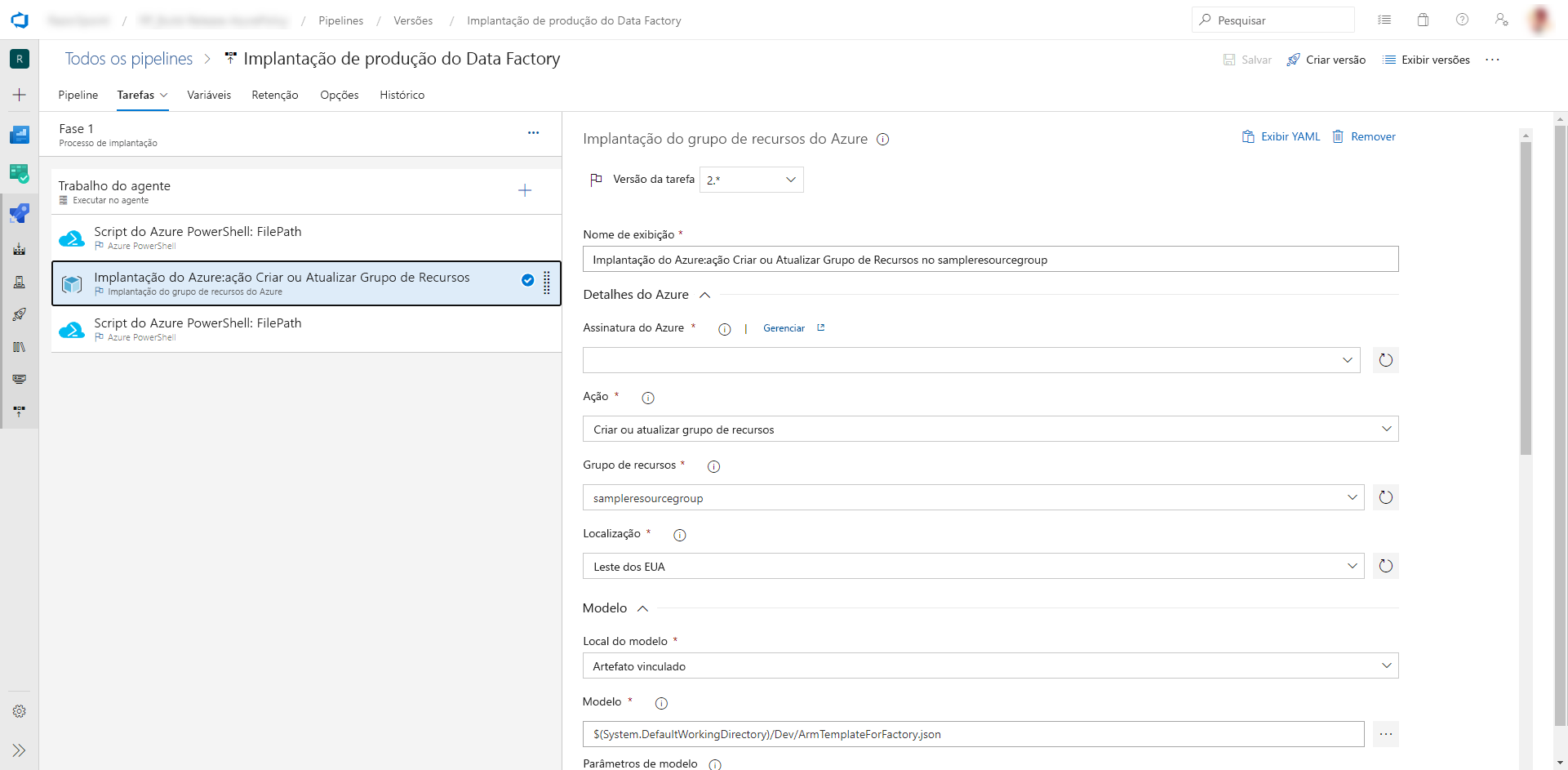
c. Na Tarefa de implantação, selecione a assinatura, o grupo de recursos e a localização do data factory de destino. Forneça as credenciais, se necessário.
d. Na lista Ação, selecione Criar ou atualizar grupo de recursos.
e. Selecione o botão de reticências ( … ) ao lado da caixa Modelo. Procure o modelo do Azure Resource Manager gerado no branch de publicação do repositório do git configurado. Procure o arquivo
ARMTemplateForFactory.jsonna pasta<FactoryName>do branch adf_publish.f. Selecione … ao lado da caixa Parâmetros do modelo para escolher o arquivo de parâmetros. Procure o arquivo
ARMTemplateParametersForFactory.jsonna pasta<FactoryName>do branch adf_publish.g. Selecione … ao lado da caixa Substituir parâmetros de modelo e insira os valores de parâmetro desejados para o data factory de destino. Para as credenciais provenientes do Azure Key Vault, insira o nome do segredo entre aspas duplas. Por exemplo, se o nome do segredo for cred1, insira "$(cred1)" para esse valor.
h. Selecione Incremental para o Modo de implantação.
Aviso
No modo de implantação completa, os recursos que estão no grupo de recursos, mas não estão especificados no novo modelo do Resource Manager, serão excluídos.
Salve o pipeline de lançamento.
Para disparar uma versão, selecione Criar versão. No Azure DevOps, isso pode ser automatizado.



Importante
Em cenários de CI/CD, o tipo de IR (runtime de integração) em ambientes diferentes deve ser o mesmo. Por exemplo, se você tiver um IR auto-hospedado no ambiente de desenvolvimento, o mesmo IR também deverá ser do tipo auto-hospedado em outros ambientes, como teste e produção. Da mesma forma, se você estiver compartilhando runtimes de integração em várias fases, será necessário configurar os runtimes de integração como auto-hospedados vinculados em todos os ambientes, como desenvolvimento, teste e produção.
Obter segredos do Azure Key Vault
Se você tiver segredos para passar em um modelo do Azure Resource Manager, recomendamos o uso do Azure Key Vault com a versão do Azure Pipelines.
Há duas maneiras de lidar cos segredos:
Adicione os segredos ao arquivo de parâmetros.
Crie uma cópia do arquivo de parâmetros carregado para o branch de publicação. Defina os valores dos parâmetros que você deseja obter do Key Vault usando este formato:
{ "parameters": { "azureSqlReportingDbPassword": { "reference": { "keyVault": { "id": "/subscriptions/<subId>/resourceGroups/<resourcegroupId> /providers/Microsoft.KeyVault/vaults/<vault-name> " }, "secretName": " < secret - name > " } } } }Quando você usa esse método, o segredo é extraído do cofre de chaves automaticamente.
O arquivo de parâmetros também deve estar no branch de publicação.
Adicione uma tarefa do Azure Key Vault antes da tarefa de Implantação do Azure Resource Manager descrita na seção anterior:
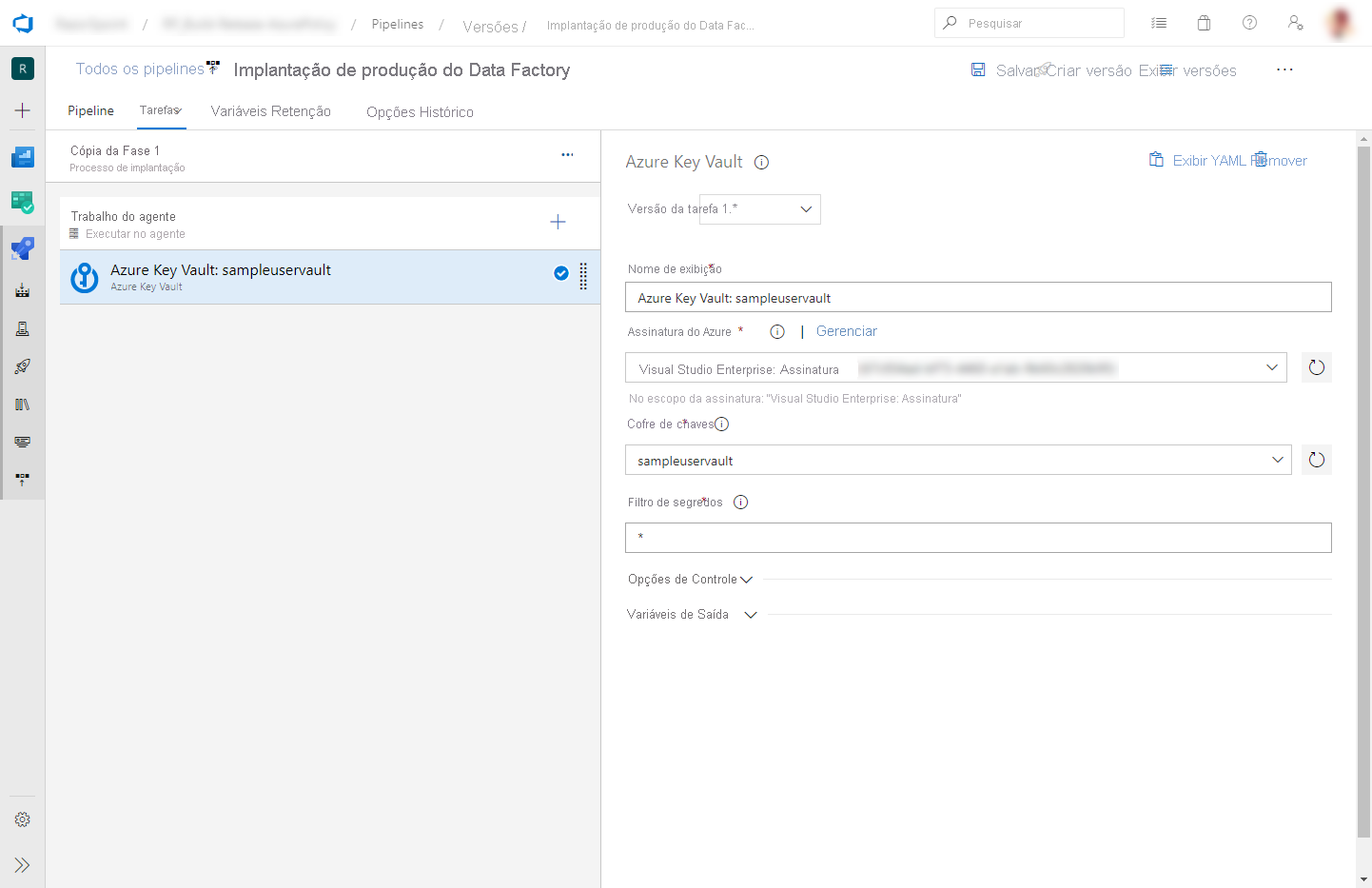
Na guia Tarefas, crie uma tarefa. Procure Azure Key Vault e adicione-o.
Na tarefa do Key Vault, selecione a assinatura na qual você criou o cofre de chaves. Forneça as credenciais, se necessário, e selecione o cofre de chaves.

Conceder permissões ao agente do Azure Pipelines
A tarefa do Azure Key Vault poderá falhar com um erro de Acesso Negado se as permissões corretas não estiverem definidas. Baixe os logs da versão e localize o arquivo .ps1 que contém o comando para conceder permissões ao agente do Azure Pipelines. Você pode executar o comando diretamente. Como alternativa, você pode copiar a ID de entidade de segurança do arquivo e adicionar a política de acesso manualmente no portal do Azure. Get e List são as permissões mínimas necessárias.
Atualizar gatilhos ativos
A implantação poderá falhar se você tentar atualizar gatilhos ativos. Para atualizar os gatilhos ativos, você precisa interrompê-los manualmente e iniciá-los após a implantação. Faça isso usando uma tarefa do Azure PowerShell:
Na guia Tarefas da versão, adicione uma tarefa do Azure PowerShell. Escolha a versão da tarefa 4.*.
Selecione a assinatura em que seu factory está.
Selecione Caminho do Arquivo de Script como o tipo de script. Isso exige que você salve o script do PowerShell em seu repositório. O seguinte script do PowerShell pode ser usado para parar gatilhos:
$triggersADF = Get-AzDataFactoryV2Trigger -DataFactoryName $DataFactoryName -ResourceGroupName $ResourceGroupName $triggersADF | ForEach-Object { Stop-AzDataFactoryV2Trigger -ResourceGroupName $ResourceGroupName -DataFactoryName $DataFactoryName -Name $_.name -Force }
Você pode concluir etapas semelhantes (com a função Start-AzDataFactoryV2Trigger) para reiniciar os gatilhos depois da implantação.
Observação
Essas etapas já estão incluídas nos scripts de pré e pós-implantação fornecidos pela equipe do Azure Data Factory
Promover manualmente um modelo do Resource Manager para cada ambiente
Se não for possível usar o Azure DevOps ou uma ferramenta de gerenciamento de versão diferente, você poderá promover manualmente um data factory usando um modelo do ARM.
Na lista do Modelo do ARM, selecione Exportar Modelo do ARM para exportar o modelo do Resource Manager para seu data factory no ambiente de desenvolvimento.

Em suas data factories de teste e produção, selecione Importar Modelo do ARM. Essa ação leva você até o Portal do Azure, onde você pode importar o modelo exportado. Selecione Criar seu modelo no editor para abrir o editor de modelo do Resource Manager.
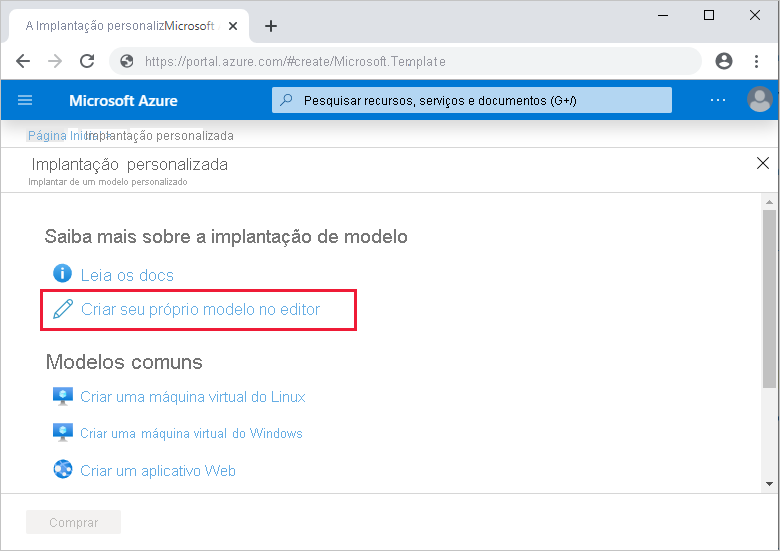
Select Carregar arquivo e, em seguida, selecione o modelo do Resource Manager gerado. Este é o arquivo arm_template.json localizado no arquivo .zip exportado na etapa 1.
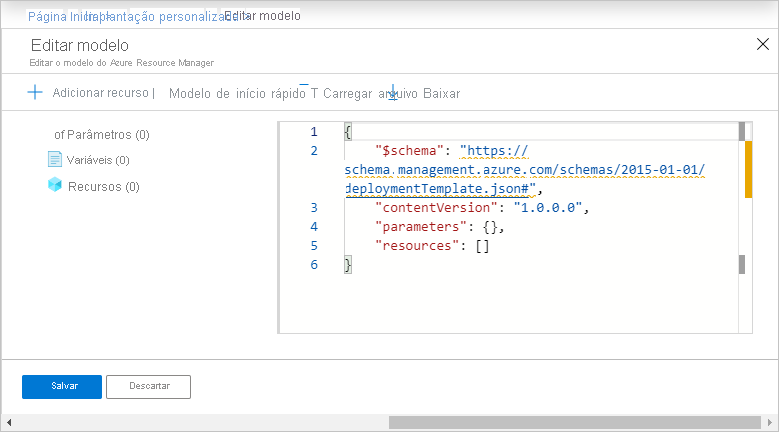
Na seção de configurações, insira os valores de configuração, como credenciais de serviço vinculado. Quando tiver terminado, selecione Comprar para implantar o modelo do Resource Manager.
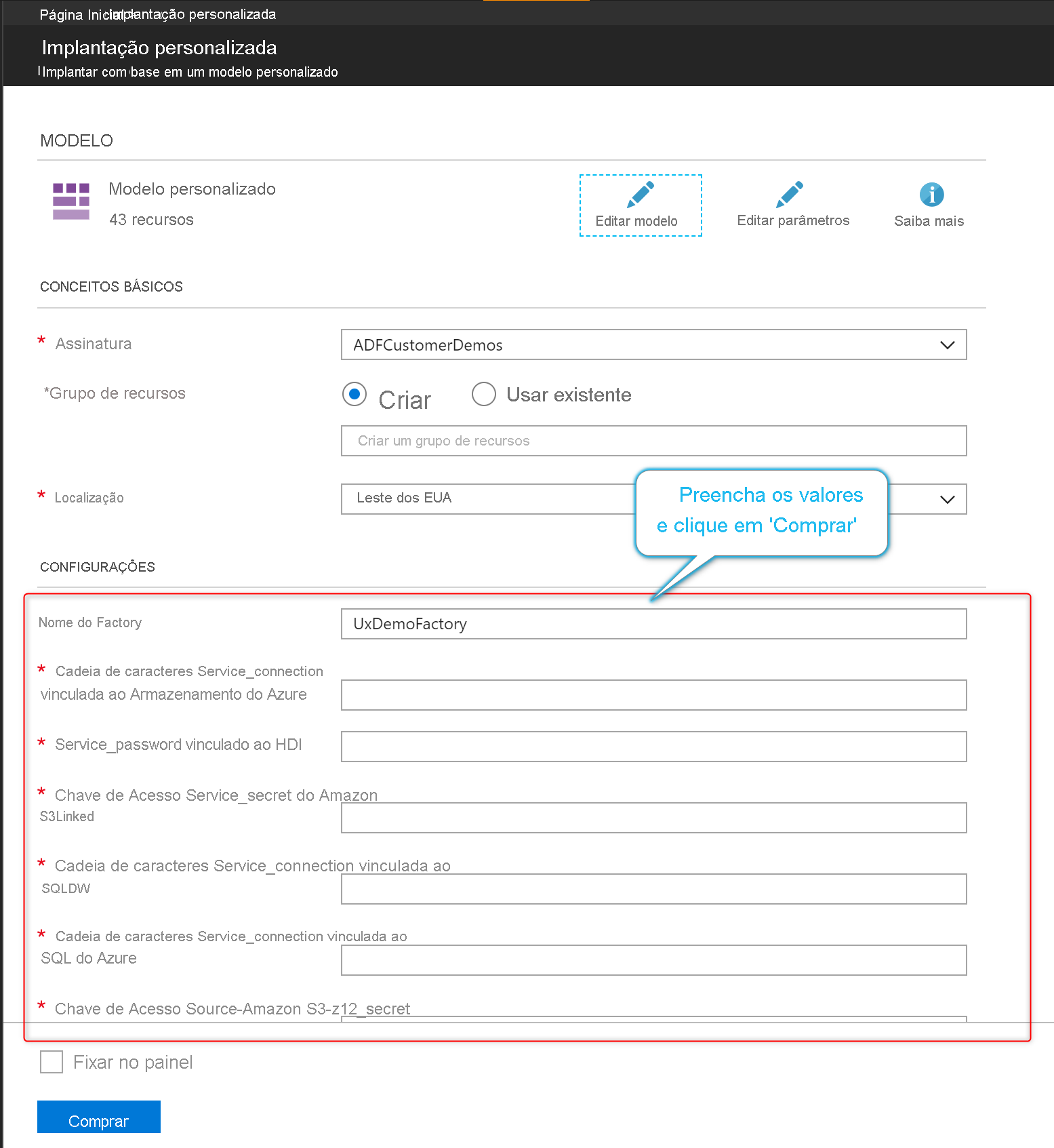
Personalizar parâmetros do modelo do Azure Resource Manager
Se o seu alocador de desenvolvimento tiver um repositório do git associado, você poderá substituir os parâmetros de modelo do Resource Manager padrão do modelo do Resource Manager gerado pela publicação ou exportação do modelo. Talvez seja interessante substituir o modelo de parametrização padrão nestes cenários:
- Você usa CI/CD automatizadas e deseja alterar algumas propriedades durante a implantação do Resource Manager, mas as propriedades não são parametrizadas por padrão.
- Seu alocador é tão grande que o modelo padrão do Resource Manager é inválido porque ele tem mais do que os parâmetros máximos permitidos (256).
Para substituir o modelo de parametrização padrão, vá para o hub de gerenciamento e selecione Modelo de parametrização na seção controle do código-fonte. Selecione Editar modelo para abrir o editor de código do modelo de parametrização.
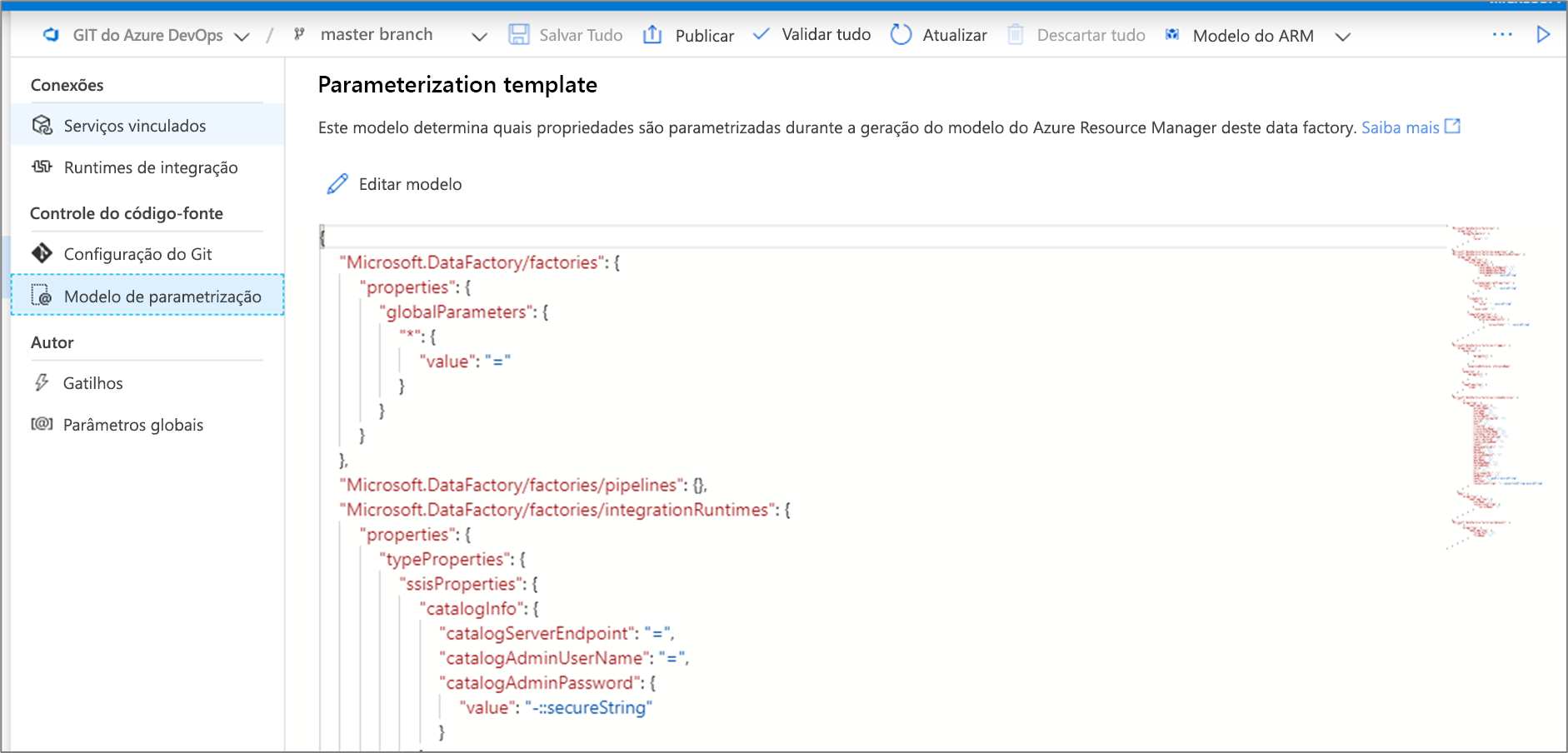
A criação de um modelo de parametrização personalizado gera um arquivo chamado arm-template-parameters-definition.json na pasta raiz do seu git branch. Você deve usar esse nome de arquivo exato.
Ao publicar do branch de colaboração, o Data Factory lerá esse arquivo e usará a configuração dele para gerar quais propriedades são parametrizadas. Se nenhum arquivo for encontrado, o modelo padrão será usado.
Ao exportar um modelo do Resource Manager, o Data Factory lê esse arquivo de qualquer branch no qual você está trabalhando no momento, não o branch de colaboração. Você pode criar ou editar o arquivo de um branch privado, no qual você pode testar suas alterações selecionando Exportar modelo do ARM na interface do usuário. Em seguida, você pode mesclar o arquivo no branch de colaboração.
Observação
Um modelo de parametrização personalizado não altera o limite de parâmetro do modelo do ARM de 256. Ele permite que você escolha e diminua o número de propriedades parametrizadas.
Sintaxe do parâmetro personalizado
Veja a seguir algumas diretrizes a serem seguidas ao criar o arquivo de parâmetros personalizados, arm-template-parameters-definition.json. O arquivo é composto por uma seção para cada tipo de entidade: gatilho, pipeline, serviço vinculado, conjunto de dados, runtime de integração e fluxo de dados.
- Insira o caminho da propriedade sob o tipo de entidade relevante.
- Definir um nome de propriedade como
*indica que você deseja parametrizar todas as propriedades sob ele (somente até o primeiro nível, não recursivamente). Você também pode fornecer exceções a essa configuração. - Definir o valor de uma propriedade como uma cadeia de caracteres indica que você deseja parametrizar a propriedade. Use o formato
<action>:<name>:<stype>.<action>pode ser um desses caracteres:=significa manter o valor atual como o valor padrão do parâmetro.-significa não manter o valor padrão do parâmetro.|é um caso especial para segredos do Azure Key Vault para cadeias de conexão ou chaves.
<name>é o nome do parâmetro. Se estiver em branco, será usado o nome da propriedade. Se o valor começar com um caractere-, o nome será abreviado. Por exemplo,AzureStorage1_properties_typeProperties_connectionStringseria abreviado comoAzureStorage1_connectionString.<stype>é o tipo de parâmetro. Se<stype>estiver em branco, o tipo padrão serástring. Os valores com suporte são:string,bool,number,objectesecurestring.
- Especificar uma matriz no arquivo de definição indica que a propriedade correspondente no modelo é uma matriz. O Data Factory itera todos os objetos na matriz usando a definição especificada no objeto do runtime de integração da matriz. O segundo objeto, uma cadeia de caracteres, torna-se o nome da propriedade, que é usada como o nome do parâmetro para cada iteração.
- Uma definição não pode ser específica a uma instância de recurso. Qualquer definição se aplica a todos os recursos desse tipo.
- Por padrão, todas as cadeias de caracteres seguras, como segredos do Key Vault, e cadeias de caracteres seguras, como cadeias de conexão, chaves e tokens, são parametrizadas.
Modelos vinculados
Se você tiver configurado o CI/CD para seus data factories, poderá exceder os limites de modelo do Azure Resource Manager à medida que sua fábrica aumentar. Por exemplo, um limite é o número máximo de recursos em um modelo do Resource Manager. Para acomodar alocadores maiores ao gerar o modelo completo do Resource Manager para um alocador, o Data Factory agora gera modelos do Resource Manager vinculados. Com esse recurso, todo o conteúdo do alocador é dividido em vários arquivos para que você não fique restrito pelos limites.
Se você configurou o Git, os modelos vinculados são gerados e salvos juntamente com os modelos completos do Resource Manager no branch adf_publish em uma nova pasta chamada linkedTemplates. Os modelos vinculados do Resource Manager geralmente são compostos por um modelo mestre e um conjunto de modelos filho vinculados ao mestre. O modelo pai é chamado de ArmTemplate_master.json e os modelos filho são nomeados com o padrão ArmTemplate_0.json, ArmTemplate_1.json e assim por diante.
Para usar modelos vinculados em vez do modelo completo do Resource Manager, atualize sua tarefa de CI/CD para apontar para o ArmTemplate_master.json em vez do ArmTemplateForFactory.json (o modelo completo do Resource Manager). O Resource Manager também requer que você carregue os modelos vinculados para uma conta de armazenamento para que o Azure possa acessá-los durante a implantação.
Ambiente de produção de hotfix
Se você implantar um alocador na produção e perceber que há um bug que precisa ser reparado imediatamente, mas você não conseguir implantar o branch de colaboração, talvez você precisará implantar um hotfix. Essa abordagem é conhecida como engenharia de correção rápida ou QFE.
No Azure DevOps, acesse a versão que foi implantada em produção. Localize a última confirmação implantada.
Na mensagem de confirmação, obtenha a ID de confirmação do branch de colaboração.
Crie um branch de hotfix com base nessa confirmação.
Acesse a UX do Azure Data Factory e alterne para o branch de hotfix.
Usando a UX do Azure Data Factory, corrija o bug. Teste suas alterações.
Depois que a correção for verificada, selecione Exportar Modelo do ARM para obter o modelo do Resource Manager de hotfix.
Verifique manualmente esse build no branch de publicação.
Se você tiver configurado o pipeline de lançamento para disparar automaticamente com base em check-ins do adf_publish, uma nova versão será iniciada automaticamente. Caso contrário, enfileire manualmente uma versão.
Implante a versão de hotfix nos alocadores de teste e produção. Essa versão contém o conteúdo de produção anterior e a correção que você fez na etapa 5.
Adicione as alterações do hotfix ao branch de desenvolvimento para que as versões posteriores não incluam o mesmo bug.
Práticas recomendadas para integração contínua/entrega contínua
Se você está usando a integração do Git ao seu data factory e tem um pipeline de CI/CD que migra suas alterações do desenvolvimento para o teste e para a produção, recomendamos estas melhores práticas:
Integração do Git. Configure somente seu data factory de desenvolvimento com a integração do Git. Alterações no teste e na produção são implantadas por CI/CD e não precisam da integração do Git.
Script pré e pós-implantação. Antes da etapa de implantação do Resource Manager na CI/CD, você precisa concluir determinadas tarefas, como parar e reiniciar gatilhos e executar a limpeza. Recomendamos que você use scripts do PowerShell antes e depois da tarefa de implantação. A equipe do data factory forneceu um script para uso localizado na página de documentação de CI/CD do Azure Data Factory.
Runtimes de integração e compartilhamento. Os runtimes de integração não são alterados com frequência e são semelhantes em todas as fases em sua CI/CD. Portanto, o Data Factory espera que você tenha o mesmo nome e tipo de runtime de integração em todas as fases da CI/CD. Se desejar compartilhar runtimes de integração em todas as fases, considere usar um alocador ternário apenas para conter os runtimes de integração compartilhados. Você pode usar esse alocador compartilhado em todos os seus ambientes como um tipo de runtime de integração vinculado.
Implantação do ponto de extremidade privado gerenciado. Se um ponto de extremidade privado já existir em uma fábrica e você tentar implantar um modelo do ARM que contenha um ponto de extremidade privado com o mesmo nome, mas com propriedades modificadas, a implantação falhará. Em outras palavras, você pode implantar com êxito um ponto de extremidade privado, contanto que ele tenha as mesmas propriedades daquele que já existe no alocador. Se alguma propriedade for diferente entre os ambientes, você poderá substituí-la parametrizando essa propriedade e fornecendo o respectivo valor durante a implantação.
Key Vault. Quando você usa serviços vinculados cujas informações de conexão são armazenadas no Azure Key Vault, é recomendável manter cofres de chaves separados para ambientes diferentes. Você também pode configurar níveis de permissão separados para cada cofre de chaves. Por exemplo, talvez você não queira que os membros da sua equipe tenham permissões para os segredos de produção. Se você seguir essa abordagem, recomendamos que você mantenha os mesmos nomes de segredo em todas as fases. Se você mantiver os mesmos nomes de segredo, não precisará parametrizar cada cadeia de conexão em ambientes de CI/CD porque a única coisa que é alterada é o nome do cofre de chaves, que é um parâmetro separado.
Nomeação de recursos Devido às restrições de modelo do ARM, poderão surgir problemas na implantação se os recursos contiverem espaços no nome. A equipe do Azure Data Factory recomenda usar caracteres ' _ ' ou '-', em vez de espaços para recursos. Por exemplo, 'Pipeline_1' seria um nome preferível a 'pipeline 1'.