Otimizar o sistema de origem – avançado
Essa orientação mais avançada pode ser útil para a exportação de origem de sistemas VLDB:
Divisão da tabela da ID de Linha do Oracle
A SAP lançou a Nota da SAP nº 1043380, contendo um script que com valor ROW ID. Como alternativa, as últimas versões do SAPInst geram automaticamente arquivos WHR divididos por ROW ID se SWPM estiver configurado para a migração do Oracle para Oracle R3load. Os arquivos STR e WHR gerados pelo SWPM são independentes do sistema operacional e do banco de dados (assim como todos os aspectos do processo de migração do SO/BD).
A nota OSS contém a instrução "A divisão da tabela ROWID NÃO PODERÁ ser usada se o banco de dados de destino for um banco de dados que não seja da Oracle". Tecnicamente, os arquivos de despejo R3load são independentes do banco de dados e do sistema operacional. No entanto, há uma restrição, a reinicialização de um pacote durante a importação não é possível no SQL Server. Nesse cenário, toda a tabela precisa ser descartada e todos os pacotes da tabela serão reiniciados. É sempre recomendável cancelar tarefas de R3load para uma tabela de divisão específica, usar TRUNCATE na tabela e reiniciar todo o processo de importação caso uma divisão R3load seja anulada. O motivo para isso é que o processo de recuperação integrado ao R3load envolve a execução de instruções DELETE linha por linha para remover os registros carregados pelo processo do R3load que foi anulado. Isso é lento e costuma causar situações de bloqueio/travamento no banco de dados. A experiência mostrou que é mais rápido iniciar a importação dessa tabela específica desde o início, portanto, a limitação mencionada na Nota da SAP nº 1043380 não é uma limitação.
O ROW ID tem uma desvantagem em que o cálculo das divisões deve ser feito durante o tempo de inatividade – confira a Nota da SAP nº 1043380.
Criar vários "clones" do banco de dados de origem e exportar em paralelo
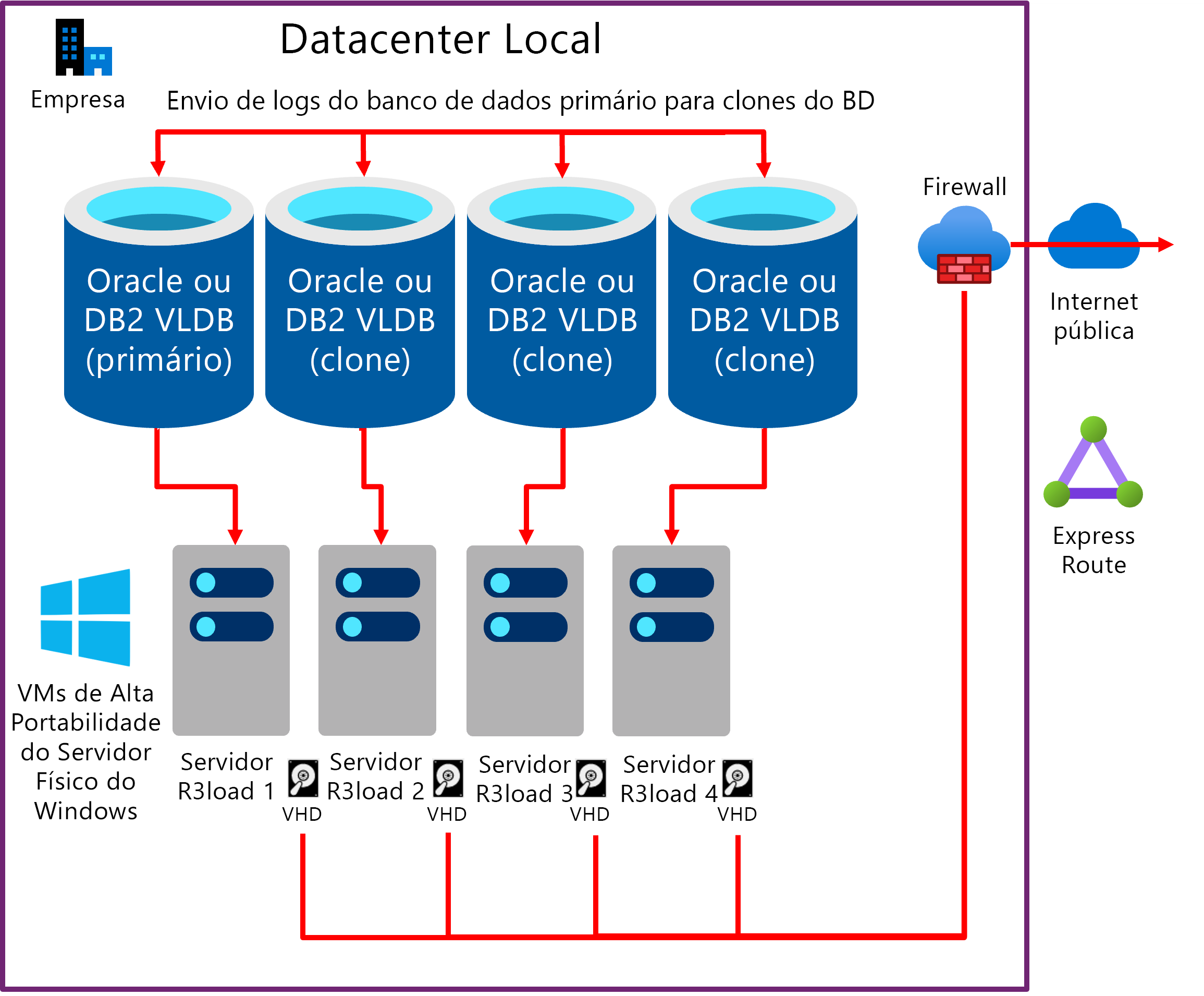
Um método para aumentar o desempenho da exportação é exportar de várias cópias do mesmo banco de dados. Se a infraestrutura subjacente, incluindo servidores, rede e armazenamento, for escalonável, essa abordagem tenderá a ser escalonável linearmente. A exportação de duas cópias do mesmo banco de dados é duas vezes mais rápida, quatro cópias é quatro vezes mais rápida. O Monitor de Migração está configurado para exportar em um número selecionado de tabelas de cada "clone" do banco de dados. No caso a seguir, a carga de trabalho de exportação é distribuída aproximadamente 25% em cada um dos quatro servidores de banco de dados.
- Servidor de BD 1 e servidor de exportação 1: dedicados às 1 a 4 maiores tabelas (dependendo de quão distorcida é a distribuição de dados no banco de dados de origem)
- Servidor de DB 2 e servidor de exportação 2: dedicado a tabelas com divisões de tabela
- Servidor de DB 3 e servidor de exportação 3: dedicado a tabelas com divisões de tabela
- Servidor de DB 4 e servidor de exportação 4: todas as tabelas restantes
É necessário ter muito cuidado para garantir que os bancos de dados sejam sincronizados com precisão, caso contrário, poderá ocorrer perda ou inconsistências de dados. Se as etapas fornecidas forem seguidas com precisão, a integridade dos dados será preservada.
A técnica é simples e barata com hardware Intel de mercadoria padrão, mas também é possível para clientes que executam hardware UNIX proprietário. Recursos substanciais de hardware são gratuitos no meio de um projeto de migração de SO/BD quando os sistemas de Área restrita, Desenvolvimento, QAS, Treinamento e DR já foram movidos para o Azure. Não há nenhum requisito estrito de que os servidores "clones" devem ter recursos de hardware idênticos. Com CPU, RAM, disco e desempenho de rede adequados, a adição de cada clone aumenta o desempenho.
Se o desempenho de exportação extra ainda for necessário, abra um incidente SAP no BC-DB-MSS para ver mais etapas a fim de aprimorar o desempenho da exportação (somente consultores avançados).
As etapas para implementar uma exportação paralela múltipla são as seguintes:
- Faça backup do banco de dados primário e restaure em "n" número de servidores (em que n = número de clones). Para este exemplo, suponha que n = 3 servidores que fazem um total de quatro servidores do BD.
- Restaure o backup em três servidores.
- Estabeleça o envio de logs do servidor do BD de origem primária para os três servidores "clones" de destino.
- Monitore o envio de logs por vários dias e verifique se o envio de logs está funcionando de maneira confiável.
- No início do tempo de inatividade, desative todos os servidores de aplicativos SAP, exceto o PAS. Verifique se todo o processamento em lotes e o tráfego RFC foram interrompidos.
- Na transação SM02, insira o texto "Ponto de verificação PAS em execução". Isso atualiza o TEMSG da tabela.
- Pare o Servidor de Aplicativos Primário. O SAP agora está desligado. Não pode ocorrer mais nenhuma atividade de gravação no BD de origem. Verifique se nenhum aplicativo não SAP está conectado ao BD de origem (nunca deve haver, mas verifique se há sessões não SAP no nível do BD).
- Execute esta consulta no servidor de BD Primário:
SELECT EMTEXT FROM [schema].TEMSG; - Execute a instrução de nível do DBMS nativo:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(a sintaxe exata depende do DBMS de origem. INSERT em EMTEXT) - Interrompa os backups automáticos de log de transações. Execute manualmente um backup final de log de transações no servidor de BD Primário. Verifique se o backup de log foi copiado nos servidores clones.
- Restaure o backup de log de transações final em todos os três nós.
- Recupere o banco de dados nos três nós "clones".
- Execute a seguinte instrução SELECT em todos os quatro nós:
SELECT EMTEXT FROM [schema].TEMSG; - Capture os resultados da tela da instrução SELECT para cada um dos quatro servidores do BD (o primário e os três clones). Lembre-se de incluir cuidadosamente cada nome de host, o que serve como uma prova de que o BD de clone e o primário são idênticos e contêm os mesmos dados do mesmo momento.
- Inicie export_monitor.bat em cada servidor de exportação Intel R3load.
- Inicie a cópia do arquivo de despejo para o processo do Azure (AzCopy ou Robocopy).
- Inicie import_monitor.bat nas Máquinas Virtuais do Azure do R3load.
O diagrama a seguir mostra um envio de log do servidor de BD de produção existente para os bancos de dados "clones". Cada servidor de BD tem um ou mais servidores Intel R3load.