Identificar opções de ferramenta de migração
Há muitas opções disponíveis para executar uma migração de um servidor PostgreSQL para o Servidor Flexível do Banco de Dados do Azure para PostgreSQL. Há ferramentas nativas do PostgreSQL, como pg_dump, pgadmin e pg_restore. Há serviços de nuvem do Microsoft Azure, como o Serviço de Migração de Banco de Dados e a opção de migração no Banco de Dados do Azure para PostgresSQL - Servidor Flexível, que pode automatizar em grande parte o processo geral de transferência de dados de origem para destino.
Servidor Flexível do Banco de Dados do Azure para PostgreSQL - migração
No serviço Banco de Dados do Azure para PostgreSQL - Servidor Flexível, há uma funcionalidade nativa para dar suporte à migração de bancos de dados de outras instâncias do PostgreSQL para o serviço baseado no Azure. Essa opção é voltada para a migração offline de bancos de dados de origem para destino. Para usar essa opção, precisamos usar as ferramentas pg_dumpall e psql discutidas anteriormente para migrar os bancos de dados de objetos de nível de servidor migrando para o servidor flexível.
Esse recurso foi projetado com instâncias externas do PostgreSQL como a origem e o Servidor Flexível no qual o projeto de migração foi criado como o destino. Essencialmente, para efetuar pull de dados para o servidor flexível. Os benefícios de usar esse serviço em vez de executar um processo manual de despejo e restauração é a natureza gerenciada da migração. Depois de configurado, ele monitora o processo para todas as tabelas que estão sendo migradas para o Servidor Flexível, para que possamos ver facilmente quando a migração no nível do aplicativo pode ser executada.
Projetos de Migração
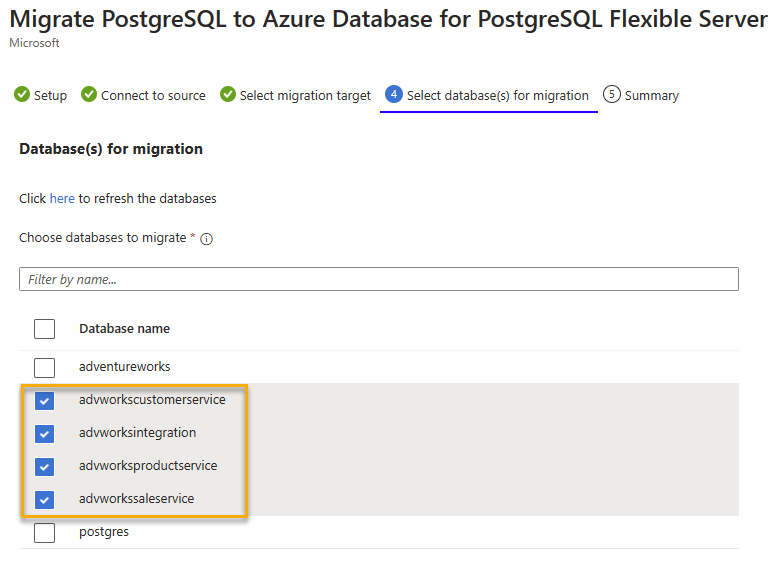
Depois que tivermos a conectividade classificada, tudo o que precisamos fazer é selecionar o banco de dados ou os bancos de dados que queremos migrar para o novo servidor. Na captura de tela a seguir, observe que, se houver vários bancos de dados que respaldam vários serviços que fazem parte de um sistema maior, podemos selecionar para migrá-los como um grupo em vez de um de cada vez. Esse agrupamento de banco de dados pode realmente ajudar não apenas a acelerar as migrações, mas também a manter a consistência lógica durante as atividades de migração.
Quando iniciamos o processo de validação e migração, podemos examinar o progresso geral do processo usando o painel do projeto. Este painel nos mostra como os bancos de dados são validados e, em seguida, como eles são migrados para o novo servidor.
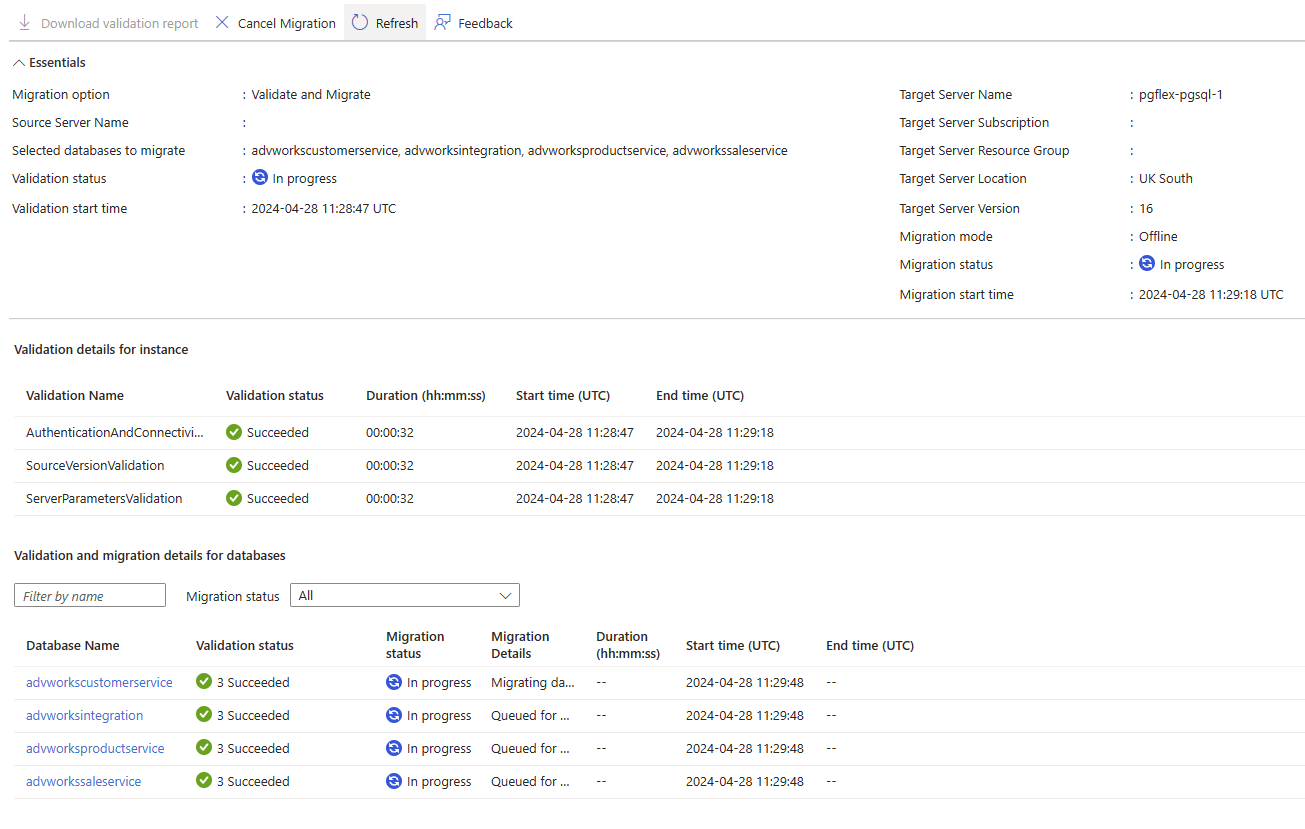
Essas informações serão retidas após a migração, permitindo que acompanhemos o progresso geral. As informações também fornecem qualquer evidência necessária para alterar os processos de controle sobre o sucesso e a duração de qualquer trabalho que seja realizado.
Ferramentas do PostgreSQL
Aqui, exploramos as principais ferramentas que podem ser usadas para migrar dados de um servidor PostgreSQL para o Servidor Flexível do Banco de Dados do Azure para PostgreSQL.
pgcopydb
Pgcopydb é um projeto de software livre que pode automatizar o processo de cópia de um banco de dados entre servidores PostgreSQL. Há vários benefícios em usar pgcopydb sobre as ferramentas nativas fornecidas ao instalar o PostgreSQL, incluindo esses benefícios.
- Removendo a necessidade de arquivos intermediários usando pg_backup e pg_restore.
- Crie a Simultaneidade de Índice para paralelizar a criação de índices em tabelas usando a funcionalidade synchronize__seqscans no PostgreSQL.
- Cópia de tabela com vários threads para dados de partição e transferência de tabelas maiores em paralelo.
- Captura de dados de alterações para sincronização de dados para minimizar a necessidade de janelas de tempo de inatividade prolongadas.
Há duas opções principais no pgcopydb que podem ser usadas para o banco de dados e a migração de dados de um servidor de origem para o destino. Essas opções são clonar e copiar.
pgcopydb clone
Clonar é a principal opção para copiar um banco de dados inteiro de um servidor de origem para um destino. Esse comando tem vários comutadores disponíveis que nos permitem configurar uma operação de clonagem básica para automatizar a configuração da captura de dados de alteração para sincronizar dados para minimizar o tempo de inatividade da migração. Também podemos especificar as opções para paralelizar a transferência de dados por tabela e opções de transferência paralela para tabelas, índices e objetos grandes.
pgcopydb copy
A cópia é uma opção que permite maior granularidade de controle quando se trata de migrar o banco de dados ou partes dele. Podemos usar essa opção de comando para escolher quais esquemas, tabelas, funções etc. serão transferidos de um banco de dados do servidor de origem para o servidor de destino e o banco de dados. Esse comando é útil nos cenários em que um banco de dados grande está sendo decomposto em menores como parte de uma atividade de migração de modernização de aplicativos. Como alternativa, uma atividade de migração de consolidação nos permite migrar o conteúdo de um banco de dados para esquemas dentro de outro.
Essas opções são apenas algumas das maneiras pelas quais o pgcopydb pode nos ajudar a melhorar o processo de migração de bancos de dados para o Servidor Flexível do Banco de Dados do Azure para PostgreSQL. Esse processo fornece uma maneira de migração que minimiza o risco e maximiza nossas chances de sucesso.
pgAdmin
pgAdmin é uma ferramenta de gerenciamento amplamente usada que pode ser usada para interagir com bancos de dados PostgreSQL. Essa ferramenta permite a criação e a execução de scripts pgsql. A ferramenta contém uma matriz de ferramentas de GUI úteis que podem ser usadas para configurar, fazer backup e restaurar bancos de dados PostgreSQL. Normalmente, instale o pgAdmin em estações de trabalho administrativas. Essa ferramenta possibilita registrar e se conectar a vários servidores PostgreSQL, tornando-a uma parte fundamental do conjunto de ferramentas de migração.
pg_dump, pg_restore e psql
pg_dump é uma ferramenta de linha de comando instalada junto com uma instância do PostgreSQL e pode ser instalada conforme necessário em uma estação de trabalho administrativa. Ela permite a criação de backups de banco de dados consistentes do PostgreSQL mesmo quando há uma carga de trabalho simultânea ocorrendo. Ela funciona com bancos de dados individuais e nos permite fazer backup de um banco de dados inteiro ou partes dele.
Se estiver usando pg_dump para exportar objetos de esquema, poderemos usar psql para executar o arquivo .sql resultante no banco de dados de destino para criar os objetos. Após essa etapa, podemos examinar maneiras de mover os dados da origem para o sistema de destino. Os comandos a serem usados para exportar um esquema de banco de dados de um banco de dados e criá-lo em outro podem ser vistos no exemplo a seguir.
pg_dump -O --host=MyServerName --port=5432 --username=adminuser --dbname=AdventureWorks --schema-only > adventureWorks.sql
psql --host=MyFlexibleServer --username=demo --dbname=AdventureWorks < adventureWorks.sql
Se estivermos criando um despejo completo do banco de dados de origem, procuraremos usar pg_restore para ler o arquivo resultante e restaurar o banco de dados para a instância PostgreSQL de destino. Há vários fatores determinantes para quanto tempo essas atividades levam ao executar um backup e restaurar o despejo. Notavelmente o tamanho do banco de dados, o desempenho do subsistema de armazenamento e a largura de banda de rede e latência entre os componentes de processamento.
O exemplo a seguir mostra como podemos criar um despejo de banco de dados em um personalizado e restaurá-lo para outro servidor.
pg_dump -Fc --host=MyServerName --port=5432 --username=adminuser --dbname=AdventureWorks > db.dump
pg_restore -Fc --host=MyServerName --port=5432 --create --username=adminuser --dbname=AdventureWorks db.dump
pg_dumpall
Enquanto pg_dump é usado para despejar um banco de dados individual, pg_dumpall é usado para despejar todos os bancos de dados em um único arquivo de script que o psql lê em uma nova instância do PostgreSQL.
Além disso, pg_dumpall podem ser usados para gerar arquivos de script para objetos de nível de servidor global, como funções das quais os bancos de dados podem depender ao serem migrados entre servidores.