Configurar o armazenamento e os bancos de dados
Geralmente, parte do processo de implantação requer que você se conecte a bancos de dados ou serviços de armazenamento. Esta conexão pode ser necessária para aplicar um esquema de banco de dados, para adicionar alguns dados de referência a uma tabela de banco de dados ou para carregar alguns blobs. Nesta unidade, você aprenderá como estender seu pipeline para trabalhar com serviços de dados e armazenamento.
Configurar seus bancos de dados de um pipeline
Muitos bancos de dados têm esquemas, que representam a estrutura dos dados contidos no banco de dados. Geralmente, é uma boa prática aplicar um esquema ao banco de dados do pipeline de implantação. Essa prática ajuda a garantir que tudo de que a sua solução precisa seja implantado junto. Ele também garante que, se houver um problema quando o esquema for aplicado, o pipeline exibirá um erro. O erro permite que você corrija o problema e reimplante.
Ao trabalhar com o SQL do Azure, você precisa aplicar esquemas de banco de dados conectando-se ao servidor de banco de dados e executando comandos usando scripts SQL. Esses comandos são operações do plano de dados. Seu pipeline precisa se autenticar no servidor de banco de dados e então executar os scripts. O Azure Pipelines fornece a tarefa SqlAzureDacpacDeployment que pode se conectar a um servidor do banco de dados SQL do Azure e executar comandos.
Alguns outros serviços de armazenamento e dados não precisam ser configurados usando uma API de plano de dados. Por exemplo, quando você trabalha com o Azure Cosmos DB, armazena seus dados em um contêiner. Você pode configurar seus contêineres usando o plano de controle dentro do arquivo Bicep. Da mesma forma, você pode implantar e gerenciar a maioria dos aspectos dos contêineres de blob do Armazenamento do Azure no Bicep. No próximo exercício, você verá um exemplo de como criar um contêiner de blob com base no Bicep.
Adicionar dados
Muitas soluções exigem que os dados de referência sejam adicionados aos seus bancos de dados ou contas de armazenamento antes de eles funcionarem. Os pipelines podem ser um bom lugar para adicionar esses dados. Depois que o pipeline for executado, seu ambiente estará totalmente configurado e pronto para ser usado.
Também é útil ter dados de amostra em seus bancos de dados, especialmente para ambientes de não produção. Os dados de exemplo ajudam os testadores e outras pessoas que usam esses ambientes a testar a solução imediatamente. Esses dados podem incluir produtos de exemplo ou itens como contas de usuário falsas. Em geral, você não deseja adicionar esses dados ao seu ambiente de produção.
A abordagem usada para adicionar dados depende do serviço que você usa. Por exemplo:
- Para adicionar dados a um banco de dados SQL do Azure, você precisa executar um script, assim como a configuração de um esquema.
- Para inserir dados em um Azure Cosmos DB, você precisa acessar sua API de plano de dados, o que pode exigir que você escreva algum código de script personalizado.
- Para carregar blobs em um contêiner de blobs do Armazenamento do Azure, você pode usar várias ferramentas de scripts de pipeline, incluindo o aplicativo de linha de comando AzCopy, o Azure PowerShell ou a CLI do Azure. Cada uma dessas ferramentas compreende como se autenticar no Armazenamento do Azure em seu nome e como se conectar à API do plano de dados para carregar blobs.
Idempotência
Uma das características dos pipelines de implantação e da infraestrutura como código é que você deve ser capaz de reimplantar repetidamente sem nenhum efeito colateral adverso. Por exemplo, quando você reimplanta um arquivo Bicep implantado anteriormente, o Azure Resource Manager compara o arquivo enviado com o estado existente dos seus recursos do Azure. Se não houver alterações, o Resource Manager não fará nada. A capacidade de executar uma operação repetidamente é chamada de idempotência. É uma boa prática verificar se os scripts e outras etapas de pipeline são idempotentes.
A Idempotência é especialmente importante quando você interage com os serviços de dados, pois eles mantêm o estado. Imagine que você está inserindo um usuário de exemplo em uma tabela de banco de dados de seu pipeline. Se você não tomar cuidado, toda vez que executar o pipeline, um novo usuário de amostra será criado. Esse resultado provavelmente não é o que você deseja.
Ao aplicar esquemas a um banco de dados SQL do Azure, você pode usar um pacote de dados, também chamado de arquivo DACPAC, para implantar seu esquema. Seu pipeline compila um arquivo DACPAC usando o código-fonte e cria um artefato de pipeline, assim como com um aplicativo. Em seguida, a fase de implantação em seu pipeline publica o arquivo DACPAC no banco de dados:
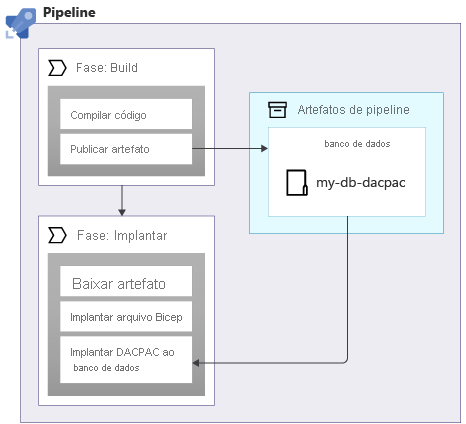
Quando um arquivo DACPAC é implantado, ele se comporta de maneira idempotente. Ele compara o estado de destino do seu banco de dados com o estado definido no pacote. Em muitas situações, isso significa que você não precisa escrever scripts que seguem o princípio da idempotência, pois as ferramentas processam isso para você. Algumas das ferramentas para o Azure Cosmos DB e o Armazenamento do Azure também se comportam corretamente.
Porém, quando você cria dados de amostra em um banco de dados SQL do Azure ou em outro serviço de armazenamento, isso não funciona automaticamente de forma idempotente. É uma boa prática escrever seu script de modo que ele crie os dados somente se eles ainda não existirem.
Também é importante considerar se pode ser necessário reverter implantações, por exemplo, executando novamente uma versão mais antiga de um pipeline de implantação. A reversão de alterações em seus dados pode se tornar complicada, portanto, considere cuidadosamente como sua solução funciona se for necessário reverter.
Segurança de rede
Às vezes, você pode aplicar restrições de rede a alguns de seus recursos do Azure. Essas restrições podem impor regras sobre solicitações feitas ao plano de dados de um recurso, como:
- Esse servidor de banco de dados só pode ser acessado de uma lista especificada de endereços IP.
- Essa conta de armazenamento está acessível apenas de recursos implantados em uma rede virtual específica.
As restrições de rede são comuns com bancos de dados, pois pode parecer que não há necessidade de que nada na Internet se conecte a um servidor de banco de dados.
No entanto, as restrições de rede também podem dificultar o trabalho dos pipelines de implantação com os planos de dados dos recursos. Quando você usa um agente de pipeline hospedado pela Microsoft, seu endereço IP não pode ser facilmente conhecido com antecedência e pode ser atribuído de um grande pool de endereços IP. Além disso, os agentes de pipeline hospedados pela Microsoft não podem ser conectados às próprias redes virtuais.
Algumas das tarefas de Azure Pipelines que ajudam a executar operações de plano de dados podem solucionar esses problemas. Por exemplo, a tarefa SqlAzureDacpacDeployment:
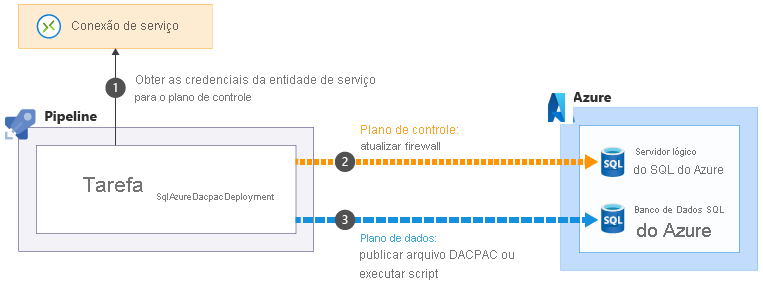
Quando você usa a tarefa SqlAzureDacpacDeployment para trabalhar com um servidor lógico ou banco de dados do SQL do Azure, ele usa a entidade de serviço do pipeline para se conectar ao plano de controle para o servidor lógico SQL do Azure. Ele atualiza o firewall para permitir que o agente de pipeline acesse o servidor de seu endereço IP
para se conectar ao plano de controle para o servidor lógico SQL do Azure. Ele atualiza o firewall para permitir que o agente de pipeline acesse o servidor de seu endereço IP . Em seguida, ele pode enviar com êxito o arquivo ou script DACPAC para execução
. Em seguida, ele pode enviar com êxito o arquivo ou script DACPAC para execução . A tarefa remove automaticamente a regra de firewall quando é concluída.
. A tarefa remove automaticamente a regra de firewall quando é concluída.
Em outras situações, não é possível criar esse tipo de exceções. Nessas circunstâncias, considere usar um agente de pipeline auto-hospedado, que é executado em uma máquina virtual ou em outro recurso de computação que você controla. Você pode configurar esse agente como precisar. Ele pode usar um endereço IP conhecido ou ser conectado à sua rede virtual. Não discutimos agentes auto-hospedados neste módulo, mas fornecemos links para mais informações sobre a página Resumo no final do módulo.
Seu pipeline de implantação
No próximo exercício, você atualizará seu pipeline de implantação para adicionar novos trabalhos para criar os componentes do banco de dados do seu site, implantar o banco de dados e adicionar dados de semente:
