Otimizar o desempenho de uma solução da Pesquisa de IA do Azure
O desempenho das soluções de pesquisa pode ser afetado pelo tamanho e pela complexidade dos índices. Você também precisa saber como escrever consultas eficientes para pesquisar nelas e como escolher a camada de serviço correta.
Aqui, você vai explorar todas essas dimensões e ver as etapas que pode executar para aprimorar o desempenho da solução de pesquisa.
Medir o desempenho de pesquisa atual
Você não pode otimizar quando não conhece o desempenho do serviço de pesquisa. Crie um parâmetro de comparação de desempenho de linha de base para que você possa validar as melhorias que fizer, além de verificar se há degradação no desempenho ao longo do tempo.
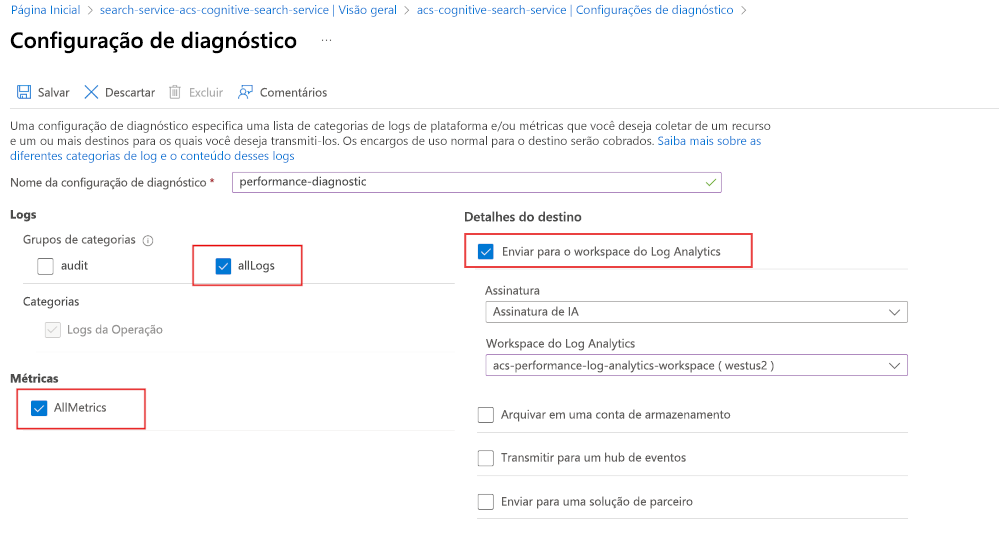
Para começar, habilite o log de diagnósticos usando o Log Analytics:
- No portal do Azure, selecione Configurações de diagnóstico.
- Selecione + Adicionar configurações de diagnóstico.

- Dê um nome à sua configuração de diagnóstico.
- Selecione allLogs e AllMetrics.
- Selecione Enviar para o workspace do Log Analytics.
- Escolha ou crie seu workspace do Log Analytics.
É importante capturar as informações de diagnóstico no nível do serviço de pesquisa. Há vários locais em que os usuários finais ou aplicativos podem encontrar problemas de desempenho.

Se você puder provar que o serviço de pesquisa tem um bom desempenho, poderá eliminá-lo dos possíveis fatores caso esteja passando por problemas de desempenho.
Verificar se o serviço de pesquisa foi limitado
As pesquisas e os índices da Pesquisa de IA do Azure podem ser limitados. Se seus usuários ou aplicativos estiverem tendo as respectivas pesquisas limitadas, isso será capturado no Log Analytics com uma resposta HTTP 503. Se os índices estiverem sendo limitados, eles aparecerão como respostas HTTP 207.
Essa consulta que você pode executar nos logs do serviço de pesquisa mostra se o serviço de pesquisa está sendo limitado.

No portal do Azure, em Monitoramento, selecione Logs. Na guia Nova Consulta 1, você usaria esta consulta:
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
Execute o comando para ver um gráfico de barras das respostas HTTP dos serviços de pesquisa. Acima, você pode ver que houve várias respostas 503.
Verificar o desempenho de consultas individuais
A melhor maneira de testar o desempenho da consulta individual é com uma ferramenta de cliente, como o Postman. Você pode usar qualquer ferramenta que mostre os cabeçalhos na resposta de uma consulta. A Pesquisa de IA do Azure sempre retornará um valor de “tempo decorrido” equivalente ao tempo que o serviço levou para concluir a consulta.

Se você quiser saber quanto tempo levaria para enviar e receber a resposta do cliente, subtraia o tempo decorrido da viagem de ida e volta total. Acima, seria 125 ms - 21 ms, resultando em 104 ms.
Otimizar o tamanho e o esquema do índice
O desempenho das consultas de pesquisa está diretamente conectado ao tamanho e à complexidade dos índices. Quanto menores e mais otimizados os índices, mais rapidamente a Pesquisa de IA do Azure poderá responder a consultas. Veja algumas dicas que podem ajudar se você descobriu que tem problemas de desempenho em consultas individuais.
Se você não prestar atenção, os índices poderão crescer ao longo do tempo. Examine se todos os documentos no índice ainda são relevantes e precisam ser pesquisáveis.
Se não pode remover nenhum documento, você pode reduzir a complexidade do esquema? Você ainda precisa que os mesmos campos sejam pesquisáveis? Você ainda precisa de todos os conjuntos de habilidades com os quais iniciou o índice?

Considere revisar todos os atributos que você habilitou em cada campo. Por exemplo, adicionar suporte para filtros, facetas e classificação pode quadruplicar o armazenamento necessário para dar suporte ao índice.
Observação
Ter muitos atributos em um campo limita sua capacidade. Por exemplo, em um campo facetável, filtrável e pesquisável, você só pode armazenar 16 KB. Enquanto um campo pesquisável pode conter até 16 MB de texto.
Se o índice tiver sido otimizado, mas o desempenho ainda não estiver onde precisa estar, você poderá optar por escalar verticalmente ou horizontalmente o serviço de pesquisa.
Aprimorar o desempenho do das consultas
Se você sabe como o serviço de pesquisa funciona, pode ajustar suas consultas para aprimorar drasticamente o desempenho. Use esta lista de verificação para escrever consultas melhores:
- Especifique apenas os campos que você precisa pesquisar usando o parâmetro searchFields. Ter mais campos exige processamento extra.
- Retorne o menor número de campos que você precisa renderizar na página de resultados da pesquisa. Retornar mais dados leva mais tempo.
- Tente evitar termos de pesquisa parciais, como pesquisa de prefixo ou expressões regulares. Esses tipos de pesquisas são mais caros em termos de computação.
- Evite usar valores altos de nível hierárquico. Isso força o mecanismo de pesquisa a recuperar e classificar volumes maiores de dados.
- Limite o uso de campos facetáveis e filtráveis para dados de baixa cardinalidade.
- Use funções de pesquisa em vez de valores individuais nos critérios de filtro. Por exemplo, você pode usar
search.in(userid, '123,143,563,121',',')em vez de$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121.
Se você aplicou tudo o que foi indicado acima e ainda tem consultas individuais que não são executadas, pode escalar horizontalmente o índice. Dependendo da camada de serviço usada para criar a solução de pesquisa, você pode adicionar até 12 partições. Partições são o armazenamento físico em que o índice reside. Por padrão, todos os índices de pesquisa novos são criados com uma partição. Se você adicionar mais partições, o índice será armazenado entre elas. Por exemplo, se o índice for de 200 GB e você tiver quatro partições, cada partição conterá 50 GB do índice.
Adicionar partições extra pode ajudar com o desempenho, pois o mecanismo de pesquisa pode ser executado em paralelo em cada partição. Os melhores aprimoramentos são observado em consultas que retornam um grande número de documentos e em consultas que usam facetas que fornecem contagens de um grande número de documentos. Esse é um fator que define quão computacionalmente caro é pontuar a relevância dos documentos.
Usar a melhor camada de serviço para as necessidades de pesquisa
Você viu que pode escalar horizontalmente as camadas de serviço adicionando mais partições. Você poderá escalar horizontalmente com réplicas se precisar escalar devido a um aumento na carga. Você também pode escalar verticalmente o serviço de pesquisa usando uma camada mais alta.

Os dois índices de pesquisa acima têm 200 GB de tamanho. A camada S1 está usando oito partições e a camada S2 tem apenas duas. Ambas têm duas réplicas e ambas custariam aproximadamente a mesma coisa. Escolher a melhor camada para a solução de pesquisa exige que você conheça o tamanho total aproximado do armazenamento de que precisará. O maior índice com suporte atualmente é de 12 partições na camada L2, oferecendo um total de 24 TB.
| Camada | Tipo | Armazenamento | Réplicas | Partições |
|---|---|---|---|---|
| F | Gratuita | 50 MB | 1 | 1 |
| B | Basic | 2 GB | 3 | 1 |
| S1 | Standard | 25 GB/partição | 12 | 12 |
| S2 | Standard | 100 GB/partição | 12 | 12 |
| S3 | Standard | 200 GB/partição | 12 | 12 |
| S3HD | Alta densidade | 200 GB/partição | 12 | 3 |
| L1 | Otimizado para armazenamento | 1 TB/partição | 12 | 12 |
| L2 | Otimizado para armazenamento | 2 TB/partição | 12 | 12 |
Qual das duas camadas no exemplo acima você acha que tem o melhor desempenho? Você viu que a colocação em escala oferece benefícios de desempenho devido ao paralelismo. No entanto, as camadas mais altas também vêm com armazenamento Premium, recursos de computação mais avançados e memória extra. Escolher a segunda opção oferece uma infraestrutura mais eficiente e permite o crescimento futuro do índice. Infelizmente, a camada que tem melhor desempenho depende do tamanho e da complexidade do índice e das consultas que você escreve para pesquisá-lo. Então, qualquer uma poderia ser a melhor.
Planejar o crescimento futuro do uso da solução de pesquisa significa que você deve considerar unidades de pesquisa. Uma SU (unidade de pesquisa) é o produto de réplicas e partições. Isso significa que a camada S1 acima está usando 16 SUs e a camada S2 usa apenas 4 SUs. Os custos são semelhantes, pois as camadas mais altas cobram mais por SU.
Pense na necessidade de dimensionar a solução de pesquisa devido ao aumento da carga. Adicionar outra réplica a ambas as camadas aumenta a camada S1 para 24 SUs, mas a camada S2 aumenta para apenas 6 SUs.