Exercício – Visualizar o modelo de machine learning
Um dos benefícios de usar um classificador de árvore de decisão é a visualização que você pode usar para entender melhor como o modelo toma decisões. Usando graphviz e pydotplus, é possível ver rapidamente como uma decisão é tomada. Em iterações futuras, é possível ver como as decisões são alteradas.
Criar a árvore visual
Para criar uma representação visual do modelo, você criará uma função que usa como parâmetros:
- Dados:
tree- O modelo de machine learning - Colunas:
feature_names- Uma lista das colunas nos dados de entrada - Saída:
class_names- Uma lista das opções de classificação (nesse caso, sim ou não) - Nome do arquivo:
png_file_to_save- O nome do arquivo em que você deseja salvar a visualização
Você chamará a função export_graphviz() scikit-learn's e retornará uma representação gráfica do gráfico que o scikit-learn fornece.
# Let's import a library for visualizing our decision tree.
from sklearn.tree import export_graphviz
def tree_graph_to_png(tree, feature_names,class_names, png_file_to_save):
tree_str = export_graphviz(tree, feature_names=feature_names, class_names=class_names,
filled=True, out_file=None)
graph = pydotplus.graph_from_dot_data(tree_str)
return Image(graph.create_png())
Chamar essa função é razoavelmente simples:
- Dados:
tree_model- O modelo que você treinou e testou anteriormente - Colunas:
X.columns.values- A lista de colunas na entrada - Saída: [
yes,no] - Os dois resultados possíveis - Nome do arquivo:
decision_tree.png- O nome do arquivo em que você deseja salvar a imagem
# This function takes a machine learning model and visualizes it.
tree_graph_to_png(tree=tree_model, feature_names=X.columns.values,class_names=['No Launch','Launch'], png_file_to_save='decision-tree.png')
Essa função cria a imagem a seguir.
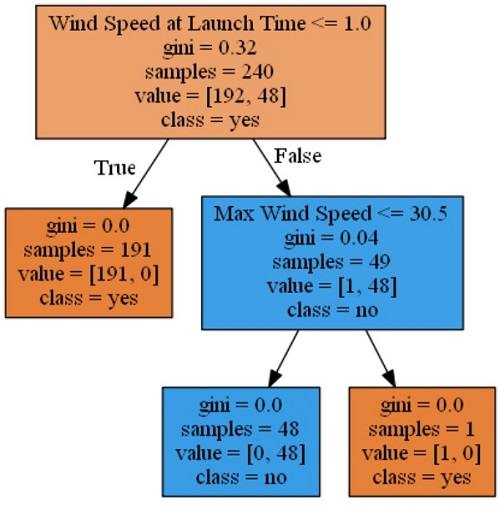
Em geral, quando analisamos o conjunto de dados, temos 240 amostras:
- 192 são não lançamentos
- 48 são lançamentos
Esse resultado é devido à nossa estratégia de limpeza de dados, nela supomos que todos os dias não rotulados são dias sem lançamento.
Usando os novos rótulos, podemos dizer: "se a velocidade do vento era menor que 1,0, 191 das 240 amostras estimaram que nenhum lançamento era possível naquele dia".
Esse resultado pode parecer estranho, porém ele é adequado de acordo com os dados. Veja a evidência:
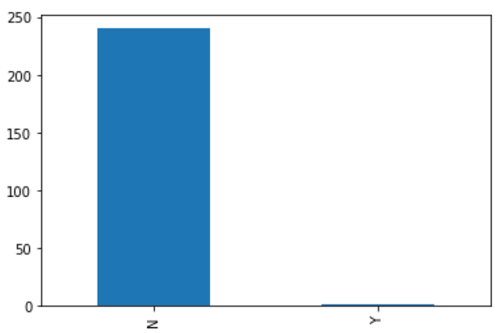
Plotamos a distribuição de lançamento versus não lançamento para os dias em que a Velocidade do Vento no Horário de Lançamento <= 1 antes de remover a coluna anteriormente neste notebook. Isso mostra que quase sempre não há lançamentos:
Entender a visualização
Essa árvore simples mostra que o recurso mais importante dos dados era Wind Speed at Launch Time. Se a velocidade do vento fosse menor que 1,0, 191 das 240 amostras teriam sido estimadas corretamente como não lançamento. Vemos que 191 dessas amostras precisavam apenas que o valor de Wind Speed at Launch Time fosse menor que 1,0 para adivinhar corretamente o resultado, enquanto um valor acima 1,0 exigia mais informações.
Esse insight não é bom. Anteriormente, definimos todos os valores que estavam vazios como 0. Também sabemos que muitos dos valores relacionados ao horário do lançamento eram 0 porque 60% dos nossos dados não estavam relacionados a um lançamento ou tentativa de lançamento real.
Ao continuar a examinar a árvore, é possível ver que Max Wind Speed é o próximo recurso mais importante dos dados. Aqui é possível conferir que dos 49 dias restantes em que a velocidade máxima do vento era menor do que 30,5, 48 dias geraram uma saída de lançamento adequada e um deles gerou uma saída sem lançamentos.
Esses dados podem ser mais interessantes com algum contexto do mundo real. Havia apenas um dia em que um lançamento foi planejado e o valor de Max Wind Speed era maior que 30,5, que foi em 27 de maio de 2020. O lançamento do Space X Dragon foi então adiado para 30 de maio de 2020. Veja a evidência:
launch_data[(launch_data['Wind Speed at Launch Time'] > 1) & (launch_data['Max Wind Speed'] > 30.5)]

Aprimorar os resultados
Com essa visualização, você percebeu que alguns atributos se tornaram importantes, mas esse destaque foi baseado em informações incorretas.
Uma melhoria que poderíamos fazer é determinar a relação entre Max Wind Speed e Wind Speed at Launch Time para as linhas que têm essa informação. Então, em vez de tornar Wind Speed at Launch Time 0 para os dias sem lançamento, poderíamos ter feito uma estimativa do que seria em um horário de lançamento comum. Essa alteração poderia ter representado melhor os dados.
Você consegue imaginar outras maneiras de aprimorar os dados?