Funções de custo versus métricas de avaliação
Nas últimas unidades, começamos a ver uma divisão nas funções de custo, que ensina o modelo, e as métricas de avaliação, que é a forma como avaliamos o modelo nós mesmos.
Todas as funções de custo podem ser métricas de avaliação
Todas as funções de custo podem ser métricas de avaliação, embora não necessariamente intuitivas. Perda de log, por exemplo: os valores não são intuitivos.
Algumas métricas de avaliação não podem ser funções de custo
- É difícil para algumas métricas de avaliação se tornarem funções de custo
- Isso ocorre devido a restrições matemáticas e práticas
- Às vezes, as coisas não são fáceis de serem calculadas (por exemplo, "o quão canino algo é")
- As funções de custo são idealmente suaves. Por exemplo, a precisão é útil, mas se alterarmos um pouco nosso modelo, isso passará despercebido. Considerando que o ajuste é um procedimento com diversas alterações pequenas, isso dá a impressão de que as alterações não resultarão em um aprimoramento.
- Grafo de função de custo com muitos bits simples
- Atualize as curvas ROC de antes. Isso requer alterar o limite para todos os tipos de valores, mas, no final do dia, nosso modelo terá apenas um (0,5)
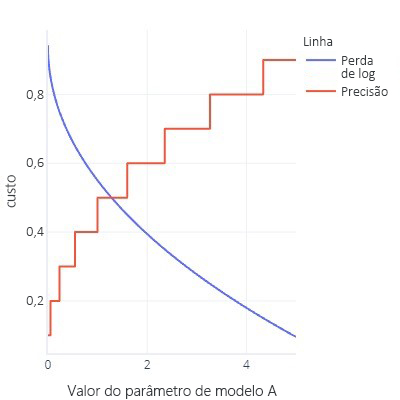
Não é tão ruim!
Pode ser frustrante descobrir que não podemos usar as métricas favoritas como uma função de custo. No entanto, há uma vantagem relacionada ao fato de que todas as métricas são simplificações do que queremos alcançar: nenhuma é perfeita. Isso significa que modelos complexos costumam "trapacear": eles encontram uma forma de obter custos baixos sem realmente encontrar uma regra que resolva nosso problema. Ter uma métrica que não está funcionando como a função de custo nos fornece uma "verificação de integridade" de que o modelo não encontrou uma forma de trapacear. Se sabemos que um modelo está tomando atalhos, podemos repensar nossa estratégia de treinamento.
Já vimos esta "trapaça" algumas vezes agora. Por exemplo, quando os modelos sobreajustam totalmente os dados de treinamento, eles estão, basicamente, "memorizando" as respostas corretas em vez de encontrar uma regra que podemos aplicar com sucesso aos outros dados. Usamos conjuntos de dados de teste como a "verificação de integridade" para avaliar se o modelo apenas não acabou de fazer isso. Também vimos que, com os dados desbalanceados, os modelos às vezes podem aprender a sempre dar a mesma resposta (como "false") sem analisar os recursos, porque normalmente isso está correto e apresenta uma pequena margem de erro.
Modelos complexos também encontram atalhos de outras maneiras. Às vezes, modelos complexos podem sobreajustar a própria função de custo. Por exemplo, imagine que estamos tentando criar um modelo que possa desenhar cachorros. Temos uma função de custo que verifica se a imagem é marrom, mostra uma textura peluda e contém um objeto do tamanho correto. Com essa função de custo, um modelo complexo pode aprender a criar uma bola de pelos marrom, não porque ela se parece com um cachorro, mas porque oferece um baixo custo e é fácil de ser gerada. Se tivermos uma métrica externa que conta o número de pés e cabeças (que não pode ser facilmente usada como uma função de custo porque essas não são métricas perfeitas), observaremos rapidamente se nosso modelo está trapaceando e reconsideraremos o treinamento feito. Por outro lado, se nossa métrica alternativa pontua bem, podemos ter alguma confiança de que o modelo compreendeu a ideia de como um cachorro deve ser, em vez de apenas enganar a função de custo para obter um valor baixo.