Otimizar modelos usando o gradiente descendente
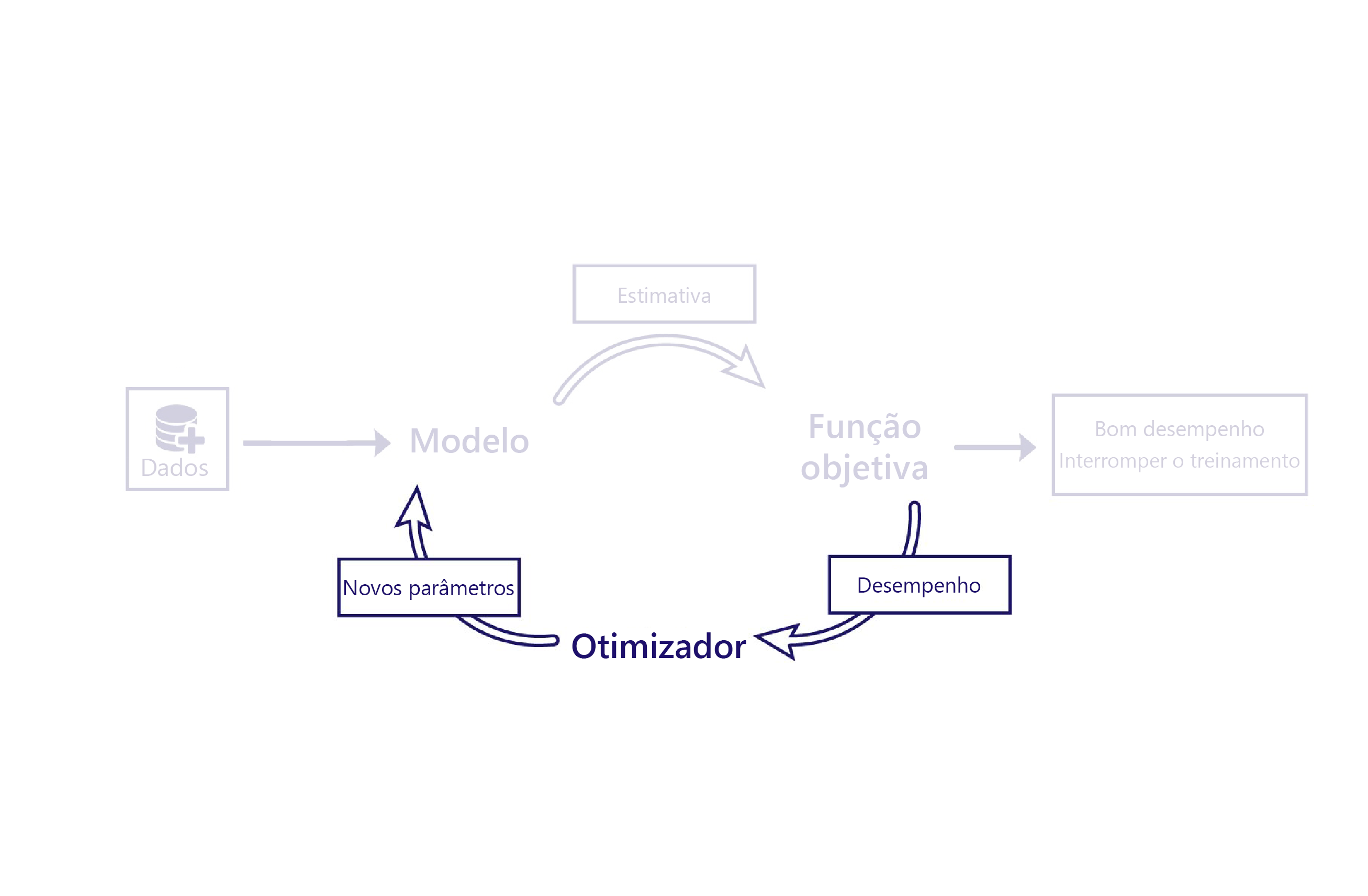
Vimos como as funções de custo avaliam o desempenho dos modelos usando dados. O otimizador é a parte final do quebra-cabeça.
A função do otimizador é alterar o modelo de forma a melhorar o seu desempenho. Ele faz essa alteração inspecionando as saídas e os custos do modelo e sugerindo novos parâmetros para ele.
Por exemplo, em nosso cenário agropecuário, o modelo linear tem dois parâmetros: interceptação da linha e inclinação da linha. Se a interceptação da linha estiver errada, o modelo fará, em média, estimativas muito altas ou muito baixas de temperatura. Se a inclinação estiver configurada incorretamente, o modelo não fará um bom trabalho em demonstrar como as temperaturas têm mudado desde os anos 1950. O otimizador altera esses dois parâmetros para que eles façam um trabalho adequado de modelagem de temperaturas ao longo do tempo.
Descendente de gradiente
O algoritmo de otimização mais comum no momento é o gradiente descendente. Existem várias variantes desse algoritmo, mas todas usam os mesmos conceitos básicos.
O gradiente descendente usa cálculos para estimar como a alteração de cada parâmetro altera o custo. Por exemplo, o aumento de um parâmetro pode ser previsto para reduzir o custo.
O descendente de gradiente leva esse nome porque calcula o gradiente (inclinação) da relação entre cada parâmetro de modelo e seu custo. Os parâmetros são então alterados para reduzir essa inclinação.
Esse algoritmo é simples e poderoso, mas não há garantia de encontrar os parâmetros de modelo ideais que minimizem o custo. As duas principais fontes de erro são o mínimo local e a instabilidade.
Mínimos locais
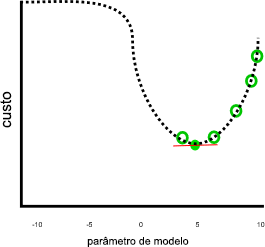
Nosso exemplo anterior parecia fazer um bom trabalho, assumindo que o custo continuaria aumentando quando o parâmetro fosse menor que 0 ou maior que 10:
Esse trabalho não pareceria tão bom se parâmetros menores que zero ou maiores que 10 resultassem em custos mais baixos, como nesta imagem:
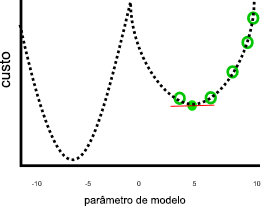
No gráfico anterior, um valor de parâmetro de sete negativo seria uma solução melhor que cinco, porque tem um custo menor. O gradiente descendente não conhece o relacionamento completo entre cada parâmetro e o custo, representado pela linha pontilhada, com antecedência. Portanto, ele é propenso a encontrar a mínima local: estimativas de parâmetro que não são a melhor solução, mas o gradiente é zero.
Instabilidade
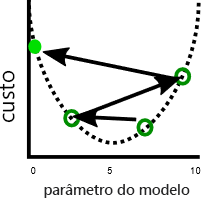
Um problema relacionado é que o descendente de gradiente às vezes apresenta instabilidade. Esta instabilidade geralmente ocorre quando o tamanho da etapa ou a taxa de aprendizado, o valor pelo qual cada parâmetro é ajustado a cada iteração, é muito grande. Os parâmetros são ajustados muito em cada etapa e o modelo fica pior a cada iteração:
Uma taxa de aprendizado mais lenta pode resolver esse problema, mas também pode introduzir outros. Em primeiro lugar, taxas de aprendizado mais lentas podem representar mais tempo de treinamento, pois são necessárias mais etapas. Em segundo lugar, etapas menores aumenta a probabilidade de que o treinamento se acomode em uma mínima local:
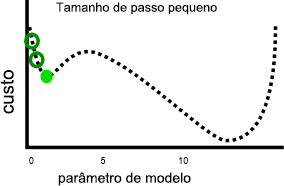
Por outro lado, uma taxa de aprendizado mais rápida pode tornar mais fácil evitar os mínimos locais, pois as etapas maiores podem ignorar em direção aos máximos locais:
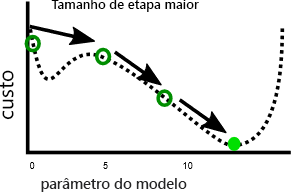
Como veremos no próximo exercício, há um tamanho de etapa ideal para cada problema. Para encontrar esse tamanho ideal, costuma ser necessária experimentação.