Definir o aprendizado supervisionado
O processo de treinamento de modelo pode ser supervisionado ou não supervisionado. Nossa meta é contrastar essas abordagens e, em seguida, nos aprofundarmos no processo de aprendizado, com foco no aprendizado supervisionado. Vale a pena lembrar ao longo desta discussão que a única diferença entre o aprendizado supervisionado e não supervisionado é como a função de objetivo funciona.
O que é aprendizado não supervisionado?
No aprendizado não supervisionado, treinamos um modelo para resolver um problema sem sabermos a resposta correta. Na verdade, o aprendizado não supervisionado normalmente é usado para problemas em que não há uma resposta correta, mas sim soluções melhores e piores.
Imagine que queremos que nosso modelo de machine learning gere imagens realistas de cachorros de resgate de avalanche. Não há um desenho "correto" a ser desenhado. Ficaremos satisfeitos se a imagem for um pouco semelhante a um cachorro. Mas se a imagem produzida for de um gato, essa será uma solução pior.
Lembre-se de que o treinamento requer vários componentes:
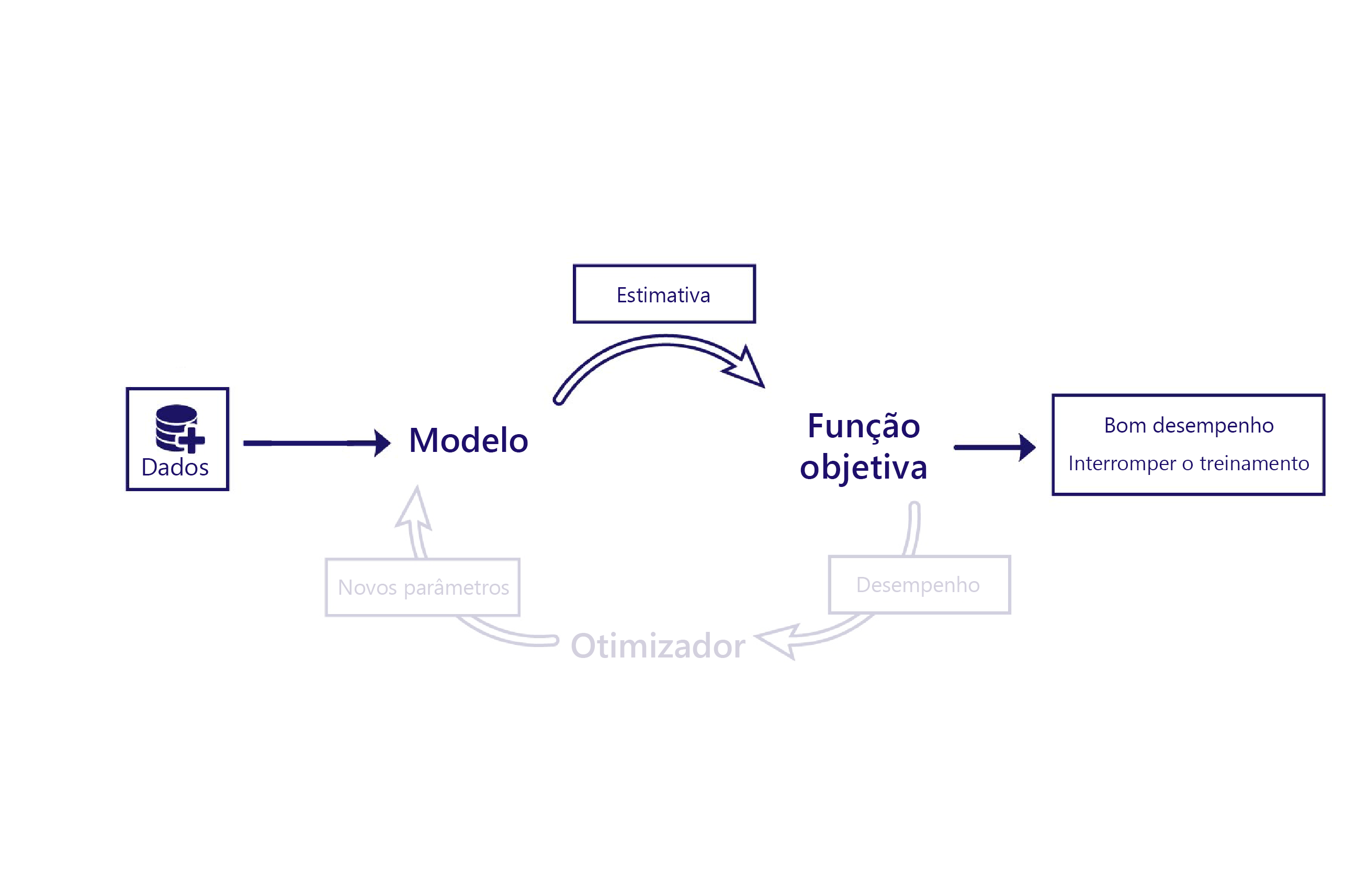
No aprendizado não supervisionado, a função de objetivo faz o julgamento unicamente em relação à estimativa do modelo. Isso significa que geralmente a função de objetivo precisa ser relativamente sofisticada. Por exemplo, a função de objetivo pode precisar conter um "detector de cachorros" para avaliar se as imagens que o modelo gera são realistas. Os únicos dados necessários para o aprendizado não supervisionado são sobre os recursos que fornecemos ao modelo.
O que é aprendizado supervisionado?
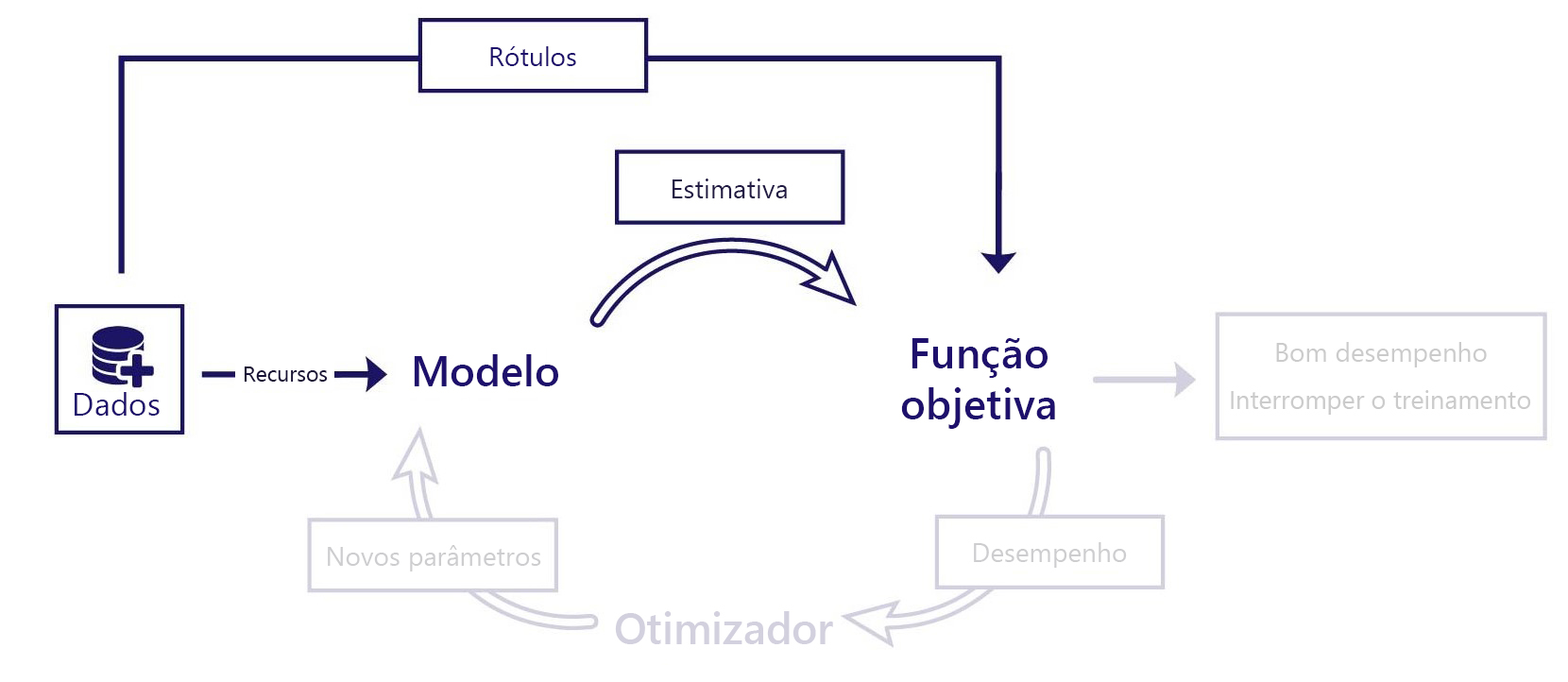
O aprendizado supervisionado pode ser compreendido como um aprendizado por exemplo. No aprendizado supervisionado, avaliamos o desempenho do modelo comparando suas estimativas com a resposta correta. Embora seja possível ter funções de objetivo muito simples, o seguinte é necessário:
- Recursos fornecidos como entradas para o modelo
- Rótulos, que são as respostas corretas que queremos que o modelo seja capaz de produzir
Por exemplo, considere nosso desejo de prever qual será a temperatura em 31 de janeiro de um determinado ano. Para essa previsão, precisamos de dados com dois componentes:
- Recurso: data
- Rótulo: temperatura diária (por exemplo, com base em registros históricos)
No cenário, fornecemos o recurso de data para o modelo. O modelo prevê a temperatura e comparamos esse resultado com a temperatura "correta" do conjunto de dados. Depois, a função de objetivo pode calcular o desempenho do modelo e podemos fazer ajustes.
Os rótulos são apenas para aprendizado
É importante lembrar que, independentemente de como os modelos são treinados, eles só processam recursos. Durante o aprendizado supervisionado, a função de objetivo é o único componente que depende do acesso aos rótulos. Após o treinamento, não precisamos de rótulos para usar o modelo.