SLIs (Indicadores de Nível de Serviço) e SLOs (Objetivos de Nível de Serviço)
Neste módulo, até agora, aprendemos como aumentar a consciência operacional e expandir a compreensão e a estruturação da confiabilidade e vimos as ferramentas do Azure Monitor que usaremos no trabalho. Agora é hora de explorar uma das ideias mais importantes deste módulo e os processos para implementá-la.
Vamos responder à pergunta "como faço para usar tudo isso a fim de melhorar a confiabilidade na minha organização?"
Ingressar no loop de comentários
Aqui está a grande ideia que pode desbloquear o problema para nós:
os loops de comentários certos melhoram a confiabilidade na sua organização.
Melhorar a confiabilidade na sua organização é um processo iterativo. Nesta unidade, vamos examinar uma prática altamente eficaz do mundo da engenharia de confiabilidade de site para criar e incentivar o tipo de loop de comentários em uma organização que ajuda a aprimorar a confiabilidade. Na pior das hipóteses, isso despertará conversas concretas na sua organização sobre a confiabilidade com base em dados objetivos.
Anteriormente neste módulo, mencionamos o seguinte como definição da engenharia de confiabilidade do site:
a Engenharia de Confiabilidade do Site é uma disciplina de engenharia dedicada a ajudar as organizações a alcançarem de maneira sustentável o nível de confiabilidade apropriado nos sistemas, serviços e produtos.
É aqui que entra em cena o conceito de nível apropriado de confiabilidade.
SLIs (Indicadores de Nível de Serviço)
Os SLIs (Indicadores de Nível de Serviço) estão conectados à nossa discussão anterior sobre a compreensão abrangente da confiabilidade. Lembra desse diagrama?
Os SLIs são a nossa tentativa de especificar exatamente como vamos medir a confiabilidade do nosso sistema. Qual é o indicador de que o serviço está se comportando de maneira confiável (ou seja, fazendo o que é esperado)? O que podemos medir para responder a essa pergunta?
Exemplo: disponibilidade e latência do servidor Web
Digamos que estamos trabalhando com um servidor Web e sua disponibilidade. Neste caso, queremos saber o número de solicitações HTTP recebidas e o número de solicitações HTTP respondidas com sucesso. Mais especificamente, queremos entender como o servidor Web se saiu em sua função analisando a taxa de solicitações bem-sucedidas para o total de solicitações.
Se dividirmos o número total de solicitações pelo número de solicitações bem-sucedidas, obteremos uma taxa. Podemos multiplicar essa taxa por 100 para obter uma porcentagem. Como exemplo, usando números redondos, se o servidor Web recebesse 100 solicitações e respondesse com sucesso a 80 delas, teríamos a taxa de 0,8. Multiplicando isso por 100, podemos afirmar que a disponibilidade foi de 80%.
Vamos tentar outro. Desta vez, vamos especificar uma medida associada à latência do nosso serviço Web. Neste caso, queremos saber a taxa do número de operações concluídas em menos de 10 milissegundos em relação ao número de operações totais. Se fizermos o mesmo cálculo, ou seja, dividirmos o total de 100 solicitações por 80 solicitações que retornaram mais rápido que o nosso limite estabelecido, novamente teremos a taxa de 0,8. Multiplicando por 100, aqui também poderemos dizer que houve 80% de sucesso em relação aos requisitos de latência dessa medida.
Só deixar claro: isso não se aplica apenas a sites. Se tivermos um serviço de pipeline que processa dados, poderemos medir a cobertura (por exemplo, o volume de dados que processamos). Sistema bem diferente, mas o mesmo cálculo básico.
SLIs: onde medir
Para que os SLIs sejam úteis em discussões concretas usando dados objetivos, há uma outra peça que precisamos especificar além do que estamos medindo. Ao criar um SLI, precisamos observar não apenas o que medimos, mas também onde a medida foi realizada.
Por exemplo, quando especificamos que estávamos medindo a disponibilidade do servidor Web anteriormente, não dissemos de onde recuperamos os números de solicitações HTTP totais e bem sucedidas. Se você tentar conversar sobre a confiabilidade desse servidor Web com alguns colegas e analisar as estatísticas de solicitação coletadas em um balanceador de carga em frente ao servidor, mas eles analisarem as estatísticas do próprio servidor, a conversa não será muito produtiva. Os números poderão ser bastante diferentes, já que o balanceador de carga poderá enxergar todas as solicitações que chegam à rede, mas se ocorre um problema com a rede ou com o balanceador de carga, em si, nem todas as solicitações alcançarão o servidor. Vocês estariam extraindo conclusões com base em dois conjuntos de dados diferentes.
A maneira simples de resolver isso é sendo específico sobre a fonte de dados no SLI. Para o servidor Web, diríamos que "a taxa de solicitações bem sucedidas em relação ao total de solicitações conforme medição do balanceador de carga" para a disponibilidade. Para a latência, diríamos algo como "a taxa do número de operações concluídas em menos de 10 milissegundos em relação ao total de operações conforme medição do cliente".
Isso leva à pergunta lógica: qual é o melhor lugar para medir os SLIs? Infelizmente, não há uma resposta universalmente "correta". É uma decisão que você deve tomar ciente de que há prós e contras. Uma orientação que podemos oferecer remete à nossa discussão anterior sobre confiabilidade: tente medir as coisas em um local que reflita com mais precisão a experiência do cliente.
SLOs (Objetivos de Nível de Serviço)
Decidir o que (e onde) medir é um ótimo começo, mas só nos leva até metade do caminho para cumprir a meta. Vamos supor que tenhamos recuperado as métricas necessárias para calcular o SLI de disponibilidade do servidor Web e descobrimos que ele está, de fato, 80% disponível.
Isso é bom ou ruim? Esse é o "nível apropriado de confiabilidade" necessário?
Para responder a essas perguntas, vamos precisar definir um objetivo para esse SLI: um SLO (Objetivo de Nível de Serviço). Esse objetivo informará claramente a meta do serviço.
A receita básica para a criação de um SLO consiste nos seguintes ingredientes:
A "coisa" que você vai medir: número de solicitações, verificações de armazenamento, operações; o que você está medindo.
A proporção desejada: por exemplo, "sucesso em 50% das vezes", "possível de ler em 99,9% das vezes", "retornar em até 10 ms em 90% das vezes".
O horizonte de tempo: qual será o período que vamos considerar para o objetivo: os últimos 10 minutos, o último trimestre, uma janela de 30 dias sem interrupção? Os SLOs, muitas vezes, são especificados usando uma janela sem interrupção versus uma unidade de calendário como "um mês", por exemplo, a fim de nos permitir comparar dados de diferentes períodos.
Reunindo esses componentes e incluindo a importante informação sobre onde, um exemplo de SLO teria a seguinte aparência:
90% das solicitações HTTP relatadas pelo balanceador de carga na última janela de 30 dias foram bem-sucedidas.
Da mesma forma, um SLO básico medindo a latência teria a seguinte aparência:
90% das solicitações HTTP relatadas pelo cliente e retornadas em menos de 20 ms na janela dos últimos 30 dias.
Comece com SLOs básicos e simples, como estes, ao apresentar essa prática na sua organização. Você poderá criar SLOs mais complexos posteriormente, se necessário.
SLIs e SLOs no Azure Monitor
Como uma peça final dessa unidade, vamos ver como é possível representar um SLI/SLO simples no Azure Monitor usando o Log Analytics. Para manter a consistência, retornaremos ao exemplo do servidor Web.
Vimos na última unidade que podemos criar consultas no Log Analytics usando a KQL (Linguagem de Consulta Kusto). Esta é uma consulta KQL que exibe um SLI de disponibilidade para um serviço Web:
requests
| where timestamp > ago(30d)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| project SLI, timestamp
| render timechart
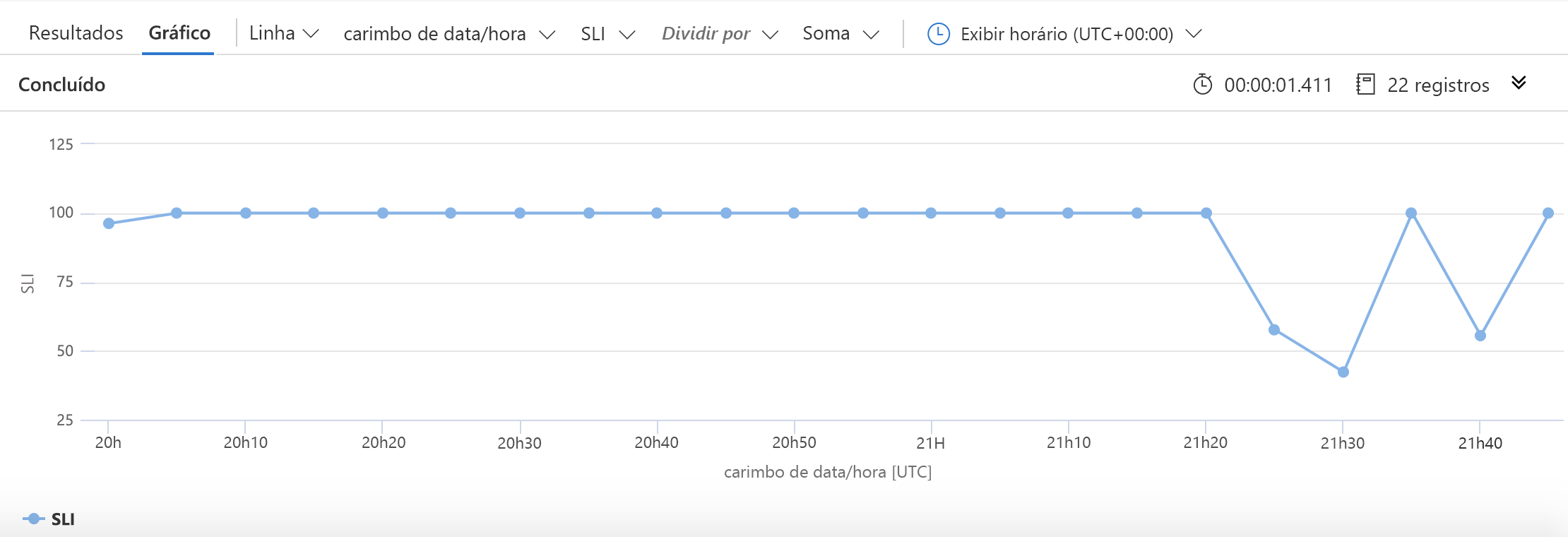
Como anteriormente, começamos com a especificação da origem dos dados: a tabela requests. Em seguida, reduzimos os dados com os quais trabalharemos para apenas as informações dos últimos 30 dias. Em seguida, coletamos (em buckets de cinco minutos) o número de solicitações bem-sucedidas, o número de solicitações com falha e o número total de solicitações. O SLI é criado usando o cálculo simples que vimos anteriormente. Nós dizemos à KQL que gostaríamos de plotar o SLI juntamente com os carimbos de data/hora e, em seguida, criar um gráfico parecido com esse:
Agora, vamos colocar em camadas uma representação simples de um SLO:
requests
| where timestamp > ago(5h)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| extend SLO = 80.0
| project SLI, timestamp, SLO
| render timechart
Há apenas duas linhas que mudam neste exemplo em relação ao anterior. A primeira define o número que usaremos para o SLO e a segunda informa o KQL de que o SLO deve ser incluído no gráfico. O resultado será semelhante a este:
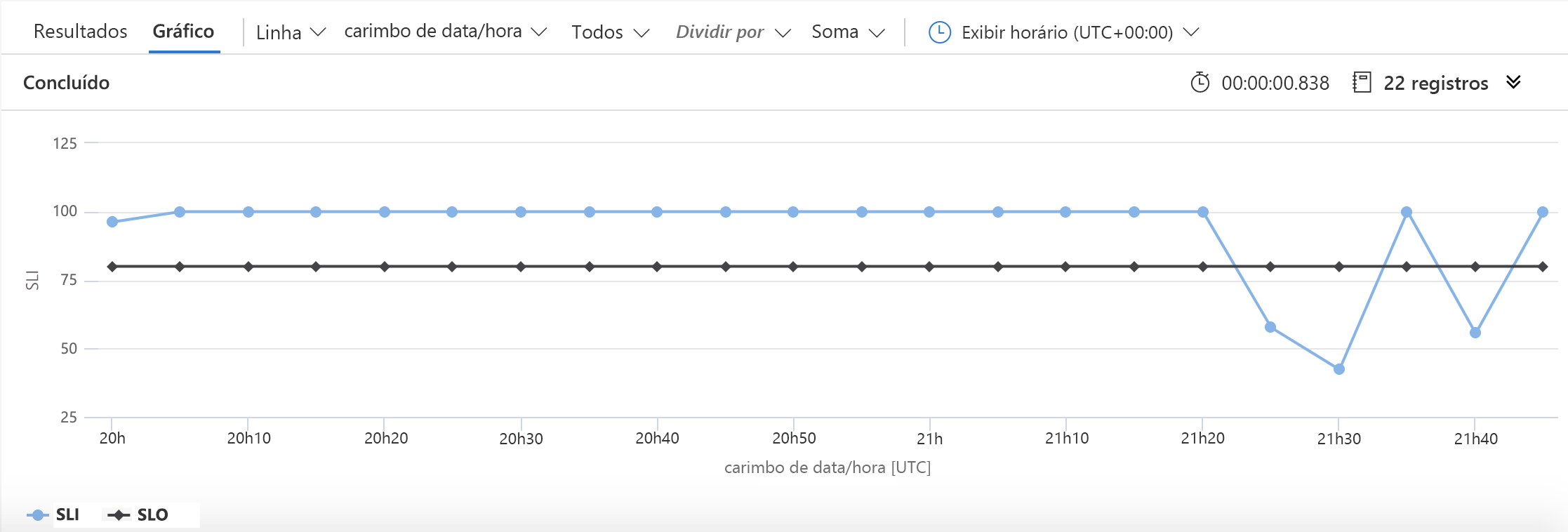
Neste gráfico, é fácil ver o momento em que ficamos abaixo do nosso objetivo de disponibilidade.
Usando SLIs/SLOs
Sem dúvida, será necessário fazer ajustes nos SLIs e nos SLOs (afinal, trata-se de um processo iterativo). Mas depois disso, o que fazer com as informações?
A boa notícia é que você provavelmente vai notar que o simples fato de criar os SLIs e os SLOs já causa efeitos positivos na organização. Isso requer discussões com os stakeholders e outras comunicações que colocam as coisas no caminho certo. A próxima rodada de discussões sobre o que fazer com eles também pode ser útil de maneira semelhante.
Em última análise, os SLIs e os SLOs são ferramentas de planejamento de trabalho. Eles podem ajudá-lo a tomar decisões de engenharia como “devemos trabalhar em novos recursos para o serviço ou devemos nos concentrar no trabalho de confiabilidade?”. Eles podem ajudar com o tipo de loops de comentários que discutimos antes.
Um uso secundário, mas muito comum, dos SLIs e dos SLOs é como parte de um sistema de monitoramento/resposta mais imediato. Além do aspecto de planejamento de trabalho (no qual você deve se concentrar primeiro), muitas pessoas os usam como sinalizadores de operações. Por exemplo, eles podem optar por alertar a equipe se o serviço ficar abaixo do SLO por um período prolongado. Esse tipo de alerta nos leva à próxima unidade deste módulo.