Consultas KQL e do Log Analytics
Ao começarmos a prestar atenção na confiabilidade dos nossos serviços, precisamos de uma forma de acompanhar o desempenho deles. Geralmente, podemos encontrar essas informações nos logs de um serviço, portanto, vamos precisar de uma ferramenta para trabalhar com esses logs. O Log Analytics é a ferramenta que usaremos no Azure para essa finalidade. Ele nos permite consultar esses dados e exibi-los de maneiras úteis para o nosso trabalho de confiabilidade.
O processo de consulta da análise de logs envolve a gravação consultas na KQL (Linguagem de Consulta Kusto). Se você já trabalhou com qualquer outra linguagem de consulta (por exemplo, a linguagem SQL), você não terá dificuldades ao lidar com a KQL. Mesmo que não tenha, depois de ver como funciona você provavelmente achará as consultas básicas da KQL bem fáceis.
Como funciona o Log Analytics
Então, vamos ver como tudo vai funcionar. Este é um diagrama de como funciona o Log Analytics:
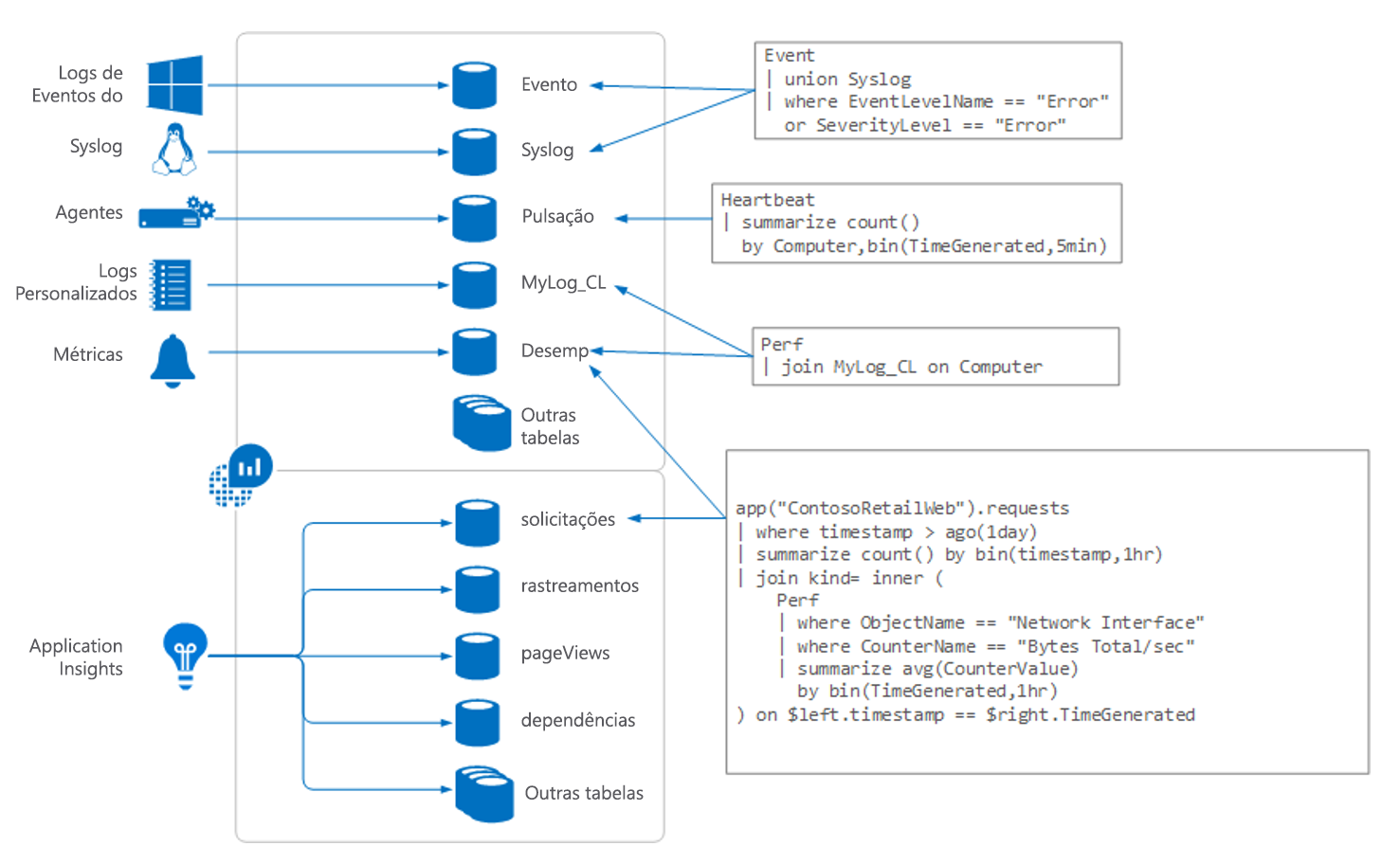
Os dados do Log Analytics vêm de várias fontes, incluindo:
- Logs de eventos do Windows
syslogem máquinas do Linux- Agentes em execução em VMs
- Logs personalizados que as pessoas optam por enviar
- Métricas dos recursos do Azure
- Informações de telemetria do Application Insights
Todas essas informações são inseridas naquilo que o Log Analytics chama de tabelas. Você pode pensar em cada tabela como um banco de dados separado. Você escreverá consultas para extrair as informações das tabelas. Para os exemplos que mostraremos mais adiante neste módulo, trabalharemos principalmente com uma tabela chamada "requests".
Interface do Log Analytics
A imagem a seguir mostra as diferentes partes da interface Log Analytics.
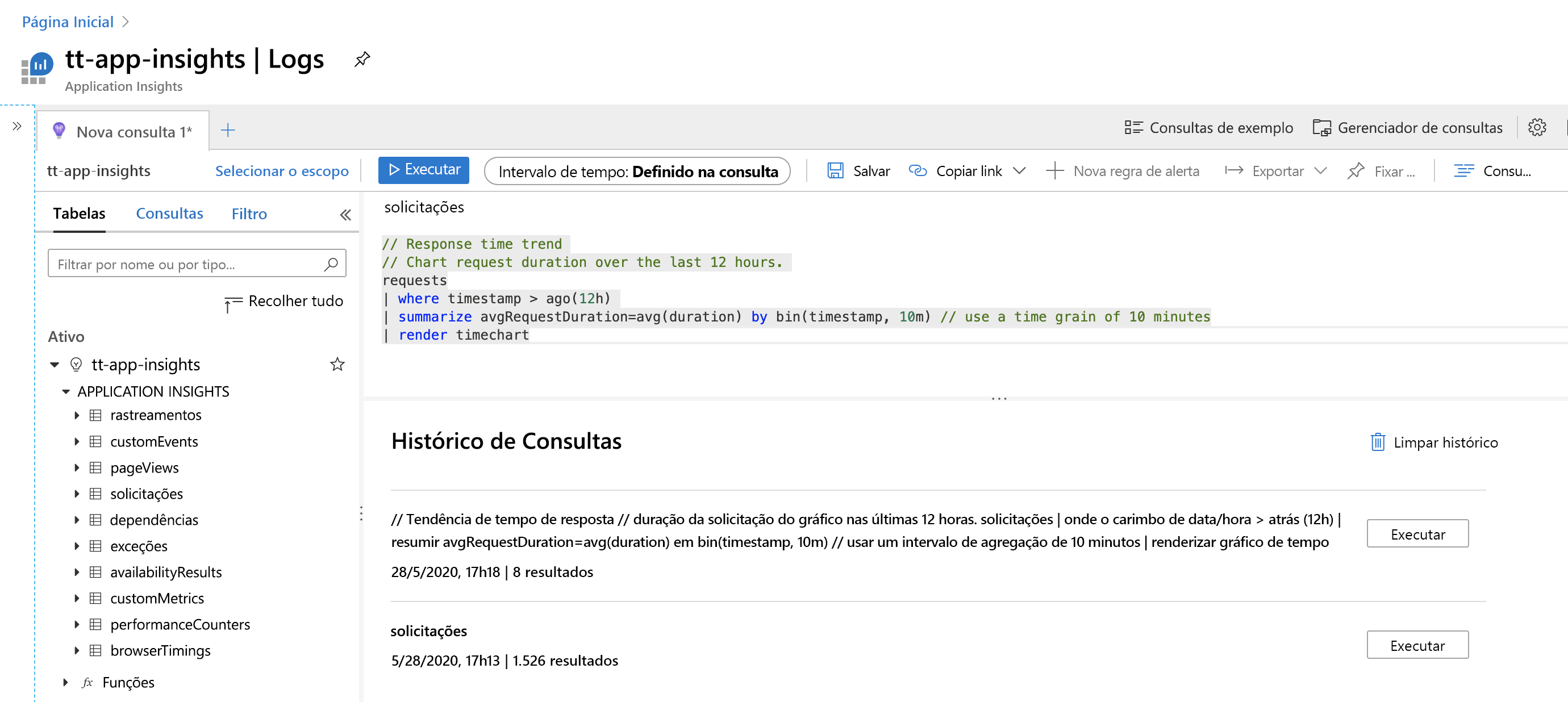
À esquerda há uma seção da tela que garante que você nunca se perca ao usar o Log Analytics. Ela mostra as tabelas com as quais você possivelmente está trabalhando e, se você expandir a seção, verá uma listagem dos campos da tabela que estão disponíveis para consulta. Se você selecionar qualquer um dos campos ou no nome da tabela, ele será copiado para a área de construção de consultas.
A área de construção de consultas fica na parte superior. É aí que você especifica as consultas e as executas. Você pode determinar um período para os dados, caso isso não tenha sido especificado na própria consulta. Você pode salvar as consultas ou abrir guias adicionais, caso deseje trabalhar com várias consultas ao mesmo tempo.
Na parte inferior da página, há mais informações úteis. Aqui, o Log Analytics mostra as consultas anteriores que você executou, o que pode ser útil se você precisar retornar a algo que já especificou anteriormente. Por exemplo, se você estava trabalhando em uma consulta, tentou algo diferente, mas precisou retornar à consulta original.
Escrevendo consultas KQL
A KQL é uma linguagem de consulta avançada. Vamos apresentar aqui apenas alguns exemplos básicos para que você possa ver como ela é fácil de usar. Posteriormente, se quiser se aprofundar para usar alguns dos recursos mais avançados (incluindo algumas funcionalidades de machine learning), confira o tutorial do Log Analytics.
Vamos começar escrevendo uma consulta KQL simples. Quase todas as consultas KQL começam com a fonte de dados: a tabela que você está consultando. Portanto, se você estivesse consultando dados de uma tabela de "solicitações", começaria assim na área de consulta:
Requests
Na próxima parte da consulta KQL você conecta a tabela com a operação que deseja executar. Use o caractere pipe (a barra vertical do teclado, normalmente encontrada acima da tecla de barra invertida) entre o nome da tabela e o comando.
Aqui está uma consulta simples para classificar a tabela e retornar os 10 principais registros encontrados:
Requests
|top 10
Estes são alguns exemplos de outros comandos comuns que você pode usar em vez dos "dez principais":
Se quiser ver 10 registros aleatórios em vez dos 10 primeiros (por exemplo, para ver a estrutura da tabela), use o comando a seguir:
requests |take 10Para ver os registros que entraram durante a última meia hora, você pode usar a seguinte consulta:
requests |where timestamp > ago(30m)Outra tarefa comum é especificar a ordem em que os dados serão retornados. Aqui está um exemplo de uma consulta que usa a classificação por um campo específico (carimbo de data/hora) em ordem descendente (por exemplo, os dados mais recentes primeiro):
requests |sort by timestamp desc
Assim como acontece no SQL, você pode definir várias condições para especificar quais registros deseja que sejam retornados. Use caracteres pipe e cláusulas adicionais para incluir mais condições. O caractere pipe separa os comandos para que a saída do primeiro seja a entrada do próximo comando. As consultas podem conter um número ilimitado de comandos.
Este é um exemplo de uma consulta que retorna todos os registros de código de resposta 404 (por exemplo, todos os registros de "página não encontrada" de um serviço Web) dos últimos 30 minutos:
requests
|where timestamp > ago(30m)
|where toint(resultCode) == 404
Essa consulta está escrita de modo a maximizar a eficiência. Ao selecionar primeiro os registros dos últimos 30 minutos, você reduz drasticamente o número de registros que a segunda cláusula precisa examinar. Se você escrevesse essa consulta na ordem oposta, primeiro ela encontraria todos os registros 404 (desde o início dos dados) e só depois descartaria a grande maioria para retornar apenas os registros correspondentes à última meia hora. Sempre leve em consideração a ordem de processamento ao escrever consultas com várias condições.
Um último exemplo de consulta antes de retornarmos ao poder do Log Analytics, mais adiante neste módulo, para ajudar a melhorar nossa confiabilidade. Aqui está uma consulta que mostra um cálculo com base nos dados:
requests
|where timestamp > ago(30m)
|summarize count() by name, URL
Essa consulta retorna um resumo das solicitações recebidas na última meia hora. Assim, em um serviço Web, essa consulta nos revelaria que houve a solicitação GET index.html para a URL http://tailwindtraders.com 2.875 vezes. Vamos parar por aqui nossos estudos da KQL com essa consulta, pois ela se conecta perfeitamente com as consultas KQL que usaremos na próxima unidade.