Explorar classificadores treináveis
As organizações classificam e rotulam o conteúdo para que possam protegê-lo e manipulá-lo adequadamente. Classificar e rotular o conteúdo é o ponto de partida para a disciplina de proteção de informações. O Microsoft 365 tem três maneiras de classificar o conteúdo:
Manualmente. A classificação manual requer a avaliação e a ação humana. Os usuários e administradores os aplicam ao conteúdo conforme eles o encontram. Você pode usar os rótulos pré-existentes e os tipos de informações confidenciais ou usar os rótulos personalizados. Em seguida, você pode proteger o conteúdo e gerenciar sua disposição.
Correspondência de padrões automatizada. Essa categoria de mecanismos de classificação inclui encontrar conteúdo por:
- Palavras-chave ou valores de metadados (idioma de consulta de palavra-chave).
- Usar padrões identificados anteriormente de informações confidenciais, como seguro social, cartão de crédito ou números de conta bancária.
- Reconhecer um item porque é uma variação de um modelo (impressão digital de documento, abordada em uma unidade posterior neste treinamento).
- Usar a presença de correspondência exata de cadeias de caracteres de dados exatos.
Classificadores treináveis. Um classificador treinável do Microsoft 365 é uma ferramenta que uma organização pode "treinar" para reconhecer vários tipos de conteúdo. O Microsoft 365 inclui uma lista extensa de classificadores predefinidos. As organizações também podem criar seus próprios classificadores personalizados. Você pode treinar classificadores fornecendo-lhes amostras para análise. Depois de treinar um classificador, a organização poderá usá-lo para identificar itens para aplicativo de rótulos de confidencialidade do Office, políticas de conformidade de comunicações e políticas de rótulo de retenção.
Esta unidade examina o uso de classificadores treináveis.
Classificadores de treinamento
Para começar a usar classificadores treináveis no Microsoft Purview, primeiro você pode iniciar um processo de verificação. Esse processo analisa os dados da sua empresa e identifica padrões que o sistema pode usar para treinar o classificador. Depois que o sistema examina seus dados, ele identifica temas e padrões comuns. Em seguida, o sistema pode criar regras para o classificador treinável usando essas informações. Esse processo ajuda a garantir que o classificador treinável seja preciso e eficaz na identificação e categorização dos dados. Depois que o processo de verificação for concluído, você poderá treinar o classificador treinável usando os padrões e regras identificados. Depois de concluir o treinamento do classificador, você poderá aplicá-lo a novos dados para classificá-los automaticamente.
Aviso
Pode levar de 7 a 14 dias para que a verificação seja concluída. Se não quiser executar o processo de verificação para criar um classificador de treinamento personalizado para sua organização, você poderá usar os classificadores internos do Microsoft Purview.
Na primeira vez que você acessar a página Classificadores de treinamento no portal de conformidade do Microsoft Purview, a captura de tela a seguir será exibida.
A criação de um classificador treinável personalizado envolve primeiro fornecer a ele amostras que você escolheu manualmente e que correspondem positivamente à categoria. Depois que a ferramenta do classificador treinável processar essas amostras, você testará a capacidade de previsão dos classificadores, fornecendo-lhes uma combinação de amostras positivas e negativas. Esta unidade examina como criar e treinar um classificador personalizado. Também examina como melhorar o desempenho de classificadores treináveis personalizados e classificadores pré-treinados ao longo de seu tempo de vida por meio de um novo treinamento.
O método de classificação funciona bem em conteúdo que os métodos automatizados ou manuais de correspondência de padrões não conseguem identificar facilmente. Esse método de classificação é mais sobre usar um classificador para identificar um item com base no que o item é, e não pelos elementos que estão no item (correspondência de padrões). Um classificador aprende como identificar um tipo de conteúdo observando centenas de amostras desse tipo de conteúdo.
Observação
Você pode exibir os classificadores treináveis na ferramenta Explorador de conteúdos expandindo os Classificadores treináveis no painel de filtros. Os classificadores treináveis exibem automaticamente o número de incidentes encontrados no SharePoint, Teams e OneDrive, sem exigir qualquer rotulagem. Se não quiser usar esse recurso, você deverá registrar uma solicitação no Suporte da Microsoft para desabilitar a classificação pronta para uso. Isso desabilita a verificação de seu conteúdo confidencial e rotulado antes de você criar as políticas de rotulagem.
Os classificadores estão disponíveis para uso como uma condição para:
- Rotulagem automática do Office com rótulos de confidencialidade
- Aplicar automaticamente uma política de rótulo de retenção com base em uma condição
- Conformidade de comunicações
Observação
Os classificadores funcionam apenas com itens que não estão criptografados.
Há dois tipos de classificadores treináveis:
- Classificadores pré-treinados. A Microsoft criou e treinou previamente vários classificadores que você pode começar a usar sem treiná-los. Esses classificadores aparecem com o status Pronto para uso.
- Classificadores treináveis personalizados. Se uma organização tiver necessidades de classificação que vão além do que os classificadores pré-treinados abrangem, poderá criar e treinar seus próprios classificadores.
As próximas seções examinam esses tipos de classificadores.
Classificadores pré-treinados
O Microsoft 365 vem com vários classificadores pré-treinados:
Adulto, ousado e sangrento. Detecta imagens desses tipos. As imagens devem ter entre 50 quilobytes (KB) e 4 megabytes (MB). Também devem ter dimensões maiores que 50 x 50 pixels em altura x largura. O sistema dá suporte à varredura e a detecção de mensagens de email do Exchange Online e de canais e chats do Microsoft Teams.
Contratos. Esse classificador detecta conteúdo relacionado a contratos legais. Por exemplo, declarações de contratos de trabalho, empréstimos e concessão e contratos de emprego e não conformidade.
Reclamações do Cliente. O classificador de reclamações de clientes detecta comentários e reclamações feitas sobre os produtos ou serviços da sua organização. Esse classificador pode ajudar você a atender aos requisitos regulatórios sobre a detecção e a triagem de reclamações, como os requisitos do Departamento de Proteção Financeira do Consumidor e Administração de Alimentos e Medicamentos.
Discriminação. Esse classificador detecta linguagem discriminatória explícita e é sensível à linguagem discriminatória contra as comunidades afro-americanas/negras quando comparada com outras comunidades.
Finanças. Esse classificador detecta conteúdo nas categorias finanças corporativas, contabilidade, economia, bancos e investimentos.
Assédio. Esse classificador detecta uma categoria específica de itens de texto com linguagem ofensiva. Esses itens devem se referir a condutas ofensivas que visam um ou vários indivíduos com base nos seguintes traços: raça, etnia, religião, origem nacional, gênero, orientação sexual, idade, deficiência.
Serviços de saúde. Esse classificador detecta conteúdo em aspectos médicos e de administração de serviços de saúde. Por exemplo, serviços médicos, diagnósticos, tratamento, declarações e assim por diante.
Recursos Humanos (RH). Esse classificador detecta o conteúdo em categorias relacionadas a recursos humanos. Por exemplo, recrutamento, entrevista, contratação, treinamento, avaliação, advertência e rescisão.
Propriedade Intelectual (PI). Esse classificador detecta o conteúdo em categorias relacionadas à propriedade intelectual, como segredos comerciais e informações confidenciais semelhantes.
Tecnologia da Informação (TI). Esse classificador detecta o conteúdo nas categorias de Tecnologia da Informação e Segurança Cibernética. Por exemplo, configurações de rede, segurança de informações, hardware e software.
Assuntos Jurídicos. Esse classificador detecta o conteúdo em categorias relacionadas a assuntos legais. Por exemplo, litígio, processo legal, obrigação legal, terminologia jurídica, lei e legislação.
Aquisição. Esse classificador detecta o conteúdo nas categorias de licitação, cotação, compra e pagamento pelo fornecimento de bens e serviços.
Linguagem ofensiva. Esse classificador detecta uma categoria específica de itens de texto com linguagem ofensiva que contém expressões que constrangem a maioria das pessoas.
Currículos. Esse classificador detecta itens docx, .pdf, .rtf e .txt que são relatos textuais das qualificações pessoais, educacionais, profissionais, experiência profissional e outras informações de identificação pessoal de um candidato.
Código-fonte. Esse classificador detecta itens que contêm um conjunto de instruções e declarações escritas nas 25 principais linguagens de programação de computador usadas no GitHub: ActionScript, C, C#, C++, Clojure, CoffeeScript, Go, Haskell, Java, JavaScript, Lua, MATLAB, Objective- C, Perl, PHP, Python, R, Ruby, Scala, Shell, Swift, TeX, Vim Script.
Observação
O classificador de código-fonte detecta quando a maior parte do texto é código-fonte. Não detecta texto de código-fonte intercalado com texto simples.
Fiscal. Esse classificador detecta conteúdo de relações tributárias, como planejamento tributário, formulários fiscais, declaração de impostos, regulamentações tributárias.
Ameaça. Esse classificador detecta uma categoria específica de itens de texto em linguagem ofensiva relacionados a ameaças de cometer violência ou causar danos físicos ou danos a uma pessoa ou propriedade.
Esses classificadores treináveis aparecem no portal de conformidade do Microsoft Purview. No painel de navegação, selecione Classificação de dados. Na página Classificação de dados, selecione a guia Classificadores treináveis. Exiba os classificadores com o status Pronto para uso.
Classificadores personalizados
Para algumas organizações, os classificadores pré-treinados não atendem às suas necessidades de classificação de dados. Nessa situação, uma organização pode criar e treinar seus próprios classificadores. Há mais trabalho envolvido na criação de um classificador personalizado, mas uma organização pode adaptá-lo para melhor atender às suas necessidades. As etapas de alto nível envolvidas na criação de um classificador personalizado incluem:
- Você começa a criar um classificador treinável personalizado alimentando-o com amostras que estão definitivamente na categoria.
- Depois que o classificador processa essas amostras, você o testará fornecendo uma combinação de amostras correspondentes e não correspondentes.
- O classificador então faz previsões se algum item se enquadra na categoria que você está criando.
- Em seguida, confirme seus resultados, classificando os verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos para ajudar a aumentar a precisão de suas previsões.
- Quando estiver satisfeito com os resultados do teste, implante o classificador publicando-o.
Quando você publica o classificador, ele classifica itens em locais como SharePoint Online, Exchange e OneDrive e classifica o conteúdo. Depois de publicar o classificador, você poderá continuar a treiná-lo usando um processo de comentários semelhante ao processo de treinamento inicial.
Por exemplo, você pode criar classificadores treináveis para:
- Documentos legais. Por exemplo, privilégio de advogado-cliente, conjuntos de fechamento e declarações de trabalho.
- Documentos de negócios estratégicos. Por exemplo, comunicados de imprensa, fusão e aquisição, ofertas, planos de negócios ou marketing, propriedade intelectual, patentes e documentos de design.
- Informações sobre preços. Por exemplo, faturas, cotações de preços, ordens de serviço e documentos de licitação.
- Informações financeiras. Por exemplo, investimentos organizacionais e resultados trimestrais ou anuais.
Prepare-se para um classificador treinável personalizado
Antes de começar, é útil entender os componentes envolvidos na criação de um classificador treinável personalizado. As seções a seguir examinam cada um desses componentes.
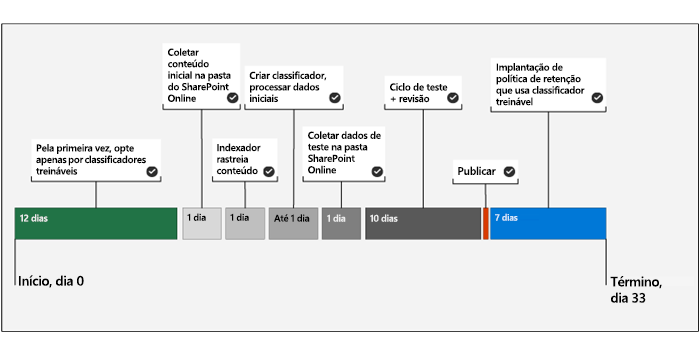
Linha do tempo
O diagrama a seguir exibe uma linha do tempo que reflete uma amostra de implantação de classificadores treináveis.
Dica
O sistema requer uma Aceitação única pela primeira vez para classificadores treináveis. O Microsoft 365 leva 12 dias para concluir uma avaliação básica do conteúdo de uma organização. Um Administrador global do Microsoft 365 deve iniciar o processo de aceitação.
Fluxo de trabalho geral
Para entender mais sobre o fluxo de trabalho geral da criação de classificadores treináveis personalizados, confira Fluxo de processo para criação de classificadores treináveis customizados.
Conteúdo de semeadura
O Microsoft Purview usa os classificadores treináveis para identificar de forma independente e precisa um item como pertencente a uma categoria específica de conteúdo. Para criar um classificador treinável, uma organização deve primeiro apresentar-lhe muitas amostras do tipo de conteúdo que está na categoria. A propagação é o processo de alimentação de amostras para o classificador treinável. Uma organização deve selecionar o conteúdo de semeadura que deseja usar para representar a categoria do conteúdo.
Dica
Você deve ter pelo menos 50 amostras positivas, com no máximo 500. amostras. O classificador treinável processa até as 500 amostras mais recentemente criadas (por data/horário de criação do arquivo). Quanto mais amostras você fornecer, mais precisas serão as previsões que o classificador fará.
Conteúdo de teste
Depois que o classificador treinável processa as amostras positivas suficientes para criar um modelo de previsão, a organização deve testar as previsões que o classificador faz. Você deve testar com dados diferentes dos dados de semeadura iniciais que você forneceu primeiro. O teste deve verificar se o classificador consegue distinguir corretamente entre os itens que correspondem à categoria e os itens que não correspondem. O teste deve começar selecionando outro conjunto de conteúdo manualmente selecionado, conhecido como amostra de teste. Deve consistir em amostras que se enquadram na categoria e amostras que não se enquadram.
Depois que o classificador processar essa amostra de teste, você deverá revisar manualmente os resultados. Ao fazer isso, você deverá verificar se cada previsão está correta, incorreta ou se não tem certeza. O classificador treinável usa esses comentários para melhorar seu modelo de previsão.
Dica
Para obter melhores resultados, tenha pelo menos 200 itens em sua amostra de teste. Ela deve incluir uma distribuição equilibrada de correspondências positivas e negativas.