Requisitos de acesso de arquivo híbrido
As unidades anteriores abordaram principalmente o que a solução de armazenamento faz. Esta unidade se concentra em onde os dados ficam localizados. Especificamente, as considerações sobre o acesso a arquivos híbrido e como lidar com eles.
Visão geral do acesso a arquivos híbrido
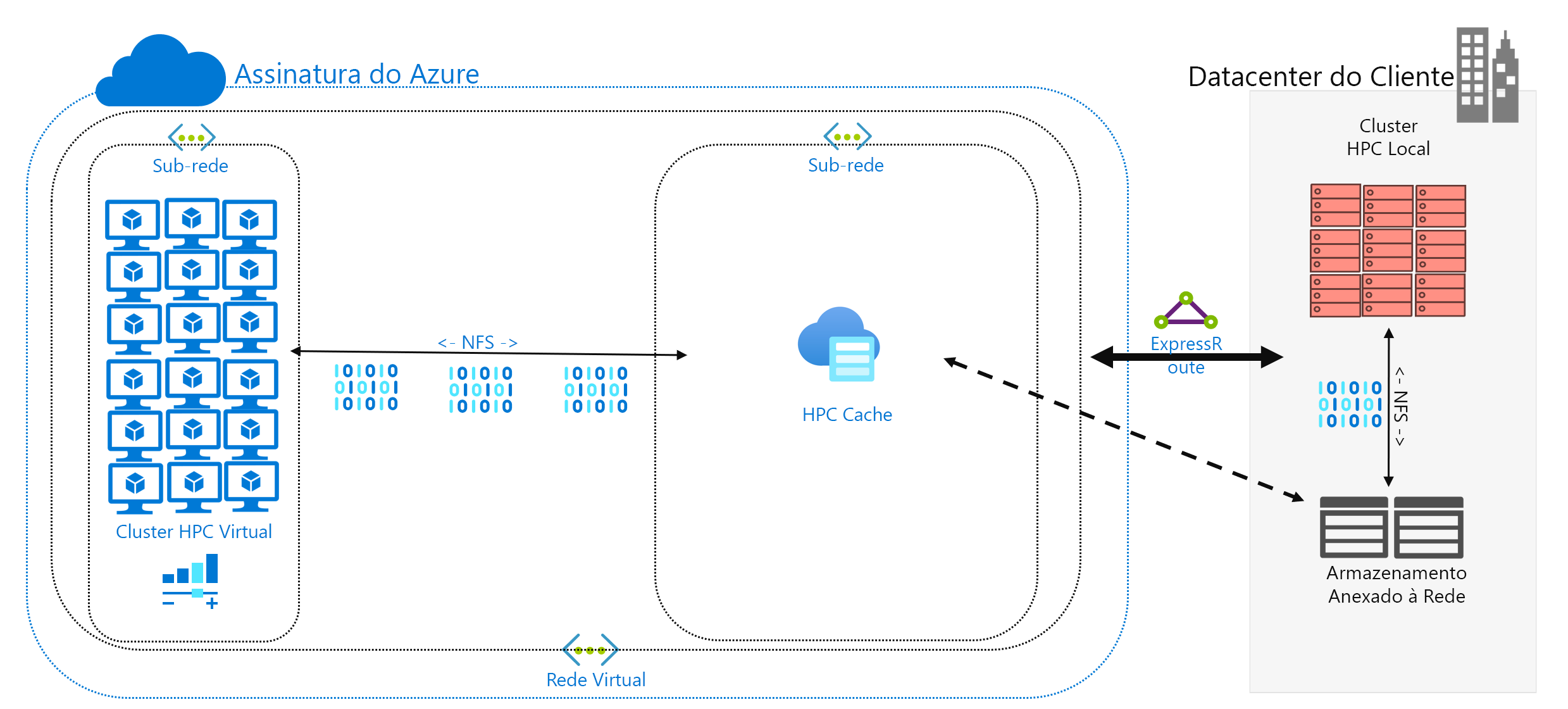
Você decidiu executar uma carga de trabalho de HPC no Azure que está em execução em seu datacenter. Seu ambiente de computação acessa dados em seu NAS, que está servindo operações do NFSv3 para a carga de trabalho. Ele está sendo executado há anos, mas talvez o ambiente de NAS esteja atingindo o final do ciclo. Em vez de substituí-lo, você está considerando uma migração de longo prazo para a nuvem.
Depois de tomar essa decisão, mas antes da implantação completa da nuvem da carga de trabalho do HPC, você determinará sua estratégia do Azure e estabelecerá sua conta de linha de base/assinatura/configuração de segurança. Agora vem a parte difícil: mover as cargas de trabalho de HPC!
A construção do cluster de HPC e do plano de gerenciamento está fora do escopo deste módulo. Vamos pressupor que você determinou os tipos e as quantidades de máquinas virtuais que deseja executar em seu cluster.
Por enquanto, vamos pressupor também que sua meta é executar a carga de trabalho da maneira em que se encontra. Ou seja, não convém modificar a lógica nem os métodos de acesso atualmente implantados localmente. A implicação é que o código espera que os dados estejam nos caminhos de diretório nos sistemas de arquivos locais dos membros do cluster.
A primeira meta é entender quais dados são necessários e de onde eles são originados. Seus dados podem estar em um só diretório em um só ambiente de NAS ou podem estar distribuídos entre vários ambientes.
A próxima meta é determinar a quantidade de dados necessários para executar a carga de trabalho. Os dados de origem são alguns gigabytes ou centenas de terabytes?
Por fim, você precisa determinar como os dados são apresentados na computação do Azure. Eles são servidos localmente para cada computador do cluster de HPC ou compartilhados por uma solução de NAS baseada em nuvem?
Considerações sobre o acesso a dados remotos
Você tem uma carga de trabalho de genômica que deseja executar no Azure. Seus dados são gerados localmente por sequenciadores de genes e enviados para um ambiente de NAS local. Os pesquisadores no local consomem os dados para várias finalidades. Os pesquisadores também podem querer consumir os resultados da carga de trabalho de HPC que você pretende executar no Azure. Mas alguns deles usam estações de trabalho locais para fazer isso. Vamos supor também que os dados de genoma atualizados sejam gerados regularmente. Sendo assim, você tem um intervalo limitado para executar a carga de trabalho atual antes que os dados precisem ser substituídos/atualizados.
O desafio é apresentar os dados para a computação do Azure de maneira econômica, mas ainda preservar o acesso local a eles.
Estas são algumas das principais perguntas a serem feitas quando você está tentando executar cargas de trabalho de HPC no Azure:
- Podemos mover os dados de origem para o Azure sem reter uma cópia no local?
- Podemos salvar os dados de resultado no armazenamento do Azure sem reter uma cópia no local?
- Os usuários locais precisam de acesso simultâneo aos dados de origem ou de resultado?
- Em caso afirmativo, eles podem operar os dados no Azure ou precisam que eles sejam armazenados localmente?
Se os dados precisam ser mantidos no local, qual é a quantidade de dados que precisa ser copiada para o Azure para a carga de trabalho? Quanto tempo você tem após os dados serem processados até que precise processar um novo conjunto de dados? Sua carga de trabalho será executada nesse período?
Você também precisa considerar a conectividade de rede com o Azure. Você só tem acesso ao Azure pela Internet? Essa limitação pode ser aceitável dependendo do tamanho dos dados a serem copiados/transferidos e do período entre as atualizações. Talvez você tenha uma grande quantidade de dados a serem copiados de cada vez. Você pode precisar de uma conexão WAN (rede de longa distância) com o Azure que use o Azure ExpressRoute, que forneceria mais largura de banda para copiar/transferir os dados.
Se você já tem uma conexão do ExpressRoute com o Azure, esta é a próxima consideração: quanto da conexão está disponível para sua operação de cópia de dados? Se o link estiver muito saturado, talvez seja necessário considerar a hora do dia em que os dados serão transferidos. Ou talvez você queira configurar uma conexão maior do ExpressRoute para acomodar transferências de dados grandes.
Se você mover os dados para o Azure, talvez precise considerar como os protegerá. Por exemplo, você pode ter um ambiente de NFS local que usa um serviço de diretório que ajuda a estender permissões para os usuários. Se você planeja copiar essa segurança para o Azure, precisa decidir se precisa de um serviço de diretório como parte da construção do Azure. Mas se a carga de trabalho é restrita ao cluster de HPC e os resultados são transferidos de volta para o ambiente local, você pode omitir esses requisitos.
Em seguida, consideramos os métodos para acessar dados: cache, cópia e sincronização.
Cache, cópia e sincronização
Vamos discutir as abordagens gerais que você pode adotar para adicionar dados ao Azure. O foco dessa discussão sobre transferência de dados são dados ativos, não o arquivo e o backup de dados.
Presuma que os dados transferidos nesta discussão sejam o conjunto de trabalho de uma carga de trabalho de HPC. Em um ambiente de HPC de ciências biomédicas, pode haver dados de origem como dados brutos de genoma, binários usados para processar esses dados ou dados complementares, como genomas de referência. Eles precisam ser processados imediatamente após a chegada ou não muito depois. Os dados também precisam ser armazenados em mídias que têm o perfil de desempenho apropriado em termos de IOPS, latência, taxa de transferência e custo. Em comparação, dados de arquivos/backup são transferidos com mais frequência para a solução de armazenamento com custo mais baixo possível, que não se destina a acesso de alto desempenho.
Os principais métodos de transferência de dados ativos são o cache, a cópia e a sincronização. Vamos discutir os prós e contras de cada abordagem, começando com a cópia.
A cópia é a abordagem mais comum à movimentação de dados. Os dados são copiados de várias maneiras, dependendo da ferramenta usada.
Considere estes fatores:
- O tamanho dos arquivos.
- O número de arquivos.
- A quantidade de taxa de transferência disponível para transferir os dados.
- O tempo que você tem para fazer a transferência.
Você precisa apenas de uma ferramenta de cópia básica como o cp se está transferindo alguns arquivos de tamanho razoável para um destino remoto. Provavelmente, você desejará usar scp em vez de cp se estiver transferindo dados usando redes que não são seguras: scp fornece criptografia por meio de uma conexão SSH (Secure Shell).
Há muitas abordagens para a otimização das operações de cópia dependendo de onde você pretende copiar os dados. Ao copiar arquivos diretamente para cada computador de HPC, você pode agendar operações de cópia individuais em cada nó, por exemplo.
Uma consideração ao copiar dados entre links de WAN é a quantidade de arquivos e pastas que estão sendo copiados. Se você está copiando muitos arquivos pequenos, é preferível combinar o uso da cópia com um arquivo como tar, para remover a sobrecarga de metadados do link WAN. Copie o arquivo .tar para o Azure e depois copie os dados para os computadores.
Outro problema com a cópia envolve o risco de interrupção. Por exemplo, se você está tentando copiar um arquivo grande e há erros de transmissão, usar cp não funciona porque ele não pode retomar a cópia de onde parou.
Uma preocupação final ao copiar dados é que sua cópia pode ficar obsoleta. Por exemplo, você pode copiar um conjunto de dados para o Azure. Enquanto isso, o usuário local pode ter atualizado um ou mais dos arquivos de origem. Você precisa determinar um processo para garantir que está usando os dados corretos.
A sincronização de dados é uma forma de cópia, mas é mais sofisticada. Ferramentas como rsync adicionam a capacidade de sincronizar dados entre a origem e o destino, além de copiá-los da origem. rsync garante que os arquivos estejam atualizados com base no tamanho e nas datas de modificação do arquivo. A sincronização permite que você minimize a possibilidade de usar arquivos obsoletos.
rsync tem capacidade de recuperação. Por exemplo, se você estiver copiando um arquivo grande e tiver problemas de transmissão, rsync poderá retomar de onde parou.
rsync é gratuito e fácil de implementar. Ele tem recursos além dos descritos aqui. Ele permite que você estabeleça um sistema de arquivos sincronizado no Azure com base nos dados locais.
rsync também tem limitações que devemos mencionar. Primeiro, a ferramenta é de thread único. Ela pode executar apenas uma operação de cada vez e não pode paralelizar o acesso a dados. O utilitário de cópia cp também é de thread único. Portanto, essas ferramentas não são otimizadas para operações de cópia/sincronização de grande escala que envolvem grandes quantidades de dados e uma janela de tempo pequena. Além disso, você precisa executar a ferramenta para sincronizar dados. Executar a ferramenta adiciona complexidade ao seu ambiente porque você precisa garantir que ela esteja sendo executada de acordo com seus requisitos de cronograma. Você pode querer agendar um script que inclui rsync, por exemplo. Essa abordagem requer que você adicione registro em log ao script, caso haja problemas. Isso também significa que você precisa estar atento a problemas. O nível de complexidade pode aumentar rapidamente.
Se você está executando uma solução de NAS comercial, há ferramentas de sincronização no nível do servidor que você pode comprar que são muito mais sofisticadas e oferecem desempenho com múltiplos threads. Após habilitadas e configuradas, essas ferramentas estão sempre em operação, sincronizando dados entre uma ou mais origens e destinos.
A cópia e a sincronização transmitem cópias completas dos dados de origem. A transmissão completa de arquivos pode ser adequada para conjuntos de arquivos ou tamanhos de arquivo menores. Ela pode apresentar atrasos significativos se os dados de origem são compostos por muitos arquivos grandes. Quanto mais dados você transfere, mais tempo a transferência leva. A sincronização garante que você esteja adicionando somente arquivos novos à nuvem. Mas esses arquivos ainda precisam ser transmitidos completamente. Em alguns casos, sua carga de trabalho de HPC pode não exigir a totalidade de um determinado conjunto de arquivos. Ela pode exigir acesso apenas a áreas específicas de arquivos.
O cache de dados é uma terceira abordagem à adição de dados ao Azure. Armazenar em cache refere-se à recuperação e à apresentação de dados de arquivos por meio de um cache. O cache pode ficar localizado em clientes locais individuais ou pode ser um cache distribuído que atende a todos os computadores de HPC. Normalmente, os caches são usados para minimizar a latência, de modo que colocar um cache em um limite de latência é uma abordagem ideal para servir dados. Por exemplo, você pode armazenar em cache solicitações de dados por meio de uma conexão WAN colocando um cache distribuído na computação do Azure que esteja conectado ao armazenamento local por meio do link WAN.
Neste módulo, estamos nos referindo especificamente ao cache de arquivos, em que o próprio cache atende a solicitações dos computadores. Ele recupera os dados de um ambiente de armazenamento de back-end (como um ambiente NAS de NFS) e apresenta esses dados aos clientes.
O poder do cache é duplo. Primeiro, os caches não recuperam arquivos inteiros. Um cache recupera um subconjunto, ou intervalo de bytes, solicitado dos arquivos, em vez dos arquivos inteiros. A recuperação é baseada nas solicitações de cliente para esses intervalos de bytes. Essa abordagem de recuperação minimiza os prejuízos sofridos pelo desempenho ao recuperar a totalidade de um arquivo grande quando apenas uma pequena seção dele é necessária.
Segundo, os caches otimizam o acesso repetido a dados solicitados com frequência. Quando um intervalo de bytes estiver no cache, solicitações posteriores desses dados serão rápidas. A única recuperação lenta é a primeira. Você pode obter benefícios significativos ao executar muitos clientes/threads de HPC que estão acessando um conjunto comum de arquivos.
O cache oferece outra vantagem para cenários híbridos. Os dados são armazenados no Azure (no cache) somente de maneira transitória. E eles são armazenados somente pela operação da carga de trabalho de HPC. Portanto, você pode reduzir a sobrecarga logística envolvida na movimentação de dados mais concreta para o Azure. Você pode isolar as preocupações com privacidade e segurança de dados para o cache e os computadores de HPC em si.
Por fim, determinadas soluções de cache oferecem o que é chamado de verificação de atributo. Semelhante à sincronização, o cache verifica periodicamente os atributos do arquivo na origem e recupera os intervalos de bytes em que a modificação do arquivo é maior na origem. Essa arquitetura garante que seu ambiente de HPC esteja sempre operando com os dados mais recentes.