Data and technical architecture
This section describes the data and technical architecture of Fast Interoperability Healthcare Resources (FHIR). It also provides details of how the FHIR service in Azure Health Data Services implements the FHIR API.
Data architecture
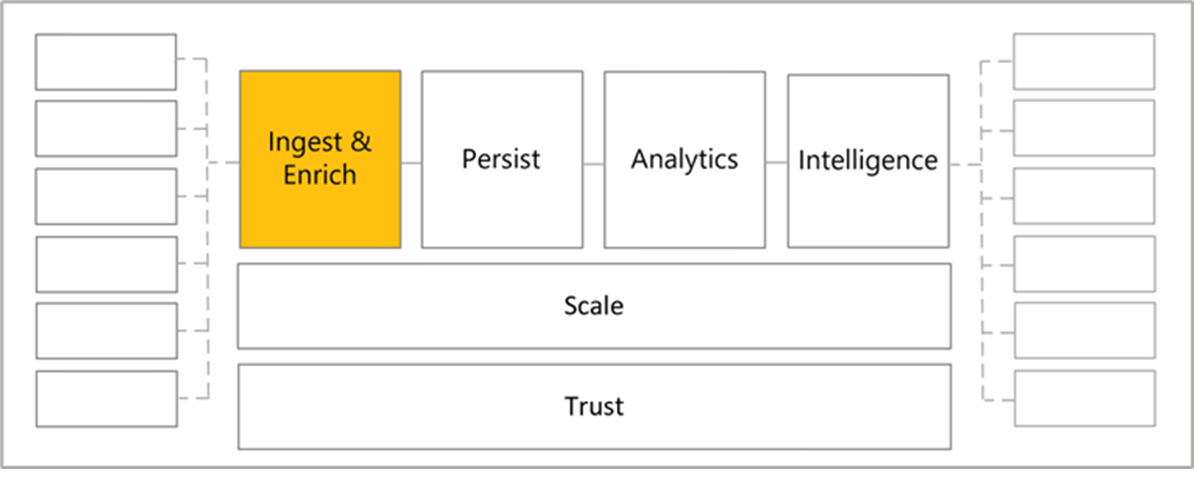
As health data is transformed and consumed, some common patterns and structure emerge, as shown in the following figure. You unify this disparate collection of healthcare data on Azure by using Azure Health Data Services. Then, the system ingests and persists data from the various data sources. Next, the system analyzes the data, and then it applies intelligence to help you gain a deeper understanding of this data.

You can extract the data from the FHIR service and then further integrate it with the Microsoft ecosystem to build analytical workflows. You can access the data that you persist in the FHIR service with an enterprise grade API endpoint.
Technical architecture
Secure and efficient management of health data is critical for healthcare organizations. FHIR service provides a powerful platform that organizations can use to store, process, and analyze sensitive data while adhering to stringent security and compliance standards.
In this section, you explore the technical architecture of Azure Health Data Services and learn about some primary functions in more detail. This view is of a common, real-world architecture of a healthcare solution that includes the functional building blocks of Ingest, Persist, Analyze, and Intelligence. Not all solutions require every block in this diagram.

This reference architecture demonstrates how you can connect the various components to address an organization's unique health data challenges. For more information, see Solutions for Healthcare.
Ingest
The Ingest function allows you to take data from different sources and then load the data into Azure Health Data Services. As you build your solution architecture, the ingestion requirement is a good place to start evaluating your needs.
The $convert-data operation that's built into the FHIR service is useful for converting health data from legacy formats into FHIR. The $convert-data operation in the FHIR service allows you to convert health data from various formats into FHIR R4 data. The $convert-data operation uses Liquid templates from the FHIR Converter project for FHIR data conversion. You can customize these conversion templates as needed.
The $convert-data operation supports four types of data conversion:
- HL7v2 to FHIR R4
- C-CDA to FHIR R4
- JSON to FHIR R4 (intended for custom conversion mappings)
- FHIR STU3 to FHIR R4
Additionally, you can customize these templates. For more information, see Transform HL7v2 data to FHIR® R4 with $convert-data and Azure Data Factory.
The system returns the FHIR bundle for further validation, if necessary, before it persists in the FHIR service. Keep in mind that the $convert-data operation doesn't persist the data in FHIR service. That step needs to happen after conversion.
After the system converts the data into the FHIR format, you can ingest the data into the FHIR service by using the $import operation or API endpoint. Using the $import operation is a recommended approach. The following diagram illustrates the convert data process.
Import operation
The Import operation allows you to load Fast Healthcare Interoperability Resources (FHIR) data to the FHIR server at high throughput. The FHIR service Import operation ingests data into the FHIR service from a storage account.
The import operation supports two modes: initial and incremental. Each mode has different features and use cases.
Initial mode
Is intended for loading FHIR resources into an empty FHIR server.
Supports only create operations and (when enabled) blocks API writes to the FHIR server.
Incremental mode
Is optimized for loading data into the FHIR server periodically and doesn't block writes through the API.
Allows you to load lastUpdated and versionId values from resource metadata if they're present in the resource JSON.
Allows you to load resources in a nonsequential order of versions.
Allows you to ingest soft-deleted resources. This capability is beneficial when you migrate from Azure API for FHIR to the FHIR service in Azure Health Data Services.
The following table shows the difference between import modes.
| Areas | Initial mode | Incremental mode |
|---|---|---|
| Capability | Initial load of data into FHIR service | Continuous ingestion of data into FHIR service (Incremental or Near Real Time). |
| Concurrent API calls | Blocks concurrent write operations | You can ingest data concurrently while implementing API CRUD operations on the FHIR server. |
| Ingestion of versioned resources | Not supported | Allows ingestion of multiple versions of FHIR resources in a single batch while maintaining resource history. |
| Retain lastUpdated field value | Not supported | Retain the lastUpdated field value in FHIR resources during the ingestion process. |
To configure import on the FHIR service, see Executing the import by invoking $import operation on FHIR service in Azure Health Data Services.
Health care organizations that use Azure Health Data Services and the FHIR service often need to run synchronous and asynchronous data flows simultaneously. The asynchronous data flow includes receiving batches of large datasets that contain patient records from various sources, such as EMR systems. You need to import these datasets into a FHIR server to ensure that comprehensive patient information is available. Make sure that you complete this import simultaneously with the synchronous data flow to concurrently run API CRUD (Create, Read, Update, Delete) operations on Azure Health Data Services FHIR service. Concurrently performing data import and API CRUD operations on the FHIR server is crucial to ensure uninterrupted healthcare service delivery and efficient data management.
After the system ingests the data into the FHIR service successfully, it persists the data in the FHIR store.
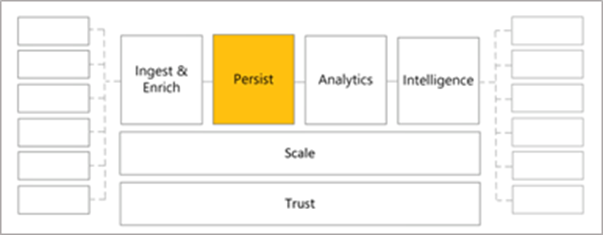
Persist
To persist data means to store the data on a server for access of data by using REST API calls.
The FHIR specification defines an API for querying resources in a FHIR server database. FHIR services support multiple HTTP verbs for querying the data, such as GET, POST, PUT, UPDATE, DELETE, and PATCH. FHIR specification, namely CONDITIONAL DELETE and CONDITIONAL PATCH, is also supported.
FHIR service supports the querying of persisted data through the search parameters. The FHIR API specifies a rich set of search parameters for fine-tuning search criteria. Each resource in FHIR carries information as a set of elements, and search parameters work to query the information in these elements. In a FHIR search API call, if the system finds a positive match between the request's search parameters and the corresponding element values that are stored in a resource instance, then the FHIR server returns a bundle. This bundle contains one or more resource instances whose elements satisfied the search criteria. For more information about supported search parameters and data type modifiers, see Overview of FHIR search in Azure Health Data Services.
FHIR service allows you to create custom search parameters in case you come across the scenario where you might want to search against an element in a resource that the FHIR specification doesn't define as a standard search parameter. For more information on adding custom search parameters, see How to do custom search in FHIR service.
FHIR service also provides support for searching by using operations. Operations follow the same security requirements as the Restful API endpoint. Furthermore, an open source project, Azure Health Data Services Toolkit, can help organizations extend the functionality of Azure Health Data services by providing a consistent toolset to build custom operations to modify the core service behavior. This toolkit abstracts common patterns so that you can focus on delivering your use cases.
Custom operations are purpose-built solutions that act as a proxy for a single or small set of HTTP endpoints. This toolkit simplifies the process of developing these solutions. The toolkit is the new approach for the deprecated FHIR Proxy.
The following architecture is a sample of how you could deploy and integrate custom operations that are built with the Azure Health Data Services toolkit in a production environment with Azure Health Data Services.

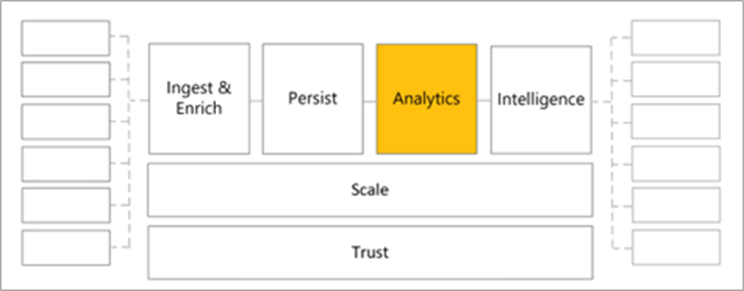
Analytics
In the context of Azure Health Data Services, you can manage analytics through de-identifying and exporting FHIR data for use in the broader Azure data processing ecosystem (such as Microsoft Azure Synapse or Microsoft Azure Machine Learning). Secondary use of health data is defined as a "non-direct care use of PHI for things like analytics, research, public health provider certification," and so on. Analytics uses the data that you persist in the FHIR® service to solve organizational problems and allow for better health outcomes.
The FHIR service supports the $export operation specified by HL7 for exporting FHIR data from a FHIR server. In the FHIR service implementation, calling the $export endpoint causes the FHIR service to export data into a preconfigured Azure storage account. The FHIR® service can de-identify data when you run an $export operation. For a de-identified export, the FHIR service uses the anonymization engine from the FHIR tools for anonymization (OSS) project on GitHub.
The following examples show the use of the $export operation for different scopes of resources on the FHIR service:
System -
GET https://<<FHIR service base URL>>/$export>>Patient -
GET https://<<FHIR service base URL>>/Patient/$export>>Group of patients -
GET https://<<FHIR service base URL>>/Group/[ID]/$export>>
For more information, see Export your FHIR data by invoking the $export command on the FHIR service.
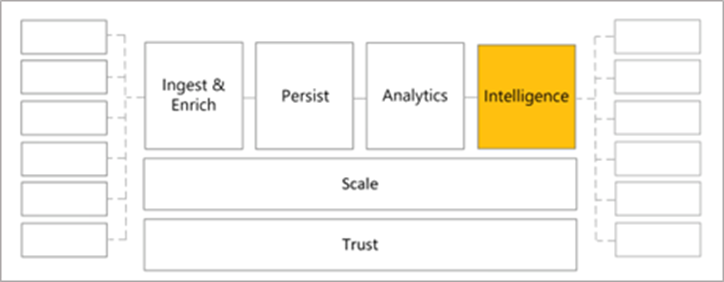
Intelligence
The Intelligence stage in a health data architecture is the part of the process where the system uses AI to extract health insights from the data. This AI could include Azure Machine Learning, Microsoft Azure Cognitive Search, Microsoft Azure Cognitive Services, AI Builder, or similar AI components.
By using pretrained and extensively validated AI/ML models, you can analyze and support clinical and operational use cases. In the next section, you explore these options with healthcare data solutions in Microsoft Fabric.