Entender o processo de ciência de dados
Uma maneira comum de extrair insights de dados é visualizar os dados. Sempre que você tiver conjuntos de dados complexos, convém aprofundar-se e tentar encontrar padrões intrincados nos dados.
Como cientista de dados, você pode treinar modelos de machine learning para encontrar padrões em seus dados. Você pode usar esses padrões para gerar novos insights ou previsões. Por exemplo, você pode prever o número esperado de produtos que espera vender na próxima semana.
Embora o treinamento do modelo seja importante, ele não é a única tarefa em um projeto de ciência de dados. Antes de explorar um processo típico de ciência de dados, vamos explorar modelos comuns de machine learning que você pode treinar.
Explorar modelos de machine learning comuns
O objetivo do aprendizado de máquina é treinar modelos que possam identificar padrões em grandes quantidades de dados. Esses padrões podem ser usados para fazer previsões que fornecem novos insights com base nos quais é possível realizar ações.
As possibilidades com o aprendizado de máquina podem parecer infinitas, portanto, vamos começar com o reconhecimento dos quatro tipos comuns de modelos de machine learning:
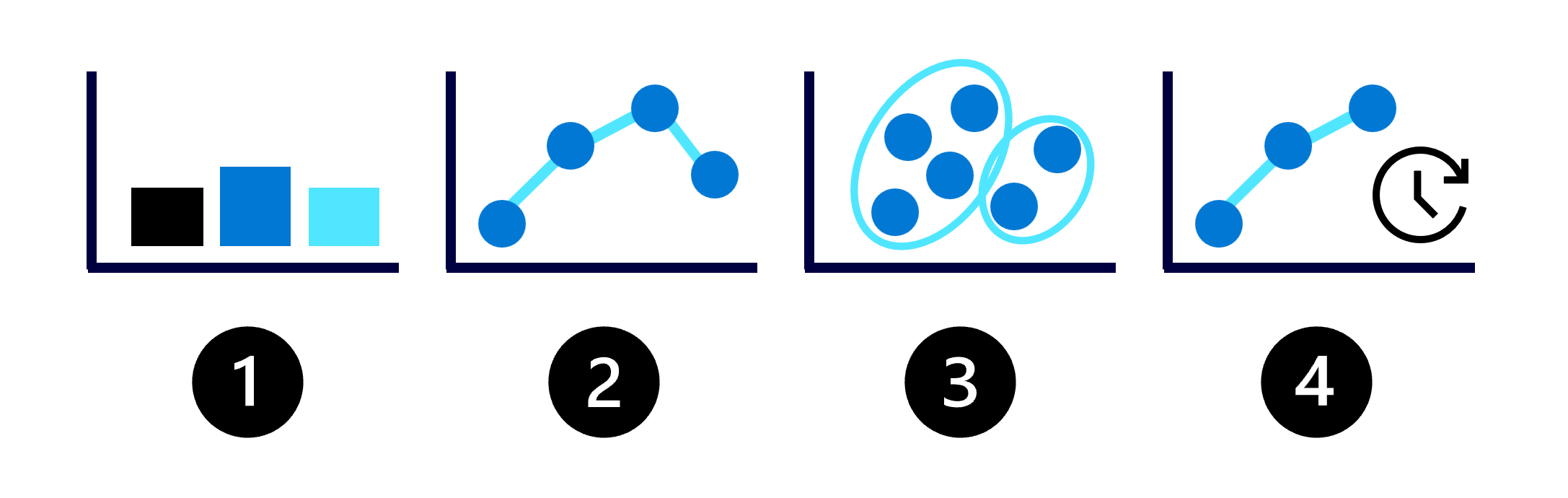
- Classificação: preveja um valor categórico, como a possibilidade de perda de um cliente.
- Regressão: preveja um valor numérico, como o preço de um produto.
- Clustering: agrupe pontos de dados semelhantes em clusters ou grupos.
- Previsão: preveja valores numéricos futuros com base em dados de séries temporais, como as vendas esperadas para o próximo mês.
Para decidir qual tipo de modelo de machine learning você precisa treinar, primeiro entenda qual é o problema de negócios e quais são os dados disponíveis.
Entender o processo de ciência de dados
Para treinar um modelo de machine learning, o processo geralmente envolve as seguintes etapas:

- Definir o problema: com usuários empresariais e analistas, decida o que o modelo deve prever e quando ele é bem-sucedido.
- Obter os dados: encontre fontes de dados e obtenha acesso armazenando dados em um lakehouse.
- Preparar os dados: explore os dados lendo-os de um lakehouse em um notebook. Limpe e transforme os dados com base nos requisitos do modelo.
- Treinar o modelo: escolha um algoritmo e valores de hiperparâmetros com base em tentativa e erro, acompanhando os experimentos com o MLflow.
- Gerar insights: use a pontuação em lote do modelo para gerar as previsões solicitadas.
Como cientista de dados, a maior parte do seu tempo será gasta preparando os dados e treinando o modelo. A maneira como você prepara os dados e o algoritmo escolhido para treinar um modelo podem influenciar o sucesso do modelo.
É possível preparar e treinar um modelo usando bibliotecas de código aberto disponíveis para sua linguagem preferencial. Por exemplo, se você trabalha com Python, é possível preparar os dados com Pandas e Numpy e treinar um modelo com bibliotecas como Scikit-Learn, PyTorch ou SynapseML.
Ao realizar experimentos, mantenha uma visão geral de todos os diferentes modelos treinados. Entenda como suas escolhas influenciam o sucesso do modelo. Acompanhando seus experimentos com MLflow no Microsoft Fabric, você poderá gerenciar e implantar facilmente os modelos que treinou.