Identificar planos de consulta problemáticos
O caminho que a maioria dos DBAs usa para solucionar problemas com desempenho é primeiro identificar a consulta com problemas (normalmente é a consulta que consome a maior quantidade de recursos do sistema) e recuperar o plano de execução dessa consulta. Há dois cenários. Uma delas é que a consulta tem um desempenho consistentemente ruim. Um baixo desempenho consistente pode ser causado por alguns problemas diferentes, incluindo restrições de recursos de hardware (embora essa situação normalmente não afete uma só consulta executada isoladamente), estrutura de consulta de qualidade inferior, configurações de compatibilidade de banco de dados, índices ausentes ou uma escolha ruim de plano pelo otimizador de consulta. O segundo cenário é que a consulta tem um bom desempenho em algumas execuções, mas não em outras. Esse problema pode ser causado por alguns outros fatores, sendo a distorção de dados o mais comum em uma consulta parametrizada que tenha um plano eficiente para algumas execuções e um insatisfatório para outras. Os outros fatores comuns no desempenho de consultas inconsistente são o bloqueio, em que uma consulta está aguardando a conclusão de outra para obter acesso a uma tabela, ou a contenção de hardware.
Vamos examinar cada um desses possíveis problemas com mais detalhes.
Restrições de hardware
Normalmente, as restrições de hardware não se manifestarão em execuções de consultas únicas, mas ficarão evidentes quando a carga de produção for aplicada e houver um número limitado de threads de CPU e uma quantidade limitada de memória a serem compartilhados entre as consultas. Quando há contenção de CPU, ela normalmente será detectável pela observação do contador de monitoramento de desempenho ‘%Processor Time’, que mede o uso da CPU pelo servidor. Olhando mais atentamente o SQL Server, você poderá ver os tipos de espera SOS_SCHEDULER_YIELD e CXPACKET quando o servidor estiver sob pressão da CPU. No entanto, em alguns casos com desempenho insatisfatório do sistema de armazenamento, até mesmo execuções únicas de uma consulta que de outra forma são otimizadas podem ser lentas. O melhor acompanhamento do desempenho do sistema de armazenamento é no nível do sistema operacional, usando os contadores de monitoramento de desempenho ‘Disk Seconds/Read’ e ‘Disk Seconds/Write’, que medem quanto tempo demora para uma operação de E/S ser concluída. O SQL Server gravará em seu log de erros se detectar um desempenho de armazenamento insatisfatório (se uma E/S demorar mais de 15 segundos para ser concluída). Se você examinar as estatísticas de espera e vir uma alta porcentagem de esperas de PAGEIOLATCH_SH em seu SQL Server, talvez veja um problema de desempenho do sistema de armazenamento. Normalmente, o desempenho do hardware é examinado de modo geral, no início do processo de solução de problemas de desempenho, pois é relativamente fácil de avaliar.
A maioria dos problemas de desempenho de banco de dados pode ser atribuída a padrões de consulta de qualidade inferior, mas em muitos casos a execução de consultas ineficientes colocará uma pressão indevida sobre seu hardware. Por exemplo, os índices ausentes podem levar à demanda de CPU, armazenamento e memória com a recuperação de mais dados do que o necessário para processar a consulta. É recomendável que você resolva consultas de qualidade inferior e as ajuste antes de resolver problemas de hardware. Vamos começar a examinar o ajuste de consulta a seguir.
Construções de consulta de qualidade inferior
Os bancos de dados relacionais têm melhor desempenho quando executam operações baseadas em conjuntos. As operações baseadas em conjuntos executam a manipulação de dados (INSERT, UPDATE, DELETE e SELECT) em conjuntos, nos quais o trabalho é feito em um conjunto de valores e produz um único valor ou conjunto de resultados. A alternativa às operações baseadas em conjuntos é a execução do trabalho baseado em linhas, usando um cursor ou um loop while. Esse tipo de processamento é conhecido como processamento baseado em linha, e seu custo aumenta linearmente com o número de linhas afetadas. Essa escala linear é problemática à medida que os volumes de dados aumentam em um aplicativo.
Embora seja importante detectar o uso inferior de operações baseadas em linhas com cursores ou loops WHILE, há outros antipadrões do SQL Server que você pode reconhecer. As TVFs (funções com valor de tabela), especialmente funções com valor de tabela com várias instruções, causaram padrões problemáticos de plano de execução antes do SQL Server 2017. Muitos desenvolvedores gostam de usar funções com valor de tabela com várias instruções, pois podem executar várias consultas dentro de uma única função e agregar os resultados em uma única tabela. No entanto, qualquer pessoa que programe T-SQL precisa estar ciente das possíveis penalidades de desempenho no uso de TVFs.
O SQL Server tem dois tipos de funções com valor de tabela: embutidas e de várias instruções. Se você usar uma TVF embutida, o mecanismo de banco de dados a tratará exatamente como uma exibição. As TVFs de várias instruções são tratadas como qualquer outra tabela no processamento de uma consulta. Como as TVFs são dinâmicas e, por isso, o SQL Server não tem estatísticas sobre elas, ele usou uma contagem fixa de linhas ao estimar o custo do plano de consulta. Uma contagem fixa pode não causar problemas quando o número de linhas é pequeno. No entanto, se a TVF retornar milhares ou milhões de linhas, o plano de execução poderá ser muito ineficiente.
Outro antipadrão tem sido o uso de funções escalares, que têm problemas de estimativa e de execução semelhantes. A Microsoft fez um aprimoramento significativo no desempenho com a introdução do Processamento de Consultas Inteligentes nos níveis de compatibilidade 140 e 150.
SARGability
O termo SARGável em bancos de dados relacionais se refere a um predicado (cláusula WHERE) em um formato específico que pode usar um índice para agilizar a execução de uma consulta. Os predicados no formato correto são chamados de “Argumentos de pesquisa”, ou SARGs. No SQL Server, o uso de um SARG significa que o otimizador avaliará o uso de um índice não clusterizado na coluna referenciada no SARG para uma operação SEEK em vez de verificar todo o índice (ou a tabela inteira) para recuperar um valor.
A presença de um SARG não garante o uso de um índice para um SEEK. Os algoritmos de custo do otimizador ainda poderiam determinar que o índice é muito caro. Isso pode ocorrer se um SARG se referir a um grande percentual de linhas em uma tabela. A ausência de um SARG significa que o otimizador nem sequer avaliará um SEEK em um índice não clusterizado.
Alguns exemplos de expressões que não são SARGs (às vezes chamadas de não sargáveis) são as que incluem uma cláusula LIKE com um curinga no início da cadeia de caracteres a ser correspondida, por exemplo, WHERE lastName LIKE ‘%SMITH%’. Outros predicados que não são SARGs ocorrem no uso de funções em uma coluna, por exemplo, WHERE CONVERT(CHAR(10), CreateDate,121) = ‘2020-03-22’. Essas consultas com expressões não sargáveis normalmente são identificadas pela verificação de tabela ou índice nos planos de execução nos quais as buscas deveriam estar ocorrendo.
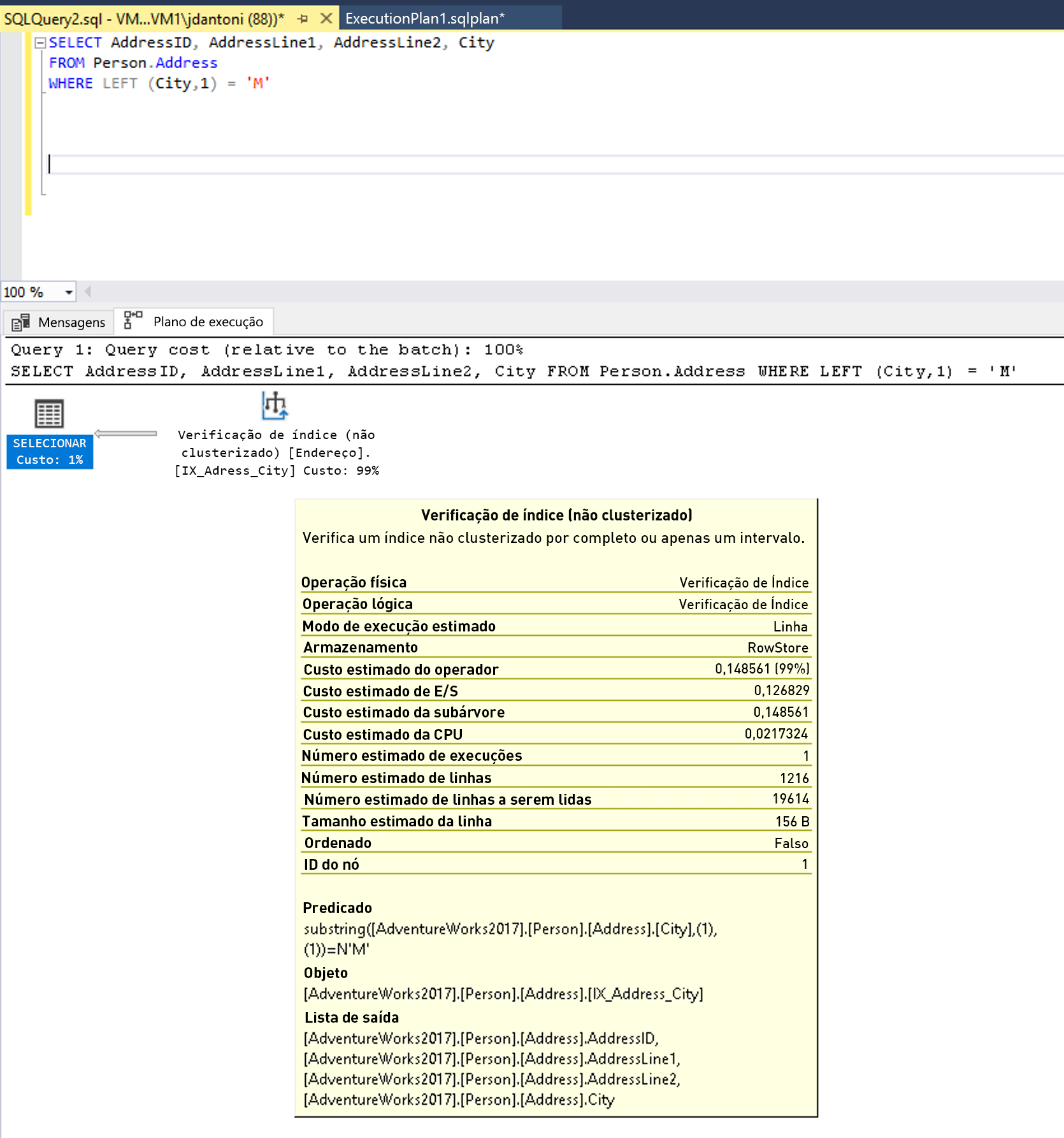
Há um índice na coluna City que está sendo usado na cláusula WHERE da consulta e, enquanto está sendo usado no plano de execução acima, você pode ver que o índice está sendo examinado, o que significa que todo o índice está sendo lido. A função LEFT no predicado torna essa expressão não SARGável. O otimizador não avaliará o uso de uma pesquisa de índice no índice da coluna City.
Essa consulta pode ser codificada para usar um predicado que seja SARGável. O otimizador, então, avaliaria um SEEK no índice da coluna City. Um operador de pesquisa de índice, nesse caso, leria um conjunto muito menor de linhas, como mostrado abaixo.
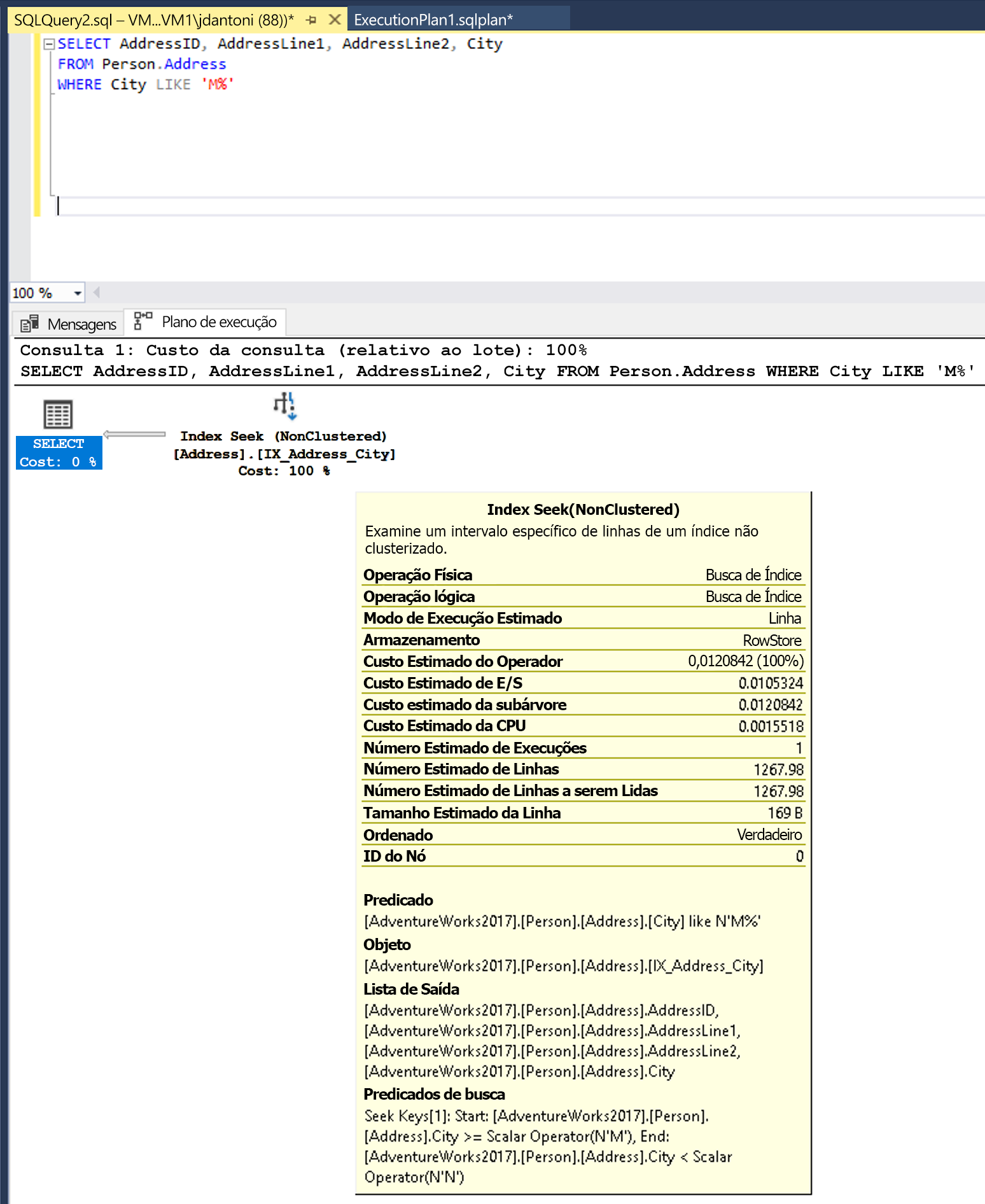
Alterar a função LEFT para um LIKE resulta em uma pesquisa de índice.
Observação
A palavra-chave LIKE, nessa instância, não tem um caractere curinga à esquerda e, portanto, está procurando cidades que comecem com M. Se fosse “bilateral” ou começasse com um caractere curinga ("%M%" ou "%M"), a propriedade SARG (Search ARGument, procurar argumento) não poderia ser usada. A estimativa da operação de busca é de retornar 1267 linhas, ou aproximadamente 15% da estimativa para a consulta com o predicado não SARGável.
Alguns outros antipadrões de desenvolvimento de banco de dados estão tratando o banco de dados como um serviço em vez de um armazenamento. O uso de um banco de dados para converter o JSON, a manipular cadeias de caracteres ou executar cálculos complexos pode levar ao uso excessivo da CPU e a uma maior latência. As consultas que tentam recuperar todos os registros e fazer cálculos no banco de dados podem levar ao uso excessivo de E/S e CPU. O ideal é que você use o banco de dados para operações de acesso a dados e constructos de banco de dados otimizados como agregação.
Índices ausentes
Os problemas de desempenho mais comuns que vemos como administradores de banco de dados são devido à falta de índices úteis, o que faz com que o mecanismo leia muito mais páginas do que o necessário para retornar os resultados de uma consulta. Embora os índices não sejam gratuitos em termos de recursos (a adição de mais índices a uma tabela pode afetar o desempenho de gravação e consumir espaço), os ganhos de desempenho que eles oferecem podem muitas vezes compensar os custos de recursos extra. Frequentemente, os planos de execução com esses problemas de desempenho podem ser identificados pelo operador de consulta Clustered Index Scan ou pela combinação de Nonclustered Index Seek e Key Lookup (que são mais indicativos de colunas ausentes em um índice existente).
O mecanismo de banco de dados tenta ajudar nesse problema indicando os índices ausentes nos planos de execução. Os nomes e os detalhes dos índices recomendados estão disponíveis por meio de uma exibição de gerenciamento dinâmico chamada sys.dm_db_missing_index_details. Também há outras DMVs no SQL Server como sys.dm_db_index_usage_stats e sys.dm_db_index_operational_stats, que realçam a utilização de índices existentes.
Pode fazer sentido descartar um índice que não seja usado por nenhuma consulta no banco de dados. Os DMVs de índice ausentes e os avisos de plano só devem ser usados como um ponto de partida para ajustar suas consultas. É importante entender quais são suas principais consultas e criar índices para dar suporte a essas consultas. Não é recomendável criar todos os índices ausentes sem avaliar índices no contexto uns dos outros.
Estatísticas ausentes e desatualizadas
Você aprendeu a importância das estatísticas de coluna e índice para o otimizador de consulta. Também é importante entender as condições que podem levar a estatísticas desatualizadas e como esse problema pode se manifestar no SQL Server. Por padrão, as ofertas do SQL do Azure têm a atualização de estatísticas definida como ATIVADO. Antes do SQL Server 2016, o comportamento padrão das estatísticas de atualização automática era não atualizar as estatísticas até que o número de modificações em colunas no índice fosse igual a cerca de 20% do número de linhas em uma tabela. Devido a esse comportamento, você pode ter modificações de dados que foram relevantes o suficiente para alterar o desempenho da consulta, mas sem a atualização das estatísticas. Qualquer plano que tenha usado a tabela com os dados alterados se baseará em estatísticas desatualizadas e, com frequência, será inferior.
Antes do SQL Server 2016, você tinha a opção de usar o sinalizador de rastreamento 2371, que alterou o número necessário de modificações para ser um valor dinâmico e, portanto, à medida que sua tabela cresceu, o percentual de modificações de linha necessário para disparar uma atualização de estatísticas ficou menor. As versões mais recentes do SQL Server, do Banco de Dados SQL do Azure e da Instância Gerenciada de SQL do Azure dão suporte a esse comportamento por padrão. Há também uma função de gerenciamento dinâmico chamada sys.dm_db_stats_properties, que mostra a última vez que as estatísticas foram atualizadas e o número de modificações feitas desde a última atualização, o que permite que você identifique rapidamente as estatísticas que talvez precisem ser atualizadas manualmente.
Opções de otimizador ruins
Embora o otimizador de consulta faça um bom trabalho para otimizar a maioria das consultas, há alguns casos de borda em que o otimizador baseado em custo pode tomar decisões impactantes que não são totalmente compreendidas. Há muitas maneiras de resolver isso, incluindo o uso de dicas de consulta, sinalizadores de rastreamento, imposição de plano de execução e outros ajustes para alcançar um plano de consulta estável e ideal. A Microsoft tem uma equipe de suporte que pode ajudar a solucionar esses cenários.
No exemplo abaixo do banco de dados AdventureWorks2017, uma dica de consulta está sendo usada para instruir o otimizador de banco de dados a usar sempre o nome de cidade Seattle. Essa dica não garantirá o melhor plano de execução para todos os valores de cidade, mas será previsível. O valo “Seattle” para @city_name será usado apenas durante a otimização. Durante a execução, o valor real fornecido (‘Ascheim’) será usado.
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Como visto no exemplo, a consulta usa uma dica (a cláusula OPTION) para instruir o otimizador a usar um valor de variável específico a fim de criar seu plano de execução.
Detecção de parâmetro
O SQL Server armazena em cache planos de execução de consulta para uso futuro. Como o processo de recuperação do plano de execução é baseado no valor de hash de uma consulta, o texto da consulta precisa ser idêntico em cada execução da consulta para o plano em cache a ser usado. Para dar suporte a vários valores na mesma consulta, muitos desenvolvedores usam parâmetros, transmitidos por meio de procedimentos armazenados, como visto no exemplo abaixo:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
As consultas também podem ser parametrizadas explicitamente com o procedimento sp_executesql. No entanto, a parametrização explícita de consultas individuais geralmente é feita por meio do aplicativo com alguma forma (dependendo da API) de PREPARE e EXECUTE. Quando o mecanismo de banco de dados executa essa consulta pela primeira vez, ele otimiza a consulta com base no valor inicial do parâmetro; nesse caso, 42. Esse comportamento, chamado de detecção de parâmetros, permite que a carga de trabalho geral das consultas de compilação seja reduzida no servidor. No entanto, se houver distorção de dados, o desempenho da consulta poderá variar muito.
Por exemplo, em uma tabela que tenha 10 milhões registros, 99% desses registros tenha uma ID de 1 e o restante 1% é de números exclusivos, o desempenho será baseado na ID usada inicialmente para otimizar a consulta. Esse desempenho com muita flutuação é um indício de distorção de dados e não é um problema inerente à detecção de parâmetros. Esse comportamento é um problema de desempenho bastante comum do qual você deve estar ciente. Você deve entender as opções para aliviar o problema. Há algumas maneiras de resolver esse problema, mas cada uma vem com compensações:
- Use a dica
RECOMPILEna sua consulta ou a opção de execuçãoWITH RECOMPILEnos seus procedimentos armazenados. Essa dica fará com que a consulta ou o procedimento seja recompilado toda vez que for executado, o que aumentará a utilização da CPU no servidor, mas sempre usará o valor do parâmetro atual. - Você pode usar a dica de consulta
OPTIMIZE FOR UNKNOWN. Essa dica fará com que o otimizador opte por não rastrear os parâmetros e compare o valor com o histograma de dados de coluna. Essa opção não obterá o melhor plano possível, mas permitirá um plano de execução consistente. - Reescreva o procedimento ou as consultas adicionando lógica em torno dos valores de parâmetro a fim de RECOMPILE apenas para parâmetros problemáticos conhecidos. No exemplo a seguir, se o parâmetro SalesPersonID for NULL, a consulta será executada com a
OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
O exemplo acima é uma boa solução, mas requer um esforço de desenvolvimento bem grande e uma ótima compreensão de sua distribuição de dados. Ele também poderá exigir manutenção à medida que os dados forem alterados.