Explicar os planos de consulta estimados e reais
O tópico de planos de execução real versus estimado pode ser confuso. A diferença é que o plano real inclui estatísticas de tempo de execução que não estão refletidas no plano estimado. Os operadores usados e a ordem de execução serão os mesmos do plano estimado em quase todos os casos. A outra consideração é que, para capturar um plano de execução real, a consulta precisa ser executada, o que pode ser demorado ou não ser possível. Por exemplo, a consulta pode ser uma instrução UPDATE que só pode ser executada uma vez. No entanto, se precisar ver os resultados da consulta e do plano, você precisará usar uma das opções de plano real.
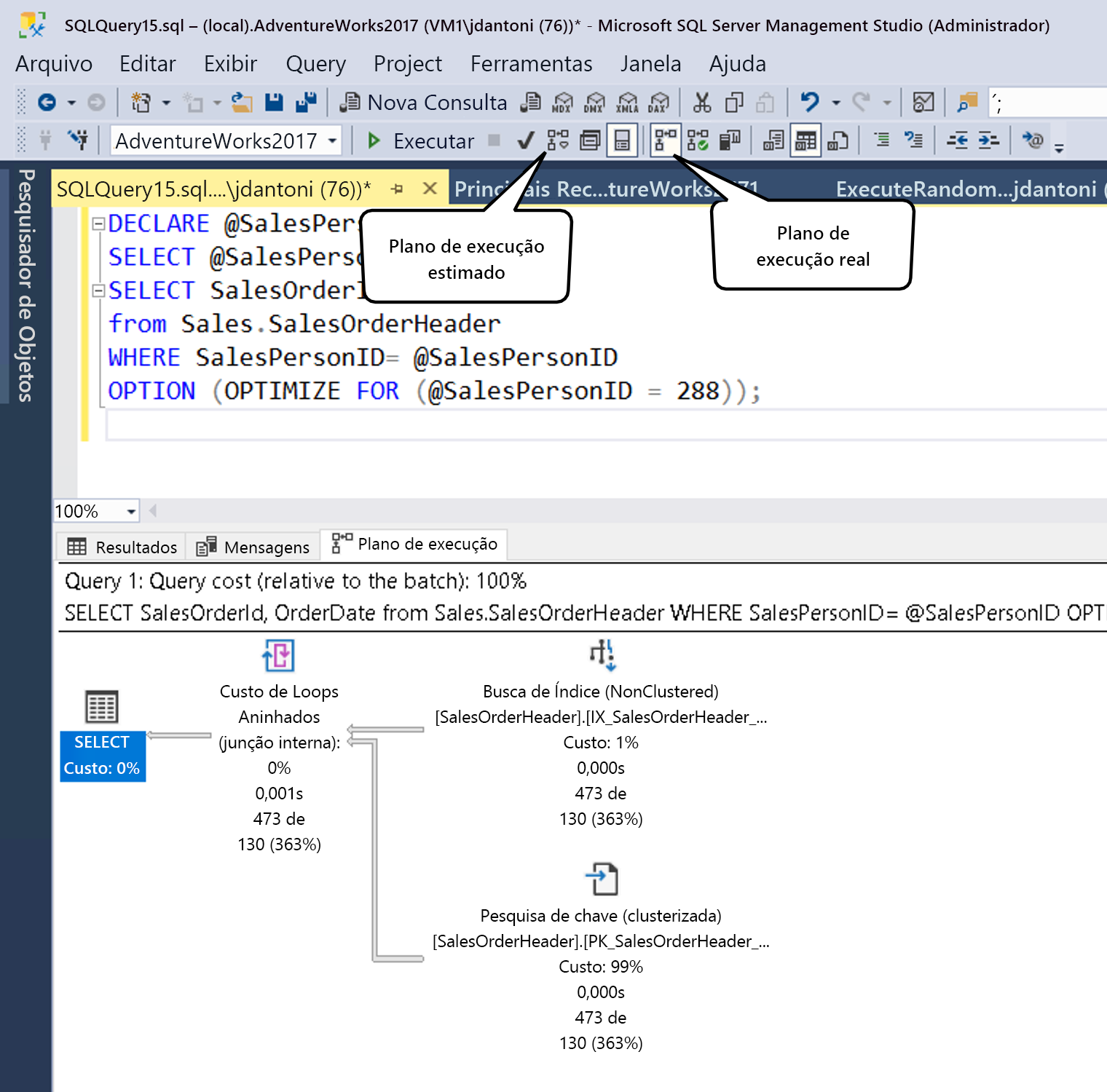
Como mostrado acima, você pode gerar um plano estimado no SSMS clicando no botão apontado pela caixa do plano de consulta estimado (ou usando o comando de teclado Ctrl+L). Você pode gerar o plano real clicando no ícone exibido (ou usando o comando de teclado Ctrl+M) e executando a consulta. Os dois botões de opção funcionam de maneira um pouco diferente. O botão Incluir Plano de Consulta Estimado responde imediatamente a qualquer consulta realçada (ou todo o espaço de trabalho, se nada estiver realçado), ao contrário do botão Incluir Plano de Consulta Real.
Há uma sobrecarga em executar uma consulta e gerar um plano de execução estimado, ou seja, a exibição de planos de execução deve ser feita com cuidado em um ambiente de produção.
Normalmente, você pode usar o plano de execução estimado enquanto escreve a consulta para entender suas características de desempenho, identificar índices ausentes ou detectar anomalias na consulta. O aproveitamento do plano de execução real é maior para entender o desempenho do tempo de execução da consulta e, o mais importante, as lacunas nos dados estatísticos que fazem com que o otimizador de consulta faça escolhas de qualidade inferior com base nos dados disponíveis.
Ler um plano de consulta
Os planos de execução mostram quais tarefas o mecanismo de banco de dados está executando ao recuperar os dados necessários para atender a uma consulta. Vamos nos aprofundar no plano.
Primeiro, a consulta em si é mostrada abaixo:
SELECT [stockItemName]
,[UnitPrice] * [QuantityPerOuter] AS CostPerOuterBox
,[QuantityonHand]
FROM [Warehouse].[StockItems] s
JOIN [Warehouse].[StockItemHoldings] sh ON s.StockItemID = sh.StockItemID
ORDER BY CostPerOuterBox;
Essa consulta está unindo a tabela StockItems à tabela StockItemHoldings, na qual os valores na coluna StockItemID são iguais. O mecanismo de banco de dados precisa primeiro identificar essas linhas antes de poder processar o restante da consulta.
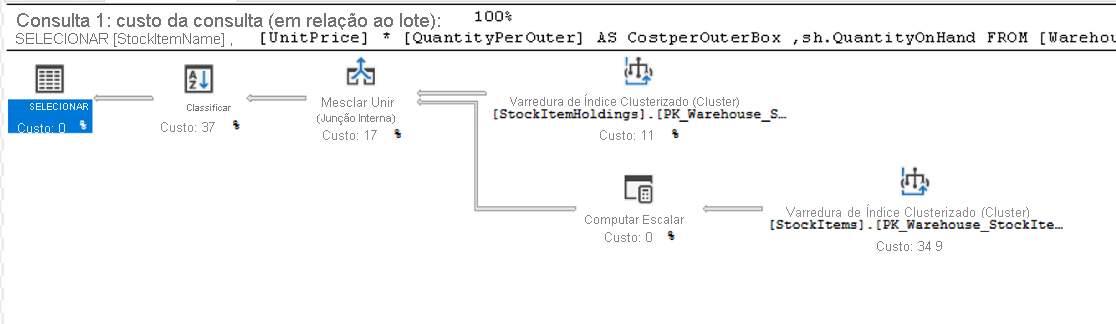
Cada ícone no plano mostra uma operação específica, que representa as várias ações e decisões que compõem um plano de execução. O mecanismo de banco de dados do SQL Server tem mais de 100 operadores de consulta que podem se transformar em um plano de execução. Você observará que, em cada ícone de operador, há um percentual de custo relativo ao custo total da consulta. Até mesmo uma operação que mostra um custo de 0% representa algum custo. Na verdade, 0% é geralmente devido ao arredondamento, pois os custos do plano gráfico são sempre mostrados como números inteiros e o percentual real é algo abaixo de 0,5%.
O fluxo de execução em um plano de execução é da direita para a esquerda e de cima para baixo, ou seja, no plano acima, a operação de Clustered Index Scan no índice clusterizado StockItemHoldings.PK_Warehouse_StockItemHoldings é a primeira operação na consulta. As larguras das linhas que conectam os operadores são baseadas no número estimado de linhas de dados que fluem em direção ao operador seguinte. Uma seta grossa é indicador de uma transferência grande de operador para operador e pode ser uma indicação de oportunidade para ajustar uma consulta. Você também pode manter o mouse sobre um operador e ver informações adicionais em uma dica de ferramenta, conforme mostrado abaixo.
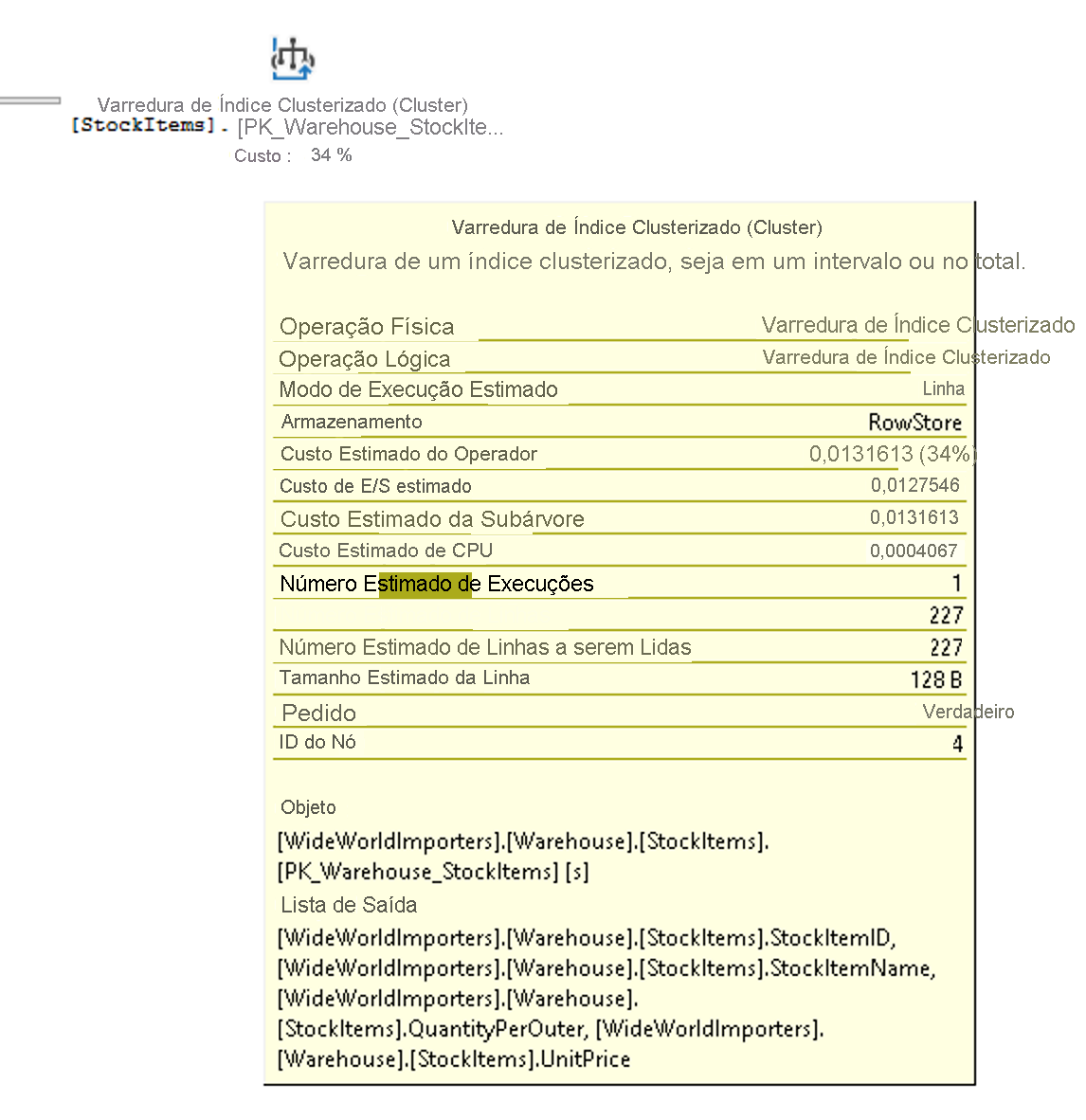
A dica de ferramenta realça o custo e as estimativas do plano estimado e, para um plano real, incluirá as comparações com as linhas e os custos reais. Cada operador também tem propriedades que mostrarão mais do que a dica de ferramenta. Se você clicar com o botão direito do mouse em um operador específico, poderá selecionar a opção Propriedades no menu de contexto para ver a lista completa de propriedades. Essa opção abrirá um painel Propriedades separado no SQL Server Management Studio, que, por padrão, fica no lado direito. Quando o painel Propriedades estiver aberto, um clique em algum operador preencherá a lista de propriedades com propriedades desse operador. Como alternativa, você pode abrir o painel Propriedades clicando em Exibir no menu principal do SQL Server Management Studio e escolhendo Propriedades.
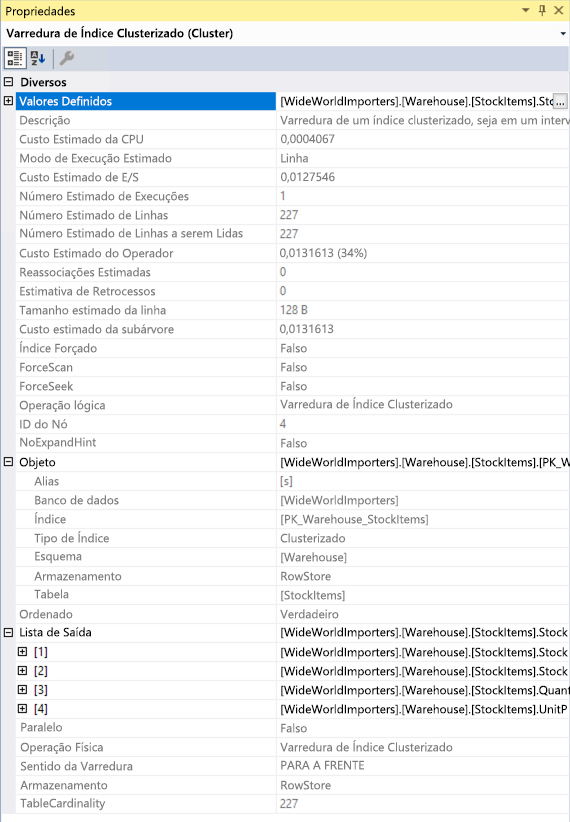
O painel Propriedades inclui algumas informações adicionais e mostra a lista de saída que fornece detalhes das colunas que estão sendo transmitidas ao operador seguinte. Essas colunas podem indicar que um índice não clusterizado é necessário para aprimorar o desempenho da consulta quando analisado com a verificação de índice clusterizado. Como uma operação de Clustered Index Scan está lendo a tabela inteira, pode ser mais eficiente, nesse cenário, ter um índice não clusterizado na coluna StockItemID em cada tabela.
Criação de perfil de consulta leve
Como mencionado acima, a captura de planos de execução reais, seja usando o SSMS, seja usando a infraestrutura de monitoramento de eventos estendidos, pode gerar uma grande quantidade de sobrecarga e normalmente é feito apenas em iniciativas de solução de problemas de sites ativos. A sobrecarga do observador, como é conhecida, é o custo de monitorar um aplicativo em execução. Em alguns cenários, esse custo pode ser apenas alguns pontos percentuais de utilização da CPU, mas em outros casos, como a captura de planos de execução reais, ele pode reduzir significativamente o desempenho individual da consulta. A infraestrutura de criação de perfil herdada no mecanismo do SQL Server poderia gerar até 75% de sobrecarga na captura de informações de consulta; já a infraestrutura de criação de perfil leve tem sobrecarga máxima de 2%.
Na primeira versão da criação de perfil leve, ela coletava informações de contagem de linhas e de utilização de E/S (o número de leituras e gravações lógicas e físicas executadas pelo mecanismo de banco de dados para atender a uma determinada consulta). Além disso, um novo evento estendido chamado query_thread_profile foi introduzido para permitir que os dados de cada operador em um plano de consulta sejam inspecionados. Na versão inicial da criação de perfil leve, o uso do recurso requer que o sinalizador de rastreamento 7412 esteja habilitado globalmente.
Em versões mais recentes (SQL Server 2016 SP2 CU3, SQL Server 2017 CU11 e SQL Server 2019), se a criação de perfil leve não estiver habilitada globalmente, você poderá usar a dica de consulta USE HINT com QUERY_PLAN_PROFILE para habilitar a criação de perfil leve no nível da consulta. Quando uma consulta que tem essa dica conclui sua execução, um evento estendido query_plan_profile é gerado, o que fornece um plano de execução real. Você pode ver um exemplo de uma consulta com esta dica:
SELECT [stockItemName]
,[UnitPrice] * [QuantityPerOuter] AS CostPerOuterBox
,[ QuantityonHand]
FROM [Warehouse].[StockItems] s
JOIN [Warehouse].[StockItems] sh ON s.StockItemID = sh.StockItemID
ORDER BY CostPerOuterBox
OPTION(USE HINT ('QUERY_PLAN_PROFILE'));
Estatísticas da última consulta de planos
O SQL Server 2019 e o Banco de Dados SQL do Azure dão suporte a dois aprimoramentos adicionais da infraestrutura de criação de perfil de consulta. Primeiro, a criação de perfil leve é habilitada por padrão no SQL Server 2019, no Banco de Dados SQL do Azure e na instância gerenciada. A criação de perfil leve também está disponível como uma opção de configuração no escopo do banco de dados, chamada LIGHTWEIGHT_QUERY_PROFILING. Com a opção no escopo do banco de dados, você pode desabilitar o recurso para todos os seus bancos de dados de usuário, independentemente uns dos outros.
Em segundo lugar, há uma nova função de gerenciamento dinâmico chamada sys.dm_exec_query_plan_stats, que pode mostrar o último plano de execução de consulta real conhecido para determinado identificador de plano. Para ver o último plano de consulta real conhecido usando a função, você pode habilitar o sinalizador de rastreamento 2451 em todo o servidor. Como alternativa, você pode habilitar essa funcionalidade usando uma opção de configuração no escopo do banco de dados chamada LAST_QUERY_PLAN_STATS.
Você pode combinar essa função com outros objetos a fim de obter o último plano de execução para todas as consultas em cache, conforme mostrado abaixo:
SELECT *
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS st
CROSS APPLY sys.dm_exec_query_plan_stats(plan_handle) AS qps;
GO
Essa funcionalidade permite identificar rapidamente as estatísticas de tempo de execução para a última execução de qualquer consulta em seu sistema, com sobrecarga mínima. A imagem abaixo mostra como recuperar o plano. Se você selecionar o XML do plano de execução, que será a primeira coluna de resultados, o plano de execução mostrado na segunda imagem abaixo será exibido.
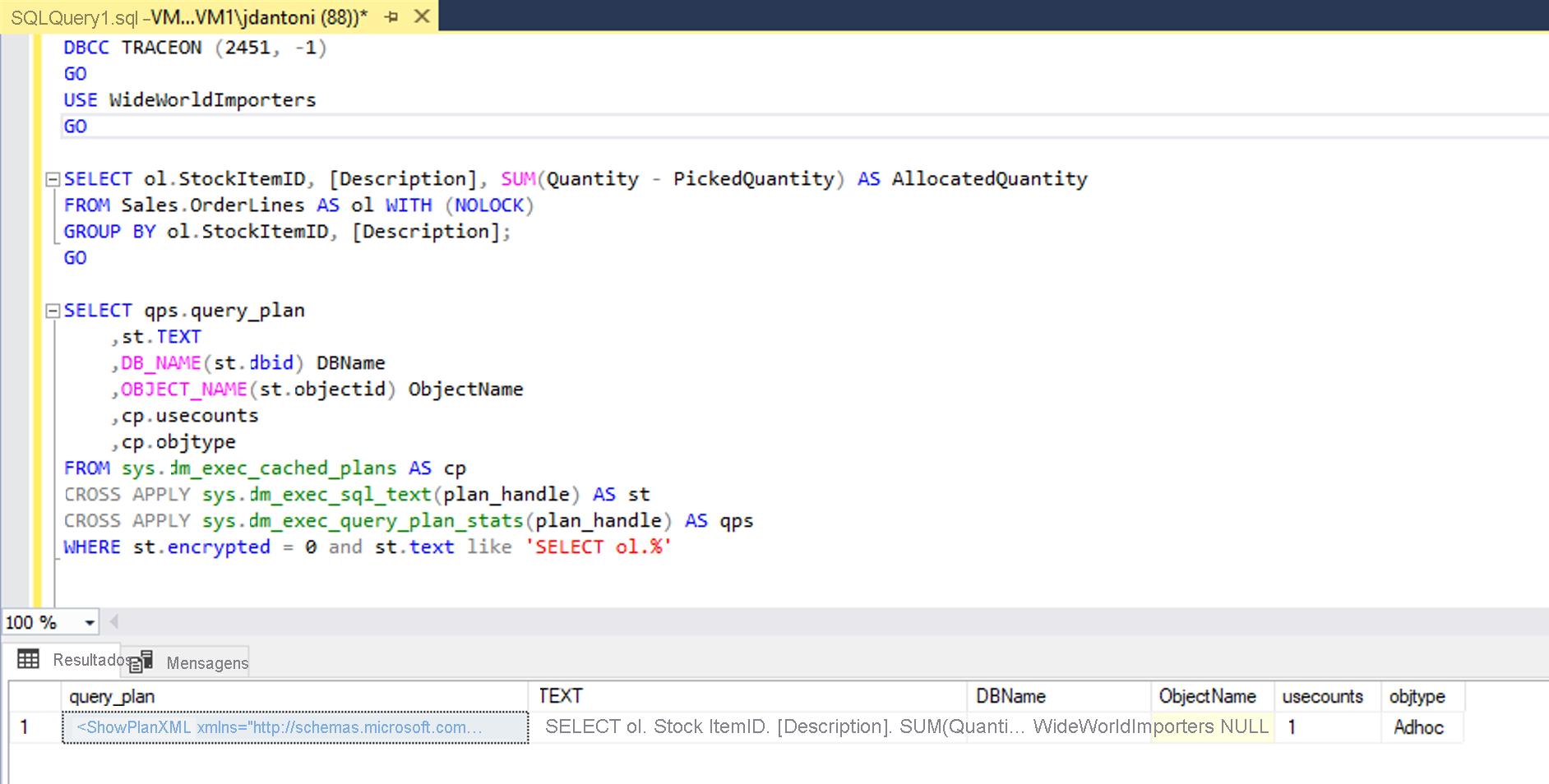
Como você pode ver nas propriedades da Verificação do Índice Columnstore, o plano recuperado do cache tem o número real de linhas recuperadas na consulta.
