Como uma consulta KQL é criada
Agora que você está familiarizado com o funcionamento das linguagens de consulta e ciente de onde o KQL pode ser usado, vamos explorar a maneira como uma consulta KQL é criada.
Considerações importantes sobre a estrutura de consulta KQL
Uma consulta de KQL é uma solicitação somente leitura para processar dados e retornar resultados. A solicitação é declarada em texto sem formatação, usando um modelo de fluxo de dados fácil de ler, criar e automatizar.
Linguagens de consulta diferentes geralmente têm estruturas diferentes. O KQL é organizado com base na maneira como os dados são processados. Cada consulta KQL começa com a fonte de dados. Em seguida, os dados são processados passando por condições, ordenados e reduzidos ainda mais com um filtro.
Processamento de dados
Imagine que os dados trafeguem por um funil de processamento de dados. A entrada tabular é o início do funil de dados. Esses dados são canalizados para a próxima linha e filtrados ou manuseados usando um operador. Os dados sobreviventes são canalizados para a linha subsequente e assim por diante até chegar à saída final da consulta. Essa saída de consulta é retornada em um formato tabular.
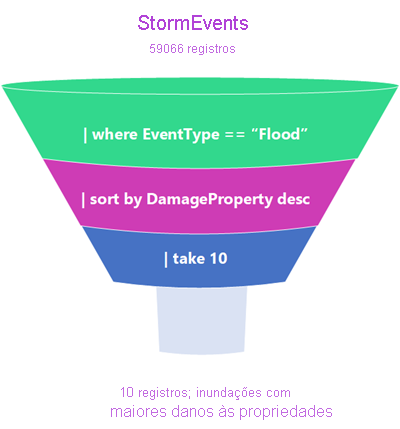
Você pode ver pela forma do filtro que os dados na "parte superior" do funil começam maiores do que o tamanho dos dados no final. As etapas que removem as maiores quantidades de dados costumam ser usadas no início da consulta. Assim, os operadores a seguir têm uma quantidade menor de dados para processar e o resultado da consulta é retornado rapidamente. Na verdade, uma das vantagens do KQL é sua capacidade de processar rapidamente grandes quantidades de dados altamente variados.