Descrever estatísticas de espera
Uma maneira holística de monitorar o desempenho do servidor é avaliar o que o servidor está esperando. As estatísticas de espera são complexas e o SQL Server é instrumentado com centenas de tipos de espera, que monitoram cada thread em execução e registram o que o thread está aguardando.
Detectar e solucionar problemas de desempenho do SQL Server requer uma compreensão de como as estatísticas de espera funcionam e como o mecanismo de banco de dados as usa durante o processamento de uma solicitação.
As estatísticas de espera são divididas em três tipos de espera: esperas de recurso, de fila e externas.
- As esperas de recurso ocorrem quando um thread de trabalho no SQL Server solicita acesso a um recurso que atualmente está sendo usado por um thread. Exemplos de espera de recursos são bloqueios, travas e esperas de E/S de disco.
- As esperas de fila acontecem quando um thread de trabalho está inativo e aguardando a atribuição de trabalho. Exemplos de esperas de fila são monitoramento de deadlock e limpeza de registros excluídos.
- As esperas externas ocorrem quando o SQL Server está aguardando a conclusão de um processo externo, como uma consulta de servidor vinculado. Um exemplo de espera externa é a espera de rede relacionada ao retorno de um conjunto de resultados grande para um aplicativo cliente.
Você pode verificar a exibição do sistema sys.dm_os_wait_stats para explorar todas as esperas encontradas pelos threads executados e sys.dm_db_wait_stats para o Banco de Dados SQL do Azure. O modo de exibição do sistema sys.dm_exec_session_wait_stats lista sessões de espera ativas.
Essas visualizações do sistema permitem que o DBA obtenha uma visão geral do desempenho do servidor e identifique prontamente problemas de configuração ou hardware. Esses dados são mantidos desde o momento da inicialização da instância, mas os dados podem ser limpos conforme necessário para identificar as alterações.
As estatísticas de espera são avaliadas como uma porcentagem do total de esperas no servidor.
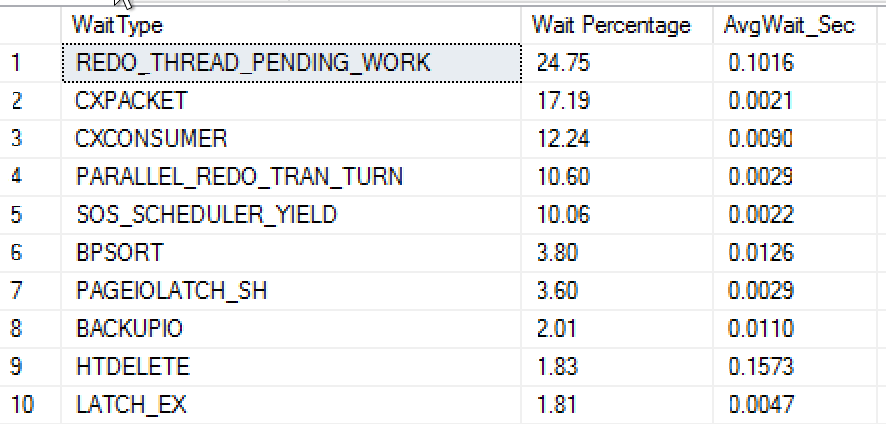
O resultado desta consulta de sys.dm_os_wait_stats mostra o tipo de espera e a agregação da porcentagem de tempo de espera (coluna Porcentagem de Espera) e o tempo médio de espera em segundos para cada tipo de espera.
Nesse caso, o servidor tem Grupos de Disponibilidade Always On em vigor, conforme indicado pelos tipos de espera REDO_THREAD_PENDING_WORK e PARALLEL_REDO_TRAN_TURN. A porcentagem relativamente alta de esperas CXPACKET e SOS_SCHEDULER_YIELD indica que esse servidor está sob alguma pressão de CPU.
Como as DMVs fornecem uma lista de tipos de espera com o maior tempo acumulado desde a última inicialização do SQL Server, coletar e armazenar dados estatísticos de espera periodicamente pode ajudar você a entender e correlacionar problemas de desempenho com outros eventos de banco de dados.
Considerando que as DMVs fornecem uma lista de tipos de espera com o maior tempo acumulado desde a última inicialização do SQL Server, coletar e armazenar estatísticas de espera periodicamente pode ajudar você a entender e correlacionar problemas de desempenho com outros eventos do banco de dados.
Existem vários tipos de esperas disponíveis no SQL Server, mas alguns deles são comuns.
RESOURCE_SEMAPHORE – esse tipo de espera indica que há consultas aguardando a disponibilidade de memória e pode indicar concessões de memória excessivas para algumas consultas. Esse problema normalmente é observado em runtimes de consulta longos ou até mesmo em tempos limite. Esses tipos de espera podem ser causados por estatísticas desatualizadas, índices ausentes e simultaneidade de consulta excessiva.
LCK_M_X – ocorrências frequentes desse tipo de espera podem indicar um problema de bloqueio, que pode ser resolvido alterando para o nível de isolamento
READ COMMITTED SNAPSHOTou fazendo alterações na indexação para reduzir os tempos de transação ou possivelmente melhorar o gerenciamento de transações no código T-SQL.PAGEIOLATCH_SH – esse tipo de espera pode indicar um problema com índices (ou uma falta de índices úteis), no qual o SQL Server está verificando muitos dados. Como alternativa, se a contagem de espera for baixa, mas o tempo de espera for alto, isso poderá indicar problemas de desempenho de armazenamento. Você pode observar esse comportamento analisando os dados nas colunas wait_tasks_count e wait_time_ms na exibição do sistema
sys.dm_os_wait_statspara calcular um tempo médio de espera para um determinado tipo de espera.SOS_SCHEDULER_YIELD – esse tipo de espera pode indicar alta utilização da CPU, que está correlacionada a um alto número de verificações grandes ou a índices ausentes, geralmente com grandes números de esperas CXPACKET.
CXPACKET – se esse tipo de espera for alto, poderá indicar uma configuração incorreta. Antes do SQL Server 2019, a configuração padrão do grau máximo de paralelismo era usar todas as CPUs disponíveis para consultas. Além disso, o limite de custo para a configuração de paralelismo é padronizado para 5, o que pode levar à execução de pequenas consultas em paralelo, o que pode limitar a taxa de transferência. Reduzir o MAXDOP e aumentar o limite de custo do paralelismo pode reduzir esse tipo de espera, mas o tipo de espera CXPACKET também pode indicar alta utilização da CPU, que normalmente é resolvida por meio de ajuste de índice.
PAGEIOLATCH_UP – esse tipo de espera nas páginas de dados 2:1:1 pode indicar a contenção de TempDB em páginas de dados PFS (Page Free Space). Cada arquivo de dados tem uma página PFS por 64 MB de dados. Essa espera geralmente é causada por haver apenas um arquivo TempDB, já que, antes do SQL Server 2016, o comportamento padrão era usar um arquivo de dados para TempDB. A melhor prática é usar um arquivo por núcleo de CPU, até oito arquivos. Também é importante garantir que os arquivos de dados do TempDB tenham o mesmo tamanho e as mesmas configurações de aumento automático para assegurar que sejam usados uniformemente. O SQL Server 2016 e versões posteriores controlam o crescimento de arquivos de dados do TempDB para garantir que eles cresçam de maneira consistente e simultânea.
Além das DMVs mencionadas anteriormente, o Repositório de Consultas também rastreia as esperas associadas a determinada consulta. No entanto, os dados de espera rastreados pelo Repositório de Consultas não são rastreados com a mesma granularidade que os dados nas DMVs, mas podem fornecer uma boa visão geral do que uma consulta está aguardando.