Avaliar o desempenho do modelo.
Avaliar o desempenho do modelo em fases diferentes é crucial para garantir sua eficácia e confiabilidade. Antes de explorar as várias opções que você precisa avaliar seu modelo, vamos explorar os aspectos do aplicativo que você pode avaliar.
Ao desenvolver um copiloto personalizado, você usa um modelo de linguagem em seu aplicativo de chat para gerar uma resposta. Para ajudar você a decidir qual modelo deseja integrar ao seu aplicativo, você pode avaliar o desempenho de um modelo de linguagem individual:
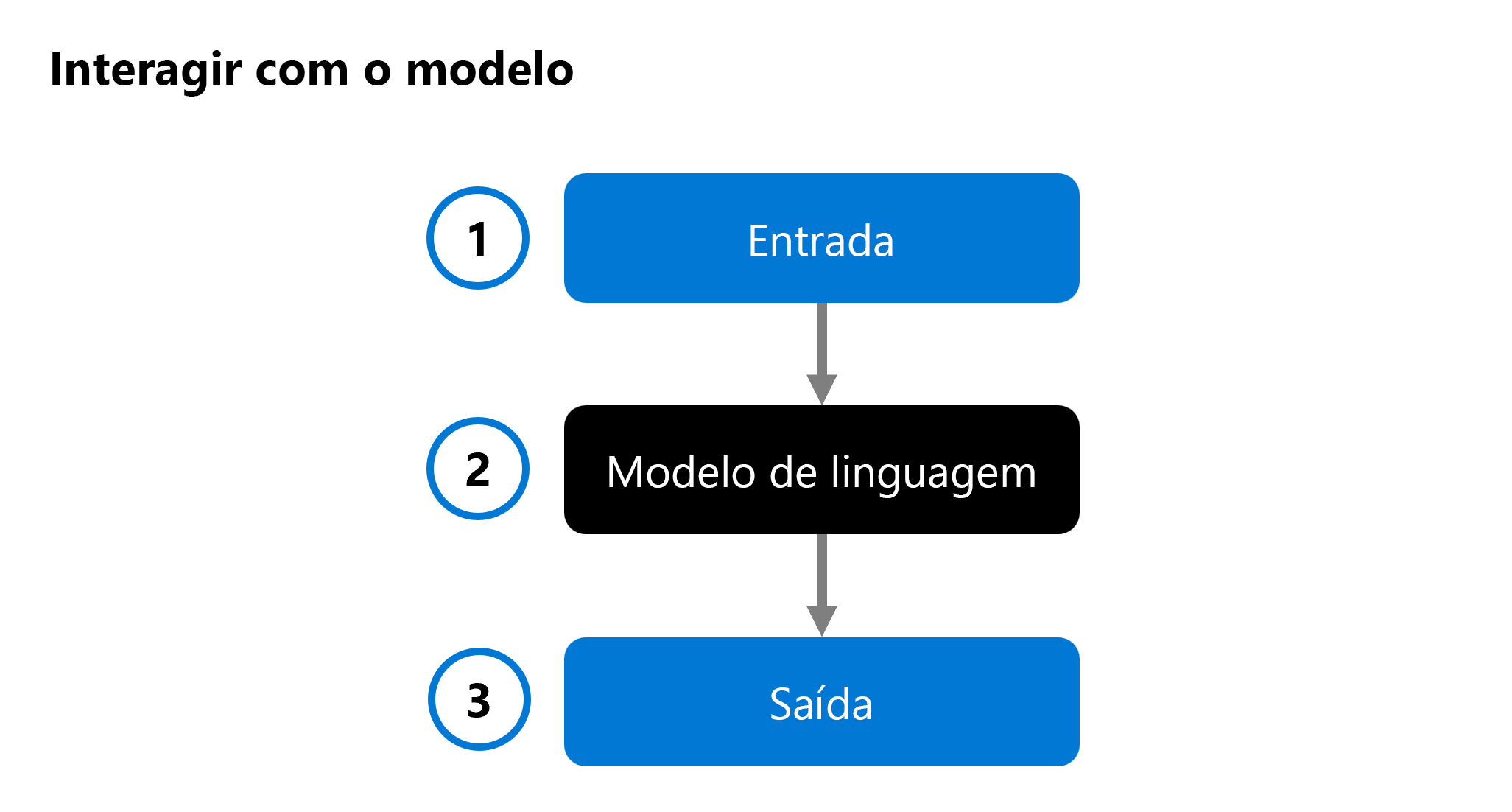
Uma entrada (1) é fornecida a um modelo de idioma (2) e uma resposta é gerada como saída (3). Em seguida, o modelo é avaliado analisando a entrada, a saída e, opcionalmente, comparando-o com a saída esperada predefinida.
Ao desenvolver um aplicativo de IA generativo, você integra um modelo de linguagem a um fluxo de chat:
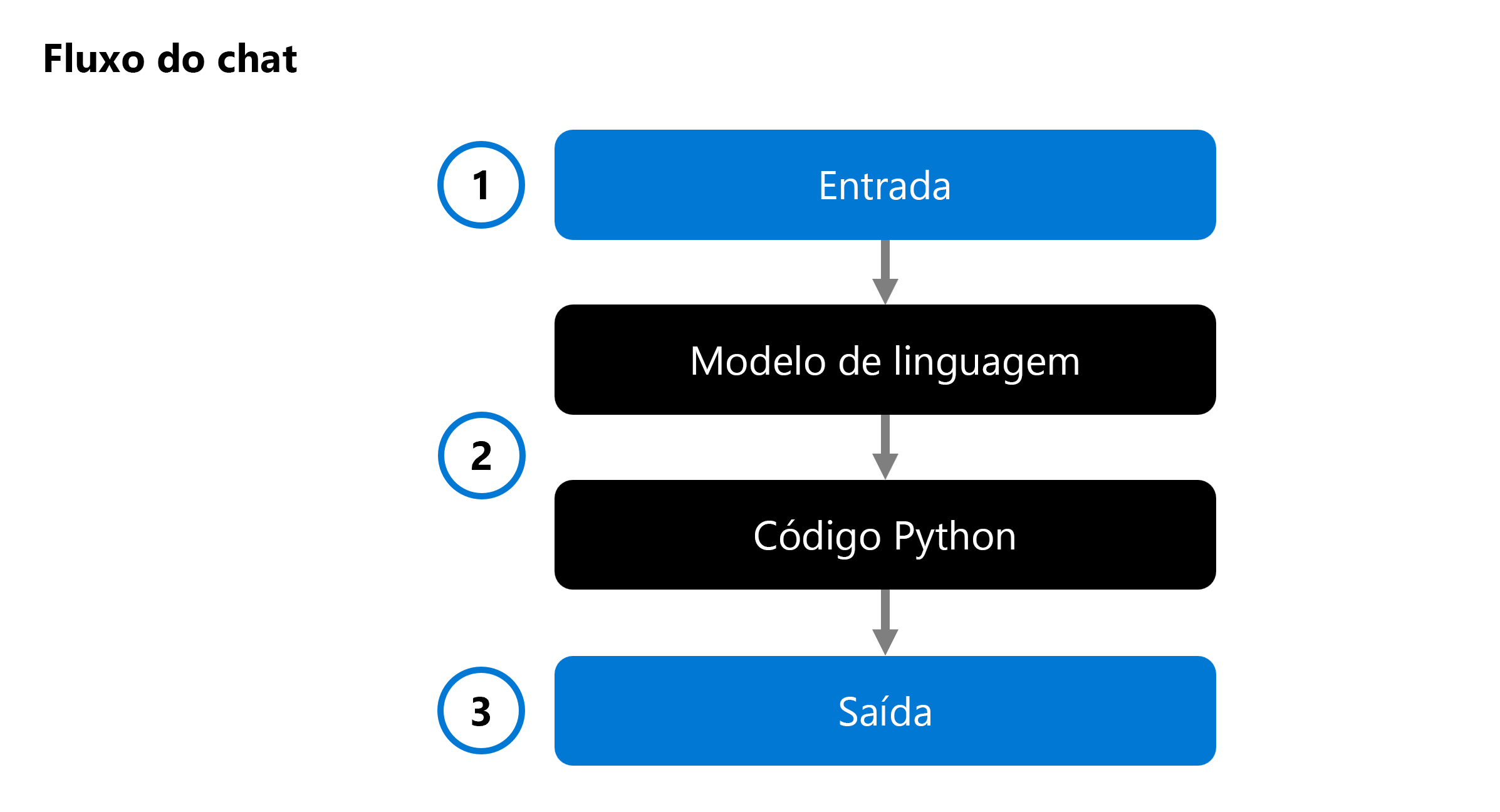
Um fluxo de chat permite orquestrar fluxos executáveis que podem combinar vários modelos de linguagem e código Python. O fluxo espera uma entrada (1), a processa por meio da execução de vários nós (2) e gera uma saída (3). Você pode avaliar um fluxo de chat completo e seus componentes individuais.
Ao avaliar sua solução, você pode começar testando um modelo individual e, eventualmente, testar um fluxo de chat completo para validar se o copiloto personalizado está funcionando conforme o esperado.
Vamos explorar várias abordagens para avaliar seu modelo e fluxo de chat ou copiloto personalizado.
Parâmetro de comparação de modelos
Os parâmetros de comparação de modelo são métricas publicamente disponíveis entre modelos e conjuntos de dados. Esses parâmetros de comparação ajudam você a entender o desempenho do modelo em relação a outras pessoas. Alguns parâmetros de comparação comumente usados incluem:
- Precisão: Compara o texto gerado pelo modelo com a resposta correta de acordo com o conjunto de dados. O resultado é um se o texto gerado corresponder exatamente à resposta e zero caso contrário.
- Coerência: Mede se a saída do modelo flui suavemente, lê naturalmente e se assemelha à linguagem humana
- Fluência: Avalia até que ponto o texto gerado adere a regras gramaticais, estruturas sintáticas e uso apropriado do vocabulário, resultando em respostas linguisticamente corretas e de som natural.
- Similaridade de GPT: Quantifica a similaridade semântica entre uma frase de verdade básica (ou documento) e a sentença de previsão gerada por um modelo de IA.
No Estúdio de IA do Azure, você pode explorar os parâmetros de comparação de modelo para todos os modelos disponíveis antes de implantar um modelo:

Avaliação manual
As avaliações manuais envolvem avaliadores humanos que avaliam a qualidade das respostas do modelo. Essa abordagem fornece insights sobre aspectos que as métricas automatizadas podem perder, como relevância do contexto e satisfação do usuário. Os avaliadores humanos podem classificar as respostas com base em critérios como relevância, informativa e engajamento.
Métricas tradicionais de aprendizado de máquina
As métricas tradicionais de aprendizado de máquina também são valiosas na avaliação do desempenho do modelo. Uma dessas métricas é a pontuação F1, que mede a proporção do número de palavras compartilhadas entre as respostas de verdade geradas e fundamentadas. A pontuação F1 é útil para tarefas como classificação de texto e recuperação de informações, em que a precisão e o recall são importantes.
Métricas assistidas por IA
As métricas assistidas por IA usam técnicas avançadas para avaliar o desempenho do modelo. Essas métricas podem incluir:
- Métricas de risco e segurança: Essas métricas avaliam os riscos potenciais e as preocupações de segurança associadas às saídas do modelo. Eles ajudam a garantir que o modelo não gere conteúdo prejudicial ou tendencioso.
- Métricas de qualidade de geração: Essas métricas avaliam a qualidade geral do texto gerado, considerando fatores como criatividade, coerência e adesão ao estilo ou tom desejados.