Decidir entre opções de computação
Quando você quiser treinar seu modelo, o recurso mais valioso que você consumirá será a computação. Especialmente durante o treinamento de modelos, é importante escolher a computação mais adequada. Você também deve monitorar a utilização da computação para saber quando escalar ou reduzir verticalmente para economizar tempo e custos.
Embora descobrir qual tamanho de máquina virtual atende melhor às suas necessidades seja um processo iterativo, há algumas diretrizes que você pode seguir ao começar o desenvolvimento.
CPU ou GPU
Uma decisão importante a tomar ao configurar a computação é se você deseja usar uma CPU (unidade de processamento central) ou uma GPU (unidade de processamento gráfico). Para conjuntos de dados tabulares menores, a CPU será suficiente e mais barata de usar. Sempre que trabalhar com dados não estruturados, como imagens ou texto, as GPUs serão mais eficientes e eficazes.
Também pode ser benéfico usar GPUs se houver quantidades maiores de dados tabulares. Caso o processamento de seus dados e o treinamento de seu modelo demore muito tempo, mesmo com a maior computação de CPUs disponível, convém considerar o uso da computação de GPUs. Há bibliotecas como as RAPIDs (desenvolvidas pela NVIDIA), que permitem executar com eficiência a preparação de dados e o treinamento de modelo com conjuntos de dados tabulares maiores. Como as GPUs têm um custo mais alto do que as CPUs, alguma experimentação pode ser necessária para explorar se o uso da GPU será benéfico para sua situação.
Uso geral ou otimizado para memória
Quando você cria recursos de computação para cargas de trabalho de aprendizado de máquina, há dois tipos comuns de tamanhos de máquina virtual para escolher:
- Uso geral: tem uma taxa de CPU/memória equilibrada. Ideal para teste e desenvolvimento com conjuntos de dados menores.
- Otimizado para memória: tem uma alta taxa de memória para CPU. Ótimo para análise in-memory, que é ideal para quando você tem conjuntos de dados maiores ou está trabalhando em notebooks.
O tamanho da computação no Azure Machine Learning é mostrado como o tamanho da máquina virtual. Os tamanhos seguem as mesmas convenções de nomenclatura das Máquinas Virtuais do Microsoft Azure.
Dica
Saiba mais sobre tamanhos para máquinas virtuais no Azure.
Spark
Serviços como o Azure Synapse Analytics e o Azure Databricks oferecem computação do Spark. Os clusters ou computação do Spark usam o mesmo dimensionamento que as máquinas virtuais do Azure, mas distribuem as cargas de trabalho.
Um cluster do Spark consiste em um nó de driver e nós de trabalho. Seu código se comunicará inicialmente com o nó do driver. Em seguida, o trabalho será distribuído entre os nós de trabalho. Quando se usa um serviço que distribui o trabalho, partes da carga de trabalho podem ser executadas em paralelo, reduzindo o tempo de processamento. Por fim, o trabalho é resumido e o nó do driver comunica o resultado de volta para você.
Importante
Para obter o uso ideal de um cluster do Spark, seu código precisa ser escrito em uma linguagem amigável para o Spark, como Scala, SQL, RSpark ou PySpark, a fim de distribuir a carga de trabalho. Se você escrever em Python, usará apenas o nó de driver e não utilizará os nós de trabalho.
Ao criar um cluster do Spark, você precisará escolher se deseja usar a computação de GPU ou de CPU. Você também precisará escolher o tamanho da máquina virtual para o driver e os nós de trabalho.
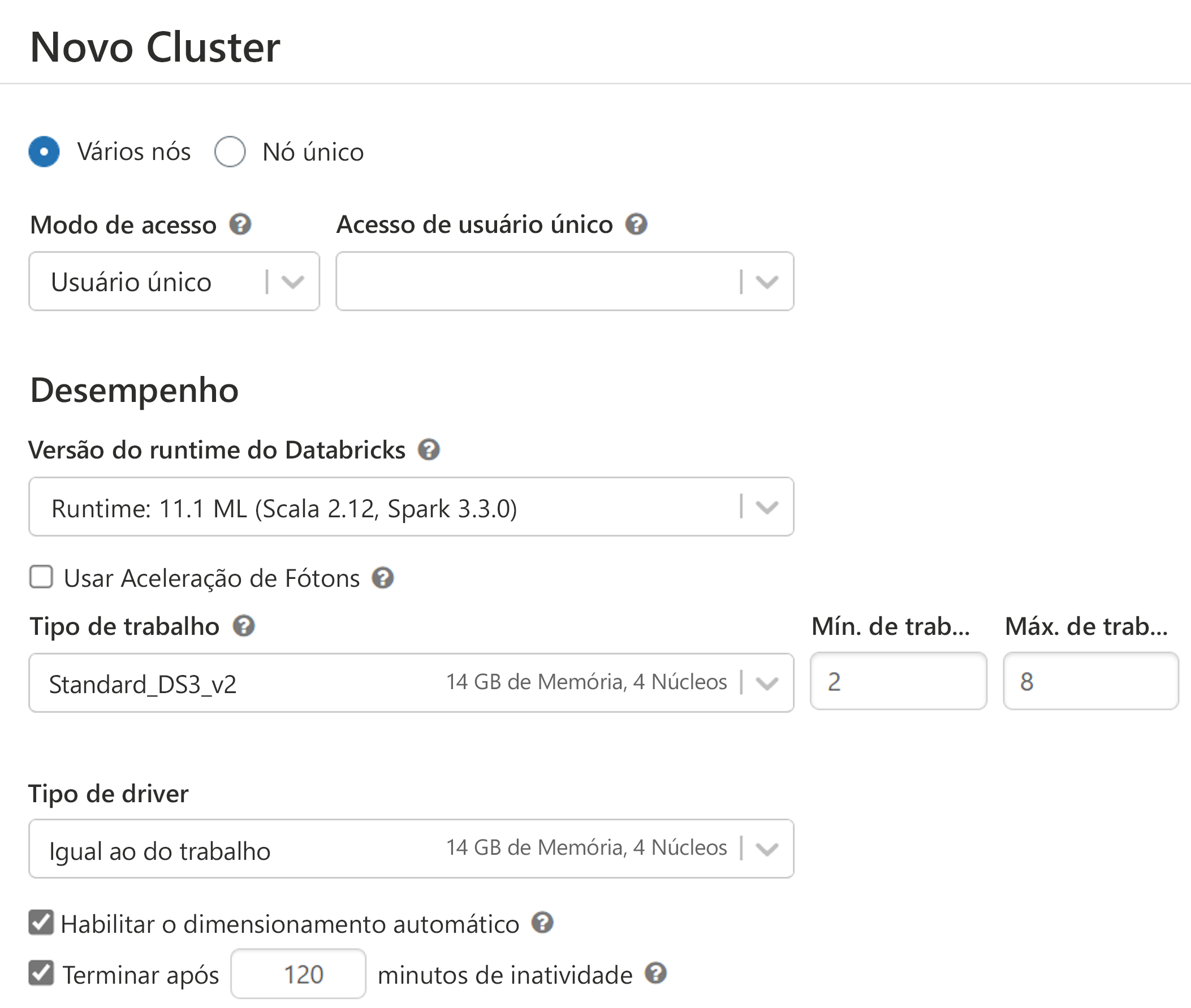
Monitorar a utilização da computação
Configurar recursos de computação para treinar um modelo de machine learning é um processo iterativo. Quando você souber quantos dados tem e como deseja treinar seu modelo, terá uma ideia de quais opções de computação podem se adequar melhor ao treinamento do modelo.
Sempre que treinar um modelo, você deve monitorar quanto tempo leva para treinar o modelo e a quantidade de computação usada para executar o código. Com o monitoramento da utilização da computação, você saberá se deseja escalar ou reduzir verticalmente a computação. Se o treinamento do modelo demorar muito, mesmo com o maior tamanho de computação, talvez você queira usar GPUs em vez de CPUs. Como alternativa, você pode optar por distribuir o treinamento do modelo usando a computação do Spark, o que pode exigir que você reescreva seus scripts de treinamento.