Identificar a fonte de dados e o formato
Os dados são a entrada mais importante para a criação de modelos de machine learning. Você precisará de acesso aos dados ao treinar modelos de machine learning, e o modelo treinado precisa de dados como entrada para gerar previsões.
Imagine que você é um cientista de dados que precisa treinar um modelo de machine learning.
Você pretende seguir as seis seguintes etapas para planejar, treinar, implantar e monitorar o modelo:

- Definir o problema: decida o que o modelo deve prever e quando ele será bem-sucedido.
- Obter os dados: localize as fontes de dados e obtenha acesso.
- Preparar os dados: explore os dados. Limpe e transforme os dados com base nos requisitos do modelo.
- Treinar o modelo: escolha um algoritmo e valores de hiperparâmetros com base em tentativa e erro.
- Integrar o modelo: implante o modelo em um ponto de extremidade para gerar as previsões.
- Monitorar o modelo: acompanhe o desempenho do modelo.
Observação
O diagrama é uma representação simplificada do processo de aprendizado de máquina. Normalmente o processo é iterativo e contínuo. Por exemplo, ao monitorar o modelo, você pode decidir voltar e novamente treinar esse modelo.
Para obter e preparar os dados que serão usados para treinar o modelo de machine learning, você precisará extrair dados de uma fonte e disponibilizá-los ao serviço do Azure que deseja usar para treinar modelos ou fazer previsões.
Em geral, é uma prática recomendada extrair os dados da respectiva fonte antes de analisá-los. Esteja você usando os dados para engenharia de dados, análise de dados ou ciência de dados, convém extrair os dados da respectiva fonte, transformá-los e carregá-los em uma camada de serviço. Esse processo também é chamado de ETL (Extração, Transformação e Carregamento) ou ELT (Extração, Carregamento e Transformação). A camada de serviço disponibiliza seus dados para o serviço que você usará para processamento adicional de dados, como treinamento de modelos de machine learning.
Para poder projetar o processo ETL ou ELT, você precisará identificar a fonte o formato de dados.
Identificar a fonte de dados
Quando você começa com um novo projeto de machine learning, primeiro identifique onde os dados que você deseja usar estão armazenados.
Os dados necessários para o modelo de machine learning podem já estar armazenados em um banco de dados ou ser gerados por um aplicativo. Por exemplo, os dados podem estar armazenados em um sistema de CRM (Gerenciamento de Relacionamento com o Cliente), em um banco de dados transacional como um banco de dados SQL ou ser gerados por um dispositivo IoT (Internet das Coisas).
Em outras palavras, sua organização pode já ter processos de negócios em vigor, que geram e armazenam os dados. Se você não tem acesso aos dados necessários, existem métodos alternativos. Você pode coletar novos dados implementando um novo processo, adquirir novos dados usando conjuntos de dados disponíveis publicamente ou comprar conjuntos de dados coletados.
Identificar o formato de dados
Com base na fonte de seus dados, eles podem ser armazenados em um formato específico. Você precisa entender o formato atual dos dados e determinar o formato necessário para suas cargas de trabalho de aprendizado de máquina.
Normalmente, nos referimos a três formatos diferentes:
Dados tabulares ou estruturados : todos os dados têm os mesmos campos ou propriedades, que são definidos em um esquema. Os dados tabulares geralmente são representados em uma ou mais tabelas em que as colunas representam recursos e as linhas representam pontos de dados. Por exemplo, um arquivo do Excel ou CSV pode ser interpretado como dados tabulares:
ID do paciente Gravidezes Pressão arterial diastólica BMI Pedigree de diabetes Idade Diabético 1354778 0 80 43,50973 1,213191 21 0 1147438 8 93 21,24058 0,158365 23 1 Dados semiestruturados: nem todos os dados têm os mesmos campos ou propriedades. Em vez disso, cada ponto de dados é representado por uma coleção de pares chave-valor. As chaves representam os recursos e os valores representam as propriedades do ponto de dados individual. Por exemplo, aplicativos em tempo real, como dispositivos IoT (Internet das Coisas), geram um objeto JSON:
{ "deviceId": 29482, "location": "Office1", "time":"2021-07-14T12:47:39Z", "temperature": 23 }Dados não estruturados: arquivos que não seguem nenhuma regra quando se trata de estrutura. Por exemplo, documentos, imagens, áudio e arquivos de vídeo são considerados dados não estruturados. Armazená-los como arquivos não estruturados garante que você não precise definir nenhum esquema nem estrutura, mas também significa que não é possível consultar os dados no banco de dados. Você precisará especificar como ler esse arquivo ao consumir os dados.
Dica
Saiba mais sobre os principais conceitos de dados no Learn
Identificar o formato de dados desejado
Ao extrair os dados de uma fonte, convém transformar os dados para alterar o formato de dados e torná-los mais adequados para treinamento de modelo.
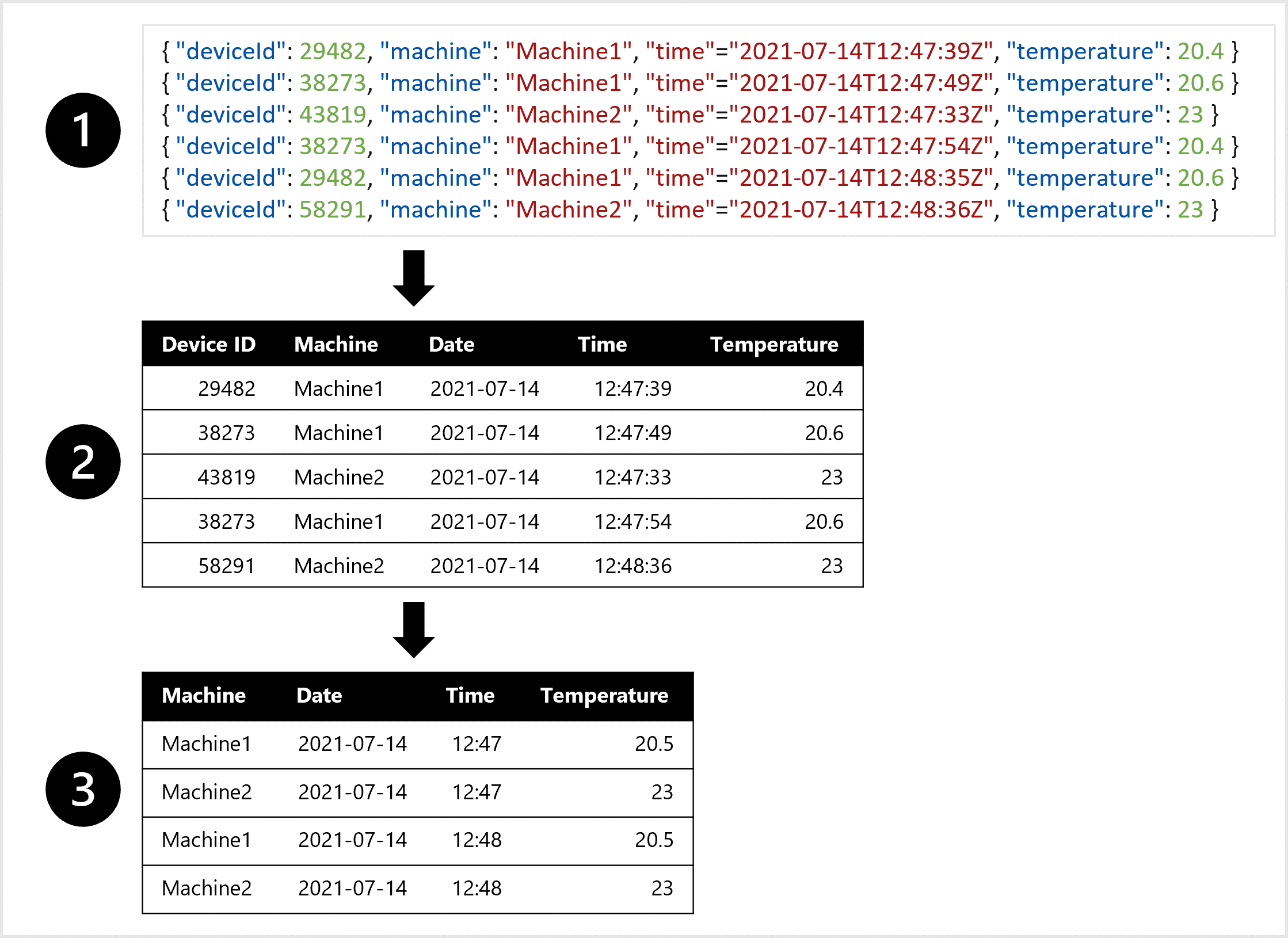
Por exemplo, talvez você queira treinar um modelo de previsão para executar a manutenção preditiva em um computador. Você deseja usar recursos como a temperatura do computador para prever um problema com o computador. Se você receber um alerta de que um problema está surgindo, antes que o computador seja interrompido, você poderá economizar custos corrigindo o problema no início.
Imagine que o computador tem um sensor que mede a temperatura a cada minuto. A cada minuto, cada medida ou entrada pode ser armazenada como um arquivo ou objeto JSON.
Para treinar o modelo de previsão, você pode preferir uma tabela na qual todas as medidas de temperatura de cada minuto são combinadas. Talvez você queira criar agregações dos dados e ter uma tabela da temperatura média por hora. Para criar a tabela, você desejará transformar os dados semiestruturados ingeridos do dispositivo IoT em dados tabulares.
Para criar um conjunto de dados que você pode usar para treinar o modelo de previsão, você pode:
- Extrair medidas de dados como objetos JSON dos dispositivos IoT.
- Converter os objetos JSON em uma tabela.
- Transformar os dados para obter a temperatura por computador por minuto.
Depois de identificar a fonte de dados, o formato de dados original e o formato de dados desejado, você poderá pensar em como deseja fornecer os dados. Em seguida, você pode criar um pipeline de ingestão de dados para extrair e transformar automaticamente os dados necessários.