Noções básicas sobre hiperescala do banco de dados SQL
O Banco de Dados SQL do Azure foi limitado a 4 TB de armazenamento por banco de dados por muitos anos. Essa restrição ocorria devido a uma limitação física da infraestrutura do Azure. A Hiperescala do Banco de Dados SQL do Azure altera o paradigma e permite que os bancos de dados tenham 100 TB ou mais. A Hiperescala apresenta novas técnicas de dimensionamento horizontal para adicionar nós de computação à medida que os tamanhos dos dados ficam maiores. O custo da Hiperescala é igual ao do Banco de Dados SQL do Azure. No entanto, há um custo por terabyte para o armazenamento. Observe que, uma vez que um Banco de Dados SQL do Azure seja convertido em Hiperescala, não será possível convertê-lo novamente em um Banco de Dados SQL do Azure "regular". Hiperescala é a capacidade de uma arquitetura ser dimensionada adequadamente conforme a demanda.
A Hiperescala do Banco de Dados SQL do Azure é uma ótima opção para a maioria das cargas de trabalho de negócios, pois fornece excelente flexibilidade e alto desempenho com recursos de computação e armazenamento escalonáveis de maneira independente.
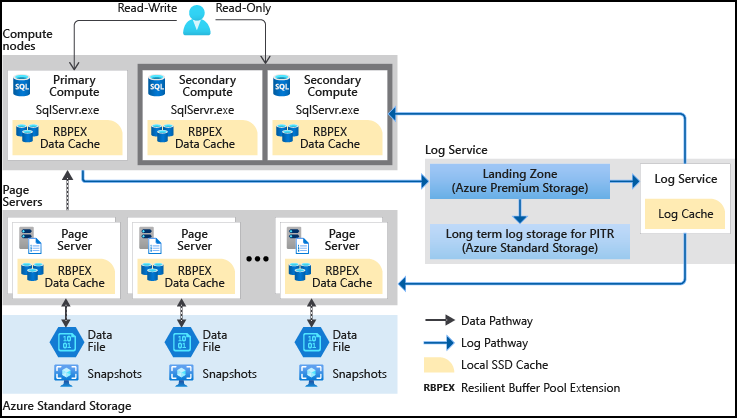
A Hiperescala separa o mecanismo de processamento de consulta, onde a semântica de diversos mecanismos de dados divergem, dos componentes que fornecem armazenamento de longo prazo e durabilidade para os dados. Dessa forma, a capacidade de armazenamento pode ser perfeitamente expandida até onde conforme necessário.
A camada de serviço em hiperescala no banco de dados SQL do Azure é a camada de serviço mais recente em que o modelo de compra baseado em vCore. Essa camada de serviço é um armazenamento altamente escalonável e a camada de serviço de computação que usa a arquitetura do Azure para escalar horizontalmente o armazenamento e recursos de computação para um banco de dados SQL do Azure substancialmente além dos limites disponíveis para uso geral e negócios Comercialmente Crítico.
Benefícios
A camada de serviço da Hiperescala elimina muitos dos limites práticos vistos tradicionalmente em bancos de dados de nuvem. Onde mais outros bancos de dados são limitados pelos recursos disponíveis em um único nó, bancos de dados na camada de serviço da Hiperescala não têm esses limites. Com sua arquitetura de armazenamento flexível, o armazenamento aumenta conforme necessário. Na realidade, os bancos de dados de Hiperescala não são criados com um tamanho máximo definido. Um banco de dados de Hiperescala aumenta conforme necessário, e você será cobrado apenas pela capacidade usada. Para cargas de trabalho que fazem uso intenso de leitura, a camada de serviço Hiperescala oferece uma rápida expansão por meio do provisionamento de leitura de réplicas extra conforme necessário para descarregar cargas de trabalho de leitura.
Além disso, o tempo necessário para criar backups de banco de dados ou para aumentar ou diminuir a escala não está mais vinculado ao volume de dados no banco de dados. Bancos de dados de Hiperescala podem ser passar por back up instantaneamente. Você também pode dimensionar um banco de dados em dezenas de terabytes para cima ou para baixo em minutos. Esse recurso libera você das preocupações sobre ser encaixotado pelas opções iniciais de configuração. A Hiperescala também fornece restaurações rápidas de banco de dados que são executadas em minutos, em vez de horas ou dias.
A Hiperescala fornece escalabilidade rápida com base na demanda de carga de trabalho.
Escalar/reduzir verticalmente – você pode escalar verticalmente o tamanho da computação primária em termos de recursos como CPU e memória e, em seguida, reduzir verticalmente em tempo constante. Como o armazenamento é compartilhado, escalar e reduzir verticalmente não está vinculado ao volume de dados no banco de dados.
Reduzir/escalar horizontalmente – você também pode provisionar uma ou mais réplicas de computação que pode usar para atender às solicitações de leitura. Isso significa que você pode usar réplicas de computação extra como réplicas somente leitura para descarregar a carga de trabalho de leitura da computação primária. Além de somente leitura, essas réplicas também atuam como esperas ativas para fazer failover da instância primária.
O provisionamento de cada uma dessas réplicas de computação extra pode ser feito em tempo constante e é uma operação on-line. Você pode se conectar a réplicas de computação somente leitura configurando o argumento ApplicationIntent na cadeia de conexão como ReadOnly. Todas as conexões com a intenção do aplicativo ReadOnly são automaticamente encaminhadas para uma das réplicas de computação somente leitura.
A Hiperescala separa o mecanismo de processamento de consulta dos componentes que fornecem armazenamento de longo prazo e durabilidade para os dados. Essa arquitetura fornece a capacidade de dimensionar perfeitamente a capacidade de armazenamento conforme necessário (o destino inicial é de 100 TB), bem como a capacidade de dimensionar recursos de computação rapidamente.
Considerações de segurança
A segurança da camada de serviço de Hiperescala compartilha as mesmas excelentes funcionalidades que as outras camadas do Banco de Dados SQL do Azure. Eles são protegidos pela abordagem de defesa em profundidade em camadas conforme mostrado na imagem abaixo e se movimenta de fora para dentro:
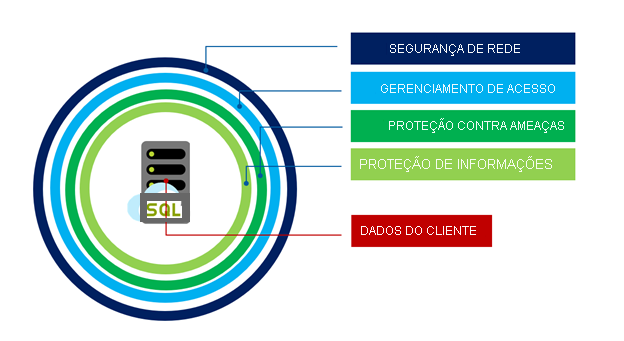
A Segurança de Rede é a primeira camada de defesa e usa regras de firewall de IP para permitir o acesso com base no endereço IP de origem e nas regras de firewall da Rede Virtual para habilitar a capacidade de aceitar comunicações enviadas de sub-redes selecionadas dentro de uma rede virtual.
O Gerenciamento de Acesso é fornecido por meio dos métodos de autenticação abaixo para garantir que um usuário seja quem afirma ser:
- Autenticação do SQL
- autenticação do Microsoft Entra
- Autenticação do Windows para entidades de segurança do Microsoft Entra (versão prévia)
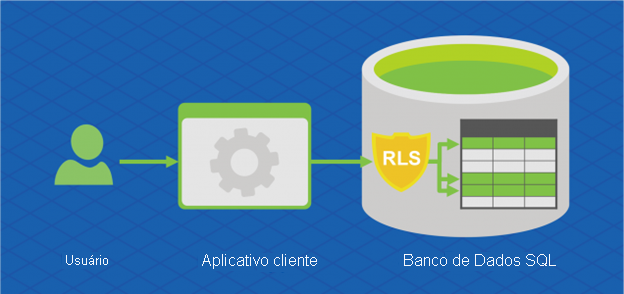
A Hiperescala do Banco de Dados SQL do Azure também dá suporte à segurança no Nível da Linha. A segurança em nível de linha permite aos clientes controlar o acesso às linhas em uma tabela de banco de dados com base nas características do usuário executando uma consulta (por exemplo, associação a grupo ou contexto de execução).
Capacidades de Proteção contra Ameaças em recursos de auditoria e detecção de ameaças. A auditoria do Banco de Dados SQL e da Instância Gerenciada de SQL rastreia as atividades do banco de dados e ajuda a manter a conformidade com os padrões de segurança registrando eventos de banco de dados em um log de auditoria em uma conta de Armazenamento do Azure de propriedade do cliente. A Proteção Avançada contra Ameaças pode ser habilitada por servidor por uma taxa extra e analisa seus logs para detectar comportamentos incomuns e tentativas potencialmente prejudiciais de acessar ou explorar bancos de dados. Os alertas são criados para atividades suspeitas, como a injeção de SQL, potencial infiltração de dados e ataques de força bruta ou para anomalias em padrões de acesso para capturar as elevações de privilégio e uso de credenciais violadas.
A Proteção de Informações é fornecida das seguintes maneiras:
- Protocolo TLS (Criptografia em trânsito)
- Transparent Data Encryption (Criptografia em repouso)
- Gerenciamento de chaves com o Azure Key Vault
- Always Encrypted (Criptografia em uso)
- Mascaramento de dados dinâmicos
Considerações sobre o desempenho
A camada de serviço da Hiperescala é destinada a clientes que possuem grandes bancos de dados locais SQL Server e desejam modernizar os aplicativos migrando para a nuvem ou para clientes que já usam o Banco de Dados SQL do Azure e desejam expandir significativamente o potencial de crescimento do banco de dados. A Hiperescala também é destinado a clientes que buscam alto desempenho e alta escalabilidade.
A Hiperescala fornece os seguintes recursos de desempenho:
- Backups de banco de dados quase instantâneos (com base em instantâneos de arquivo guardados no Armazenamento de Blobs do Azure), independentemente do tamanho sem nenhum impacto de E/S sobre os recursos computacionais.
- Rápidas restaurações de banco de dados (com base em instantâneos de arquivo) em minutos, em vez de horas ou dias (não um tamanho de operação de dados).
- Maior desempenho geral devido à maior taxa de transferência de log e tempos mais rápidos de confirmação de transação, independentemente dos volumes de dados.
- Escala horizontal rápida – você pode provisionar uma ou mais réplicas somente leitura para descarregar sua carga de trabalho de leitura e usar como esperas ativas.
- Dimensionamento rápido - você pode, de forma contínua, aumentar seus recursos computacionais para acomodar cargas de trabalho pesadas conforme a necessidade e, depois, diminuir os recursos computacionais novamente quando não for mais necessário.
Observação
A Hiperescala do Banco de Dados SQL não dá suporte aos seguintes recursos:
- Instância Gerenciada de SQL
- Pools elásticos
- Replicação geográfica
- Insights de Desempenho de Consulta
Implantar a Hiperescala do Banco de Dados SQL do Azure
Para implantar o Banco de Dados SQL do Azure com a camada de Hiperescala:
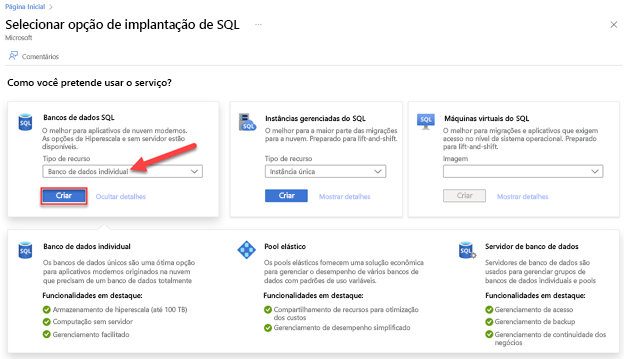
Navegue até a página da opção Selecionar uma Implantação de SQL.
Em Bancos de dados SQL, deixe Tipo de recurso definido como Banco de dados individual e selecione Criar.
Na guia Básico da página Criar Banco de Dados SQL, selecione a assinatura, o grupo de recursos e o nome do banco de dados desejados.
Selecione o link Criar para o Servidor e preencha as novas informações do servidor, como nome do servidor, logon de administrador do servidor, senha e local.
Em Computação + armazenamento, selecione o link Configurar o banco de dados.
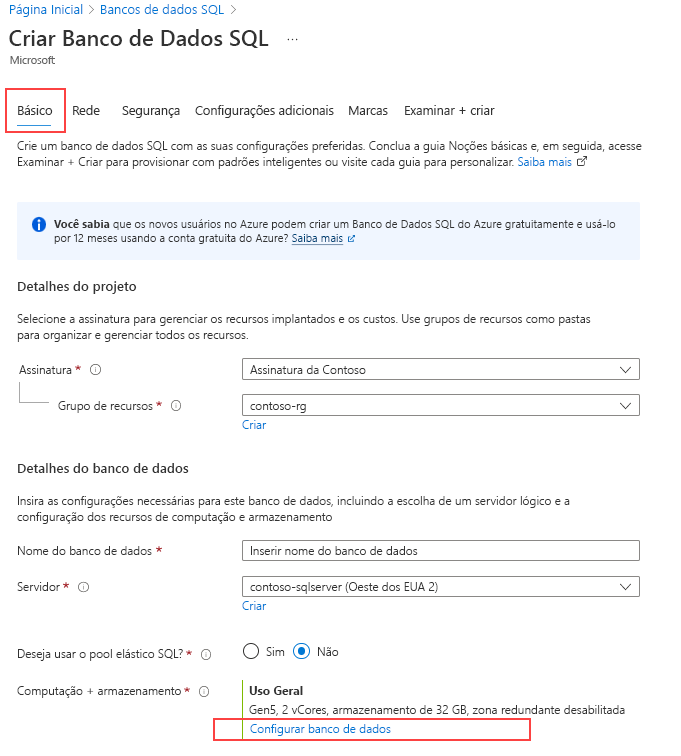
Para a camada de serviço, selecione Hiperescala.
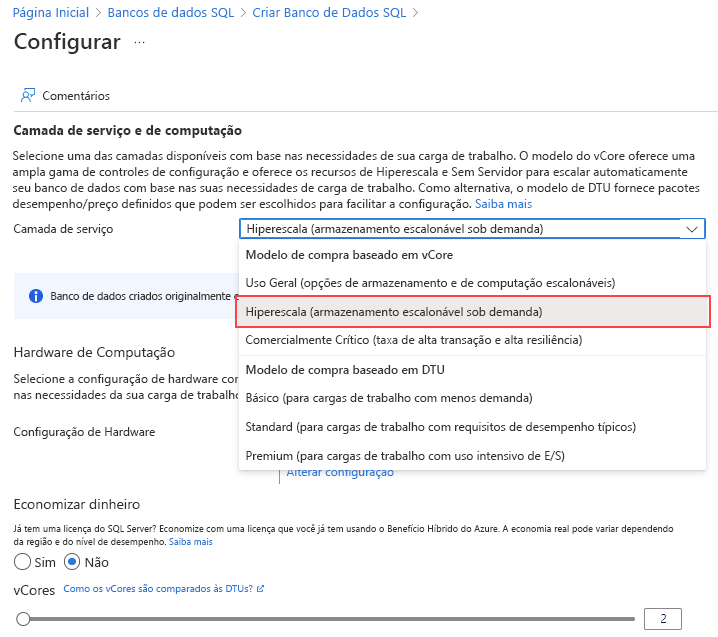
Em Configuração de Hardware, selecione o link Alterar configuração. Examine as configurações de hardware disponíveis e selecione a configuração mais apropriada ao banco de dados. Neste exemplo, selecionaremos a configuração Gen5.
Selecione OK para confirmar a geração de hardware.
Opcionalmente, ajuste o controle deslizante vCores se quiser aumentar o número de vCores para seu banco de dados. Neste exemplo, escolheremos 2 vCores.
Ajuste o controle deslizante de réplicas secundárias de alta disponibilidade para criar uma réplica de alta disponibilidade (HA). Escolha Aplicar.
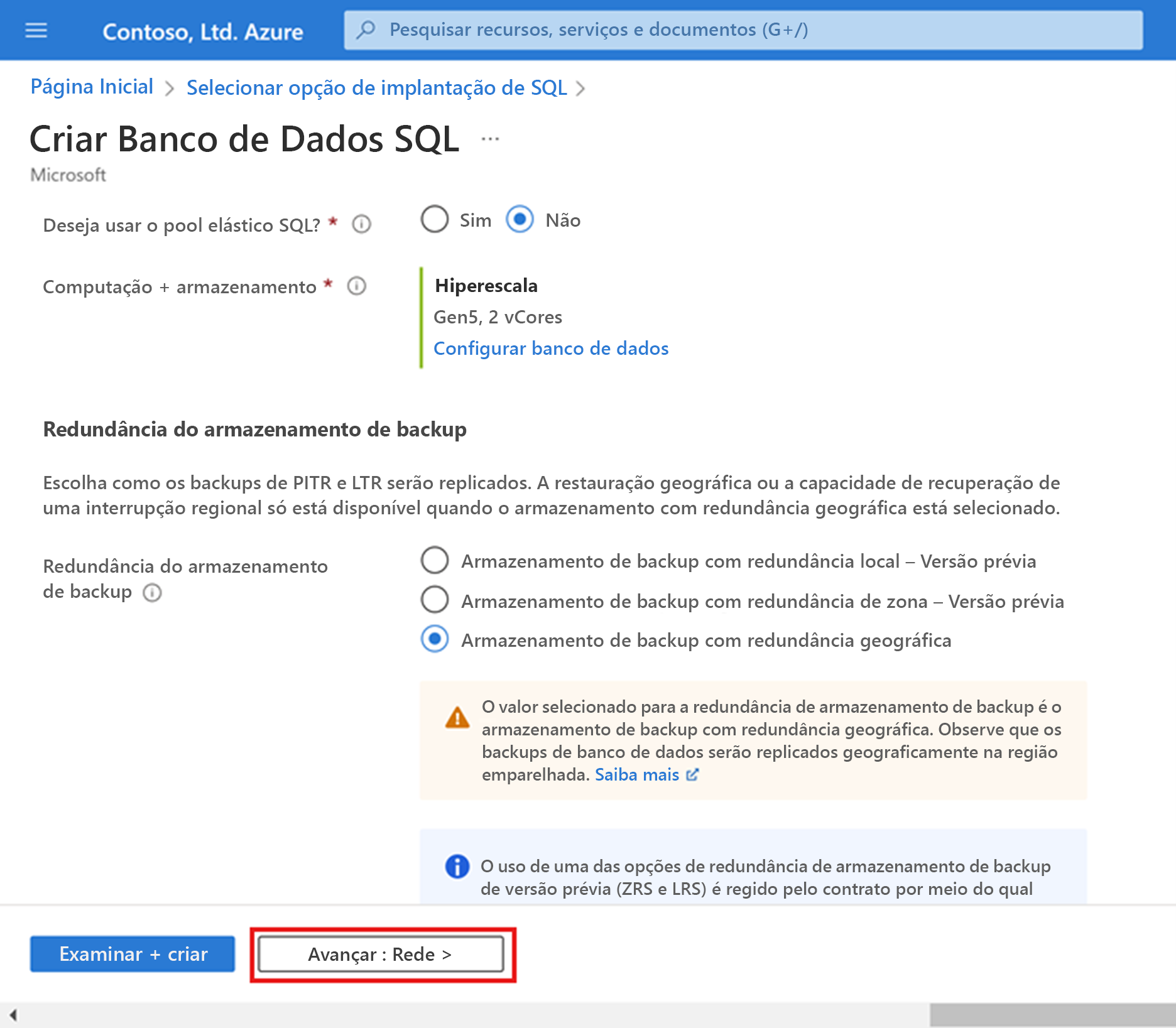
Selecione Avançar: Rede na parte inferior da página.
Para Regras de firewall, na guia Rede, defina Adicionar endereço IP do cliente atual como Sim. Deixe Permitir que serviços e recursos do Azure acessem este servidor definido como Não.
Selecione Próximo: Segurança na parte inferior da página.
Na guia Revisar + criar, selecione Criar.
