Explorar o desempenho e a segurança
O ecossistema do Azure oferece várias opções de desempenho e de segurança para a instância do SQL Server na máquina virtual do Azure. Cada opção fornece vários recursos, como diferentes tipos de discos que atendem aos requisitos de capacidade e desempenho da carga de trabalho.
Considerações de armazenamento
O SQL Server requer um bom desempenho de armazenamento para fornecer um desempenho de aplicativo robusto, seja uma instância local ou instalada em uma VM do Azure. O Azure fornece uma ampla variedade de soluções de armazenamento para atender às necessidades da sua carga de trabalho. Embora o Azure ofereça vários tipos de armazenamento (blob, arquivo, fila, tabela), na maioria dos casos as cargas de trabalho do SQL Server usarão os discos gerenciados do Azure. As exceções incluem uma Instância de Cluster de Failover, que pode ser criada no armazenamento de arquivos e os backups usarão o armazenamento de blobs. Os discos gerenciados do Azure atuam como um dispositivo de armazenamento de nível de bloco que é apresentado à sua VM do Azure. Os discos gerenciados oferecem vários benefícios, incluindo disponibilidade de 99,999%, implantação escalonável (você pode ter até 50.000 discos de VM por assinatura por região) e integração com conjuntos de disponibilidade e zonas para oferecer níveis mais altos de resiliência em caso de falha.
Todos os discos gerenciados do Azure oferecem dois tipos de criptografia. A criptografia do lado do servidor do Azure é fornecida pelo serviço de armazenamento e age como criptografia em repouso fornecida pelo serviço de armazenamento. O Azure Disk Encryption usa o BitLocker no Windows e o DM-Crypt no Linux para fornecer criptografia do sistema operacional e do disco de dados dentro da VM. As duas tecnologias se integram ao Azure Key Vault e permitem que você traga sua própria chave de criptografia.
Cada VM terá pelo menos dois discos associados:
Disco do sistema operacional – cada máquina virtual exigirá um disco do sistema operacional que contenha o volume de inicialização. Esse disco seria a unidade C: no caso de uma máquina virtual da plataforma Windows ou /dev/sda1 no Linux. O sistema operacional será instalado automaticamente no disco do sistema operacional.
Disco temporário – cada máquina virtual incluirá um disco usado para armazenamento temporário. Esse armazenamento destina-se a ser usado por dados que não precisam ser duráveis, como arquivos de paginação ou de permuta. Como o disco é temporário, você não deve usá-lo para armazenar informações críticas, como bancos de dados ou arquivos de log de transações, pois elas serão perdidas durante a manutenção ou na reinicialização da máquina virtual. Esta unidade será montada como D:\ no Windows e /dev/sdb1 no Linux.
Além disso, você pode e deve adicionar discos de dados adicionais às VMs do Azure que executam o SQL Server.
- Discos de dados – o termo disco de dados é usado na portal do Azure, mas, na prática, são apenas discos gerenciados extras adicionados a uma VM. Esses discos podem ser agrupados para aumentar a capacidade de armazenamento e IOPs disponíveis, usando Espaços de Armazenamento no Windows ou Gerenciamento de Volume Lógico no Linux.
Além disso, cada disco pode ser um de vários tipos:
| Recurso | Disco Ultra | SSD Premium | SSD Standard | HDD Standard |
|---|---|---|---|---|
| Tipo de disco | SSD | SSD | SSD | HDD |
| Mais adequado para | Carga de trabalho com uso intensivo de E/S | Carga de trabalho sensível ao desempenho | Cargas de trabalho leves | Backups, cargas de trabalho não críticas |
| Tamanho máximo do disco | 65.536 GiB | 32.767 GiB | 32.767 GiB | 32.767 GiB |
| Taxa de transferência máxima | 2\.000 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| IOPS Máxima | 160.000 | 20.000 | 6.000 | 2.000 |
As melhores práticas para o SQL Server no Azure recomendam o uso de discos Premium em pool para aumentar a capacidade de armazenamento e IOPs. Os arquivos de dados devem ser armazenados em seu próprio pool com cache de leitura nos discos do Azure.
Os arquivos de log de transações não se beneficiarão desse cache, portanto, esses arquivos devem entrar em seu próprio pool sem cache. O TempDB pode, opcionalmente, entrar em seu próprio pool ou usar o disco temporário da VM, que oferece baixa latência, pois está fisicamente anexado ao servidor físico onde as VMs estão em execução. Configurado adequadamente, o SSD Premium perceberá a latência em um dígito de milissegundos. Nas cargas de trabalho críticas que exigem latência ainda menor que isso, você deve considerar o SSD Ultra.
Considerações de segurança
Há vários regulamentos e padrões do setor com que o Azure está em conformidade, o que possibilita a criação de uma solução em conformidade com o SQL Server em execução em uma máquina virtual.
Microsoft Defender para SQL
O Microsoft Defender para SQL fornece recursos da Central de Segurança do Azure, como avaliações de vulnerabilidade e alertas de segurança.
O Azure Defender para SQL pode ser usado para identificar e mitigar possíveis vulnerabilidades em seu banco de dados e sua instância do SQL Server. O recurso de avaliação de vulnerabilidade pode detectar possíveis riscos no ambiente do SQL Server e ajudar você a corrigi-los. Ele também fornece insights sobre seu estado de segurança e etapas acionáveis para resolver problemas de segurança.
Central de Segurança do Azure
A Central de Segurança do Azure é um sistema de gerenciamento de segurança unificado que avalia e oferece oportunidades para aprimorar vários aspectos de segurança do ambiente de dados. Ela fornece uma visão abrangente da integridade da segurança de todos os seus ativos de nuvem híbrida.
Considerações sobre o desempenho
A maioria dos recursos de desempenho do SQL Server locais existentes também estão disponíveis em VMs (máquinas virtuais) do Azure. Entre as opções oferecidas está a compactação de dados, que pode aprimorar o desempenho de cargas de trabalho com uso intensivo de E/S enquanto diminui o tamanho do banco de dados. De maneira semelhante, o particionamento de tabela e de índice pode aprimorar o desempenho de consulta de tabelas grandes, melhorando o desempenho e a escalabilidade.
Particionamento de tabela
O particionamento de tabela oferece muitos benefícios, mas muitas vezes essa estratégia só é considerada quando a tabela fica grande o suficiente para começar a comprometer o desempenho da consulta. Identificar quais tabelas são candidatas ao particionamento é uma boa prática que pode levar a menos interrupções e intervenções. Quando você filtra dados usando a coluna de partição, somente um subconjunto deles é acessado, não a tabela inteira. De maneira semelhante, as operações de manutenção em uma tabela particionada reduzirão a duração da manutenção, por exemplo, compactando dados específicos em uma partição em particular ou recompilando partições específicas de um índice.
Quatro etapas principais são necessárias ao definir uma partição de tabela:
- A criação de grupos de arquivos, que define os arquivos envolvidos quando as partições são criadas.
- A criação da função de partição, que define as regras de partição com base na coluna especificada.
- A criação do esquema de partição, que define o grupo de arquivos de cada partição.
- A tabela a ser particionada.
O exemplo a seguir ilustra como criar uma função de partição para 1º de janeiro de 2021 a 1º de dezembro de 2021 e distribuir as partições entre diferentes grupos de arquivos.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Compactação de dados
O SQL Server oferece diferentes opções para compactar dados. Embora o SQL Server ainda armazene dados compactados em páginas de 8 KB, quando os dados são compactados, mais linhas de dados podem ser armazenadas em uma determinada página, o que permite que a consulta leia menos páginas. Ler menos páginas tem um benefício duplo: reduz a quantidade de E/S física executada e permite que mais linhas sejam armazenadas no pool de buffers, fazendo uso mais eficiente da memória. Recomendamos habilitar a compactação de página do banco de dados quando apropriado.
A desvantagem da compactação é que ela requer uma pequena quantidade de sobrecarga de CPU. No entanto, na maioria dos casos, os benefícios da E/S de armazenamento compensam qualquer uso de processador adicional.
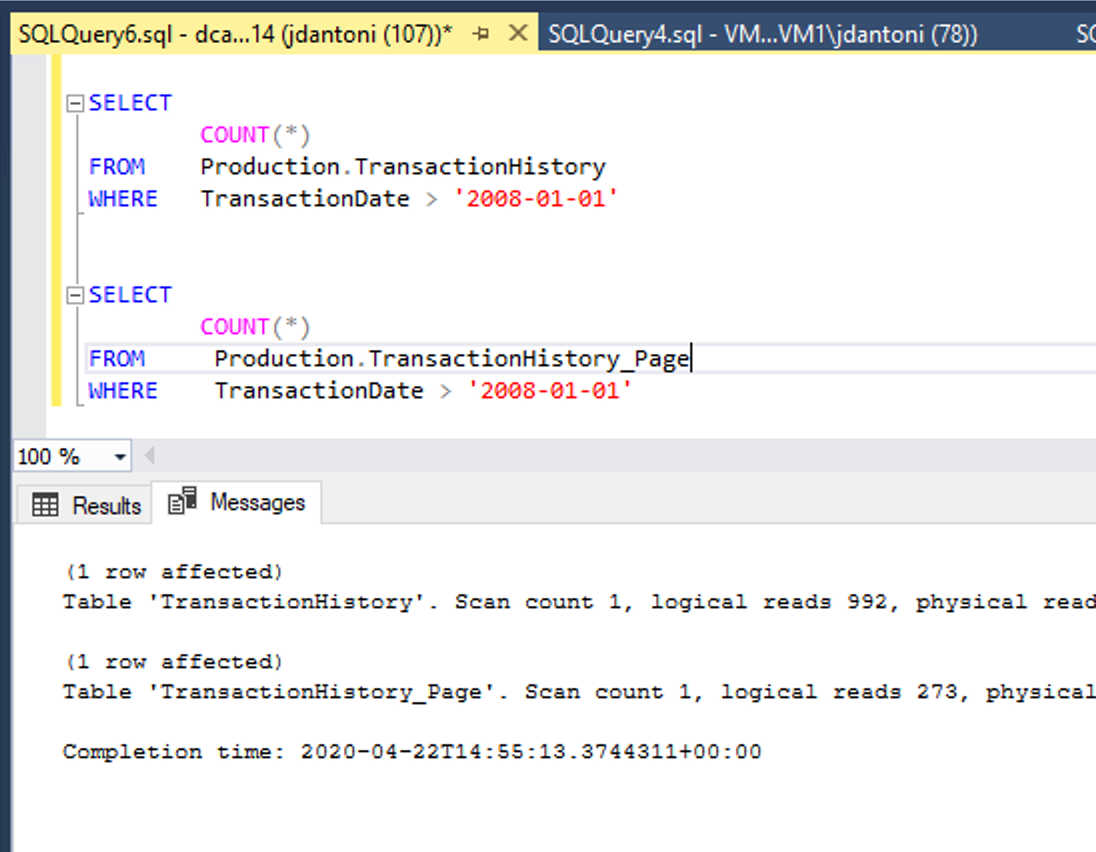
A imagem acima mostra esse benefício de desempenho. Essas tabelas têm os mesmos índices subjacentes, a única diferença é que os índices clusterizados e não clusterizados na tabela Production.TransactionHistory_Page são compactados por página. A consulta em relação ao objeto compactado por página executa 72% menos leituras lógicas do que a consulta que usa os objetos descompactados.
A compactação é implementada no SQL Server no nível do objeto. Cada índice ou tabela pode ser compactado individualmente e você tem a opção de compactar partições em uma tabela ou índice particionado. Você pode avaliar quanto espaço será salvo usando o procedimento armazenado do sistema sp_estimate_data_compression_savings. Antes do SQL Server 2019, esse procedimento não oferecia suporte a índices columnstore ou à compactação de arquivamento columnstore.
Compactação de linha – a compactação de linha é bastante básica e não gera muita sobrecarga. No entanto, ela não oferece a mesma quantidade de compactação (medida pela redução percentual no espaço de armazenamento necessário) que a compactação de página pode oferecer. Basicamente, a compactação de linha armazena cada valor em cada coluna em uma linha na quantidade mínima de espaço necessária para armazenar esse valor. Ela usa um formato de armazenamento de comprimento variável para tipos de dados numéricos como inteiro, flutuante e decimal e armazena cadeias de caracteres de comprimento fixo usando o formato de comprimento variável.
Compactação de página – a compactação de página é um superconjunto de compactação de linha, pois todas as páginas serão compactadas inicialmente antes de aplicar a compactação de página. Em seguida, uma combinação de técnicas denominada compactação de prefixo e dicionário é aplicada aos dados. A compactação de prefixo elimina dados redundantes em uma só coluna, armazenando ponteiros de volta para o cabeçalho da página. Após essa etapa, a compactação de dicionário procura valores repetidos em uma página e os substitui por ponteiros, reduzindo ainda mais o armazenamento. Quanto mais redundância nos dados, maior a economia de espaço ao compactar seus dados.
Compactação de arquivamento de columnstore – os objetos columnstore sempre são compactados, no entanto, eles podem ser ainda mais compactados usando a compactação de arquivamento, que usa o algoritmo de compactação XPRESS da Microsoft nos dados. Esse tipo de compactação é mais apropriado para dados lidos com pouca frequência, mas que precisam ser retidos por motivos comerciais ou regulatórios. Embora esses dados sejam compactados ainda mais, o custo da CPU da descompactação tende a superar os ganhos de desempenho da redução de E/S.
Opções adicionais
Veja abaixo uma lista de recursos e ações adicionais do SQL Server a serem considerados para cargas de trabalho de produção:
- Habilite a compactação de backup
- Habilite a inicialização instantânea de arquivos para arquivos de dados
- Limite o aumento automático do banco de dados
- Desabilitar autoshrink/autoclose para os bancos de dados
- Mova todos os bancos de dados para discos de dados, incluindo bancos de dados do sistema
- Mova o log de erros do SQL Server e os diretórios de arquivos de rastreamento para discos de dados
- Definir o limite máximo de memória do SQL Server
- Habilitar o bloqueio de páginas na memória
- Habilitar a otimização para cargas de trabalho ad hoc para ambientes OLTP pesados
- Habilite o Repositório de Consultas.
- Agendar trabalhos do SQL Server Agent para executar trabalhos de DBCC CHECKDB, reorganização de índice, recompilação de índice e atualização de estatísticas
- Monitorar e gerenciar a integridade e o tamanho dos arquivos de log de transações
Para saber mais sobre as melhores práticas de desempenho, confira Melhores práticas para o SQL Server em VMs do Azure.