Explicar o processo de data factory
Fluxos de trabalho controlados por dados
Os pipelines (fluxos de trabalho controlados por dados) no Azure Data Factory normalmente executam as quatro etapas a seguir:
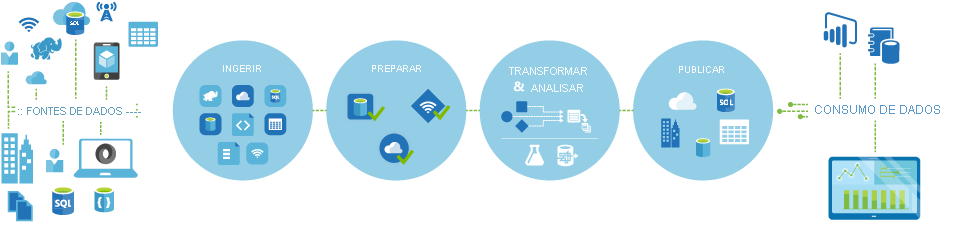
Conectar e coletar
A primeira etapa na construção de um sistema de orquestração é definir e conectar todas as fontes de dados necessárias entre si, como os bancos de dados, compartilhamento de arquivos e serviços Web de FTP. A próxima etapa é ingerir os dados conforme necessário para um local centralizado para processamento posterior.
Transformar e enriquecer
Serviços de computação, como o Databricks e Machine Learning, podem ser usados para preparar ou produzir dados transformados em uma agenda passível de manutenção e controlada para alimentar ambientes de produção com dados limpos e transformados. Em alguns casos, você pode até mesmo aumentar os dados de origem com dados adicionais para auxiliar a análise ou consolidá-los por meio de um processo de normalização para ser usado em um teste de Machine Learning como exemplo.
Publicação
Depois que os dados brutos tiverem sido refinados para uma forma consumível pronta para a empresa a partir da fase transformar e enriquecer, você poderá carregar os dados no Azure Data Warehouse, no Banco de Dados SQL do Azure, no Azure Cosmos DB ou em qualquer mecanismo de análise que seus usuários empresariais possam apontar em suas ferramentas de business intelligence.
Monitoramento
O Azure Data Factory tem suporte interno para monitoramento de pipeline por meio do Azure Monitor, API, PowerShell, logs do Azure Monitor e painéis de integridade no portal do Azure, com o objetivo de monitorar as atividades e os pipelines agendados para taxas de êxito e falha.