Entender o Azure Data Factory
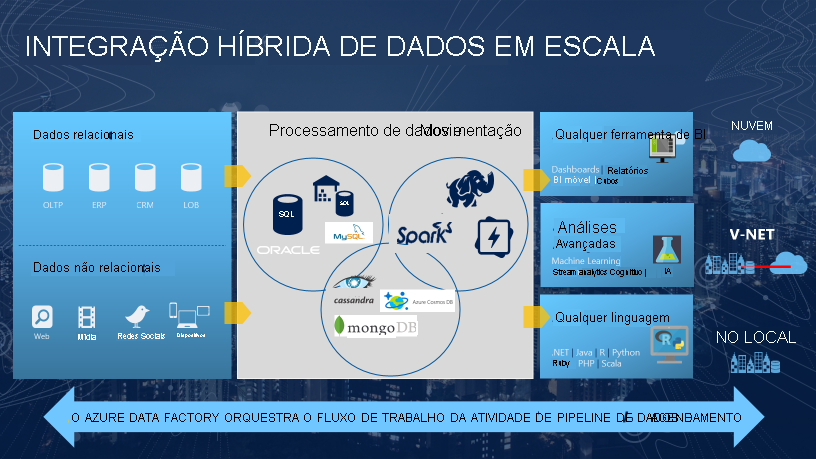
A necessidade de disparar a movimentação de dados em lote ou configurar um agendamento regular é um requisito para a maioria das soluções de análise. O Azure Data Factory (ADF) é o serviço que pode ser usado para atender a esse requisito. O ADF fornece um serviço de integração de dados baseado em nuvem que orquestra a movimentação e a transformação de dados entre vários armazenamentos de dados e recursos de computação.
O Azure Data Factory é um serviço de integração de dados e ETL baseado em nuvem que permite criar fluxos de trabalho orientados a dados para orquestração da movimentação e transformação de dados em escala. Usando o Azure Data Factory, é possível criar e agendar fluxos de trabalho orientados a dados (chamados de pipelines) que podem ingerir dados de diferentes repositórios de dados. Você pode criar processos de ETL complexos que transformam os dados visualmente com fluxos de dados ou usando serviços de computação, como o Azure HDInsight Hadoop, o Azure Databricks e o Azure Synapse Analytics.
Grande parte da funcionalidade do Azure Data Factory aparece no Azure Synapse Analytics como um recurso referido como pipelines, que permitem integrar os pipelines de dados entre os pools do SQL, os Pools do Spark e o SQL Serverless, fornecendo uma única oferta para todas as suas necessidades analíticas.
O que significa orquestração
Para usar uma analogia, pense em uma orquestra sinfônica. O membro central da orquestra é o regente. O regente não toca os instrumentos. Ele conduz os membros da orquestra sinfônica por toda a peça musical que estão executando. Os músicos usam suas próprias habilidades para produzir sons específicos em vários estágios da sinfonia para que eles possam aprender apenas algumas partes da música. O regente da orquestra toda a peça musical e, portanto, está ciente de toda a partitura que está sendo executada. Ele também usará movimentos de braço específicos que fornecem instruções para os músicos sobre como uma peça da música deve ser tocada.
O ADF pode usar uma abordagem semelhante, embora tenha funcionalidade nativa para ingerir e transformar dados. Às vezes, ele instruirá outro serviço a executar o trabalho real necessário em seu nome, como um Databricks para executar uma consulta de transformação. Portanto, nesse caso, seria o Databricks que executa o trabalho, e não o ADF. O ADF simplesmente orquestra a execução da consulta e, em seguida, fornece os pipelines para mover os dados para a próxima etapa ou destino.
Ele também fornece visualizações avançadas para exibir a linhagem e as dependências entre os pipelines de dados e monitorar todos os seus pipelines de dados em uma única exibição unificada, a fim de identificar os problemas e configurar alertas de monitoramento facilmente.