Entender e testar o modelo
Criamos um modelo de machine learning! Vamos testá-lo e ver como se ele está funcionando bem.
Desempenho do modelo
A Visão Personalizada exibe três métricas quando você testa seu modelo. As métricas são indicadores que podem ajudar você a entender o desempenho de seu modelo. Os indicadores não mostram o nível de precisão ou veracidade do modelo. Eles informam apenas o desempenho do modelo em relação aos dados fornecidos. O nível de desempenho do modelo sobre dados conhecidos dá a você uma ideia de qual será o desempenho dele em relação a novos dados.
As seguintes métricas são fornecidas para todo o modelo e para cada classe:
| Métrica | Descrição |
|---|---|
precision |
Se seu modelo previr uma marca, essa métrica indicará a probabilidade dessa ser a marca correta. |
recall |
Essa métrica indica a porcentagem de marcas que seu modelo previu corretamente versus as marcas que o modelo deveria prever corretamente. |
average precision |
Mede o desempenho do modelo computando a precisão e o recall em limites diferentes. |
Quando testarmos nosso modelo de Visão Personalizada, veremos os números de cada uma dessas métricas nos resultados do teste de iteração.
Erros comuns
Antes de testar nosso modelo, vamos dar uma olhada em alguns "erros de principiante" aos quais você deve se atentar quando começar a criar modelos de machine learning pela primeira vez.
Como usar dados desbalanceados
Quando estiver implantando o modelo, o seguinte aviso poderá aparecer:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
Esse aviso indica que você não tem um número par de amostras para cada classe de dados. Embora você tenha várias opções nesse cenário, uma maneira comum de resolver esse desbalanceamento de dados é usar a SMOTE (Técnica de Superamostragem Minoritária Sintética). A SMOTE duplica exemplos de treinamento do pool de treinamento existente.
Observação
Em nosso modelo, talvez você não veja esse aviso, especialmente se tiver carregado apenas uma fração do conjunto de dados. O subconjunto de dados do modelo Falcão de cauda vermelha (forma escura) contém menos de 60 fotos em comparação com os outros modelos que têm mais de 100 fotos. O uso de dados desequilibrados é algo a ser observado em qualquer modelo de machine learning.
Como sobreajustar o modelo
Se você não tiver dados suficientes, ou seus dados não forem suficientemente diversificados, seu modelo poderá se tornar sobreajustado. Quando um modelo está sobreajustado, ele conhece bem o conjunto de dados fornecido e é sobreajustado para os padrões desses dados. Nesse caso, o modelo tem um bom desempenho nos dados de treinamento, mas terá um desempenho insatisfatório em dados desconhecidos. Por esse motivo, sempre usamos novos dados para testar um modelo!
Como usar dados de treinamento para o teste
Assim como ocorre com o sobreajuste, se você testar o modelo usando os mesmos dados usados no treinamento do modelo, este parecerá ter um bom desempenho. Mas quando você implantar o modelo para produção, ele provavelmente terá um desempenho insatisfatório.
Como usar dados inválidos
Outro erro comum é usar dados inválidos para treinar o modelo. Alguns dados podem realmente reduzir a precisão do seu modelo. Por exemplo, o uso de dados com "ruído" pode reduzir a precisão de um modelo. Em dados com ruído, muitas informações que não são úteis estão presentes no conjunto de dados, gerando confusão no modelo. Ter mais dados só é melhor se estes forem adequados para uso pelo modelo. Pode ser necessário limpar os dados ou remover recursos para melhorar a precisão do modelo.
Testar o modelo
De acordo com as métricas fornecidas pela Visão Personalizada, nosso modelo está apresentando um desempenho satisfatório. Vamos testar nosso modelo e ver como ele é executado em dados não vistos. Usaremos uma imagem de um pássaro de uma pesquisa na internet.
Em seu navegador da Web, pesquise uma imagem de um pássaro que corresponda a uma das espécies que você treinou para reconhecer o modelo. Copie a URL da imagem.
No portal da Visão Personalizada, selecione o projeto Classificação de Pássaros.
Na barra de menus superior, selecione Teste Rápido.
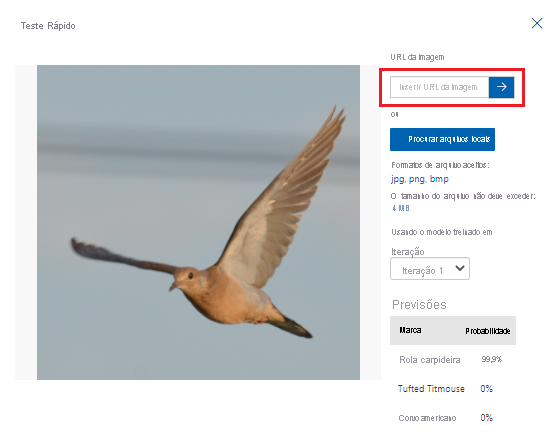
Em Teste Rápido, cole a URL em URL da Imagem e pressione Enter para testar a precisão do modelo. A previsão é mostrada na janela.
A Visão Personalizada analisa a imagem a fim de testar a precisão do modelo e exibe os resultados:
Na próxima etapa, implantaremos o modelo. Depois que o modelo é implantado, podemos fazer mais testes com o ponto de extremidade que criamos.