Exercício – Executar consultas no cluster do Spark para HDInsight
Neste exercício, você aprenderá a criar um dataframe de um arquivo CSV e a executar consultas de SQL Spark interativas em um cluster do Apache Spark no Azure HDInsight. No Spark, um dataframe é uma coleção distribuída de dados organizados em colunas nomeadas. O dataframe é conceitualmente equivalente a uma tabela em um banco de dados relacional ou uma estrutura de dados em R/Python.
Neste tutorial, você aprenderá como:
- Criar um dataframe usando um arquivo CSV
- Executar consultas no dataframe
Criar um dataframe usando um arquivo CSV
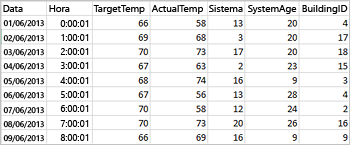
O arquivo CSV de exemplo a seguir contém informações de temperatura de um edifício e é armazenado no sistema de arquivos do cluster do Spark.
Cole o código a seguir em uma célula vazia do Jupyter Notebook e pressione SHIFT + ENTER para executar o código. O código importa os tipos obrigatórios necessários para este cenário
from pyspark.sql import * from pyspark.sql. types import *Ao executar uma consulta interativa no Jupyter, a legenda da guia ou da janela do navegador da Web mostra um status (Ocupado) ao lado do título do notebook. Você também verá um círculo sólido ao lado do texto PySpark no canto superior direito. Após a conclusão do trabalho, isso será alterado para um círculo vazio.
Execute o seguinte código para criar um dataframe e uma tabela temporária (hvac) executando o código a seguir.
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
Executar consultas no dataframe
Depois que a tabela for criada, você poderá executar uma consulta interativa nos dados.
Execute o seguinte código em uma célula vazia do notebook:
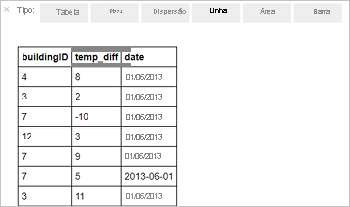
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"A saída tabular a seguir é exibida.
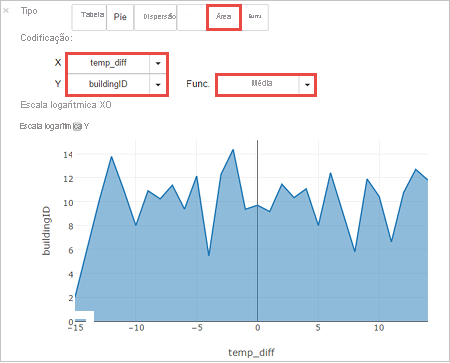
Você também pode ver os resultados em outras visualizações. Para ver um gráfico de área para a mesma saída, selecione Área e, em seguida, defina outros valores conforme mostrado.
Na barra de menus do notebook, acesse Arquivo > Salvar e ponto de verificação.
Encerre o notebook para liberar os recursos do cluster: na barra de menus do notebook, navegue até Arquivo > Fechar e parar.