Usar a API de Conversão de Fala em Texto da IA do Azure
O serviço de Fala de IA do Azure é compatível com o reconhecimento de fala por meio de duas APIs REST:
- A API de conversão de fala em texto, que é a principal maneira de fazer o reconhecimento de fala.
- A API de conversão de fala em texto para áudio curto, que é otimizada para fluxos de áudio curtos, de até 60 segundos.
É possível usar a API para o reconhecimento de fala interativo, dependendo do tamanho esperado da entrada falada. Também é possível usar a API de conversão de fala em texto para a transcrição do lote, transcrevendo vários arquivos de áudio para texto como uma operação em lote.
Para obter mais informações sobre as APIs REST, consulte a documentação API REST de conversão de fala em texto. Na prática, a maioria dos aplicativos interativos habilitados para fala usa o serviço de Fala por meio de um SDK específico a uma linguagem (de programação).
Usar o SDK da Fala de IA do Azure
Embora os detalhes específicos variem, dependendo do SDK que está sendo usado (Python, C# etc.), há um padrão consistente para usar a API de conversão de fala em texto:
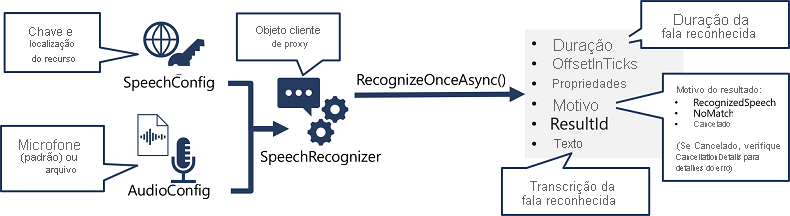
- Use um objeto SpeechConfig para encapsular as informações necessárias para se conectar ao seu recurso da Fala de IA do Azure. Especificamente, sua localização e chave.
- Como alternativa, use um AudioConfig para definir a fonte de entrada para o áudio a ser transcrito. Por padrão, a entrada é o microfone padrão do sistema, mas você também pode especificar um arquivo de áudio.
- Use SpeechConfig e AudioConfig para criar um objeto SpeechRecognizer. Esse objeto é um cliente proxy para a API de conversão de fala em texto.
- Use os métodos do objeto SpeechRecognizer para chamar as funções de API subjacentes. Por exemplo, o método RecognizeOnceAsync() usa o serviço de Fala de IA do Azure para traduzir de modo assíncrono um único enunciado falado.
- Processe a resposta do serviço de Fala de IA do Azure. No caso do método RecognizeOnceAsync(), o resultado é um objeto SpeechRecognitionResult que inclui as seguintes propriedades:
- Duration
- OffsetInTicks
- Propriedades
- Motivo
- ResultId
- Texto
Se a operação tiver sido bem-sucedida, a propriedade Reason terá o valor enumerado RecognizedSpeech e a propriedade Text conterá a transcrição. Outros valores possíveis para Resultado incluem NoMatch (indicando que o áudio foi analisado com êxito, mas nenhuma fala foi reconhecida) ou Cancelado, indicando que ocorreu um erro (nesse caso, você pode verificar a propriedade CancellationReason na coleção Propriedades para determinar o que deu errado).