Habilidade de classificação de textos personalizada
A classificação de textos personalizada permite mapear uma passagem de texto para diferentes classes definidas pelo usuário. Por exemplo, você pode treinar um modelo na sinopse na contracapa de livros para identificar automaticamente o gênero de um livro. Em seguida, você usa o gênero identificado para enriquecer o mecanismo de pesquisa de sua loja online com uma faceta de gênero.
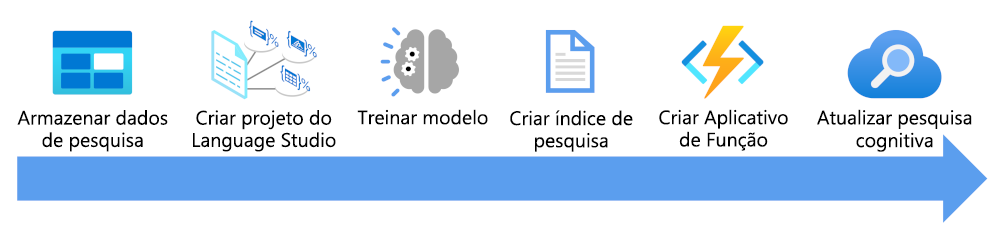
Aqui, você verá o que precisa considerar para enriquecer um índice de pesquisa usando um modelo de classificação de textos personalizada:
- Armazenar seus documentos para que eles possam ser acessados por indexadores do Estúdio de Linguagem e da Pesquisa de IA do Azure.
- Criar um projeto de classificação de textos personalizada.
- Treinar e testar o modelo.
- Criar um índice de pesquisa com base nos documentos armazenados.
- Crie um aplicativo de funções que use seu modelo de treinamento implantado.
- Atualizar a solução de pesquisa, o índice, o indexador e o conjunto de habilidades personalizado.
Armazene seus dados
O Armazenamento de Blobs do Azure pode ser acessado do Language Studio e dos Serviços de IA do Azure. O contêiner precisa ser acessível, portanto, a opção mais simples é escolher Contêiner, mas também é possível usar contêineres privados com alguma configuração adicional.
Junto com os dados, você também precisa ter uma maneira de atribuir classificações para cada documento. O Language Studio fornece uma ferramenta gráfica que você pode usar para classificar cada documento, um por vez, manualmente.
É possível escolher entre dois tipos diferentes de projeto. Se um documento for mapeado para uma única classe, use um único projeto de classificação de rótulo. Caso queira mapear um documento para mais de uma classe, use o projeto de classificação de vários rótulos.
Se não quiser classificar manualmente cada documento, você poderá rotular todos os documentos antes de criar o projeto de Linguagem de IA do Azure. Esse processo envolve a criação de um documento JSON de rótulos neste formato:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Você adicionará quantas classes tiver à matriz classes. Você adiciona uma entrada para cada documento na matriz documents, incluindo a quais classes o documento corresponde.
Criar seu projeto de Linguagem de IA do Azure
Há duas maneiras de criar seu projeto do de Linguagem de IA do Azure. Caso comece a usar o Estúdio de Linguagem sem criar um serviço de linguagem no portal do Azure, o Estúdio de Linguagem oferecerá para criar um para você.
A maneira mais flexível de criar um projeto de Linguagem de IA do Azure é primeiro criar seu serviço de linguagem usando o portal do Azure. Se você escolher essa opção, terá a opção de adicionar recursos personalizados.
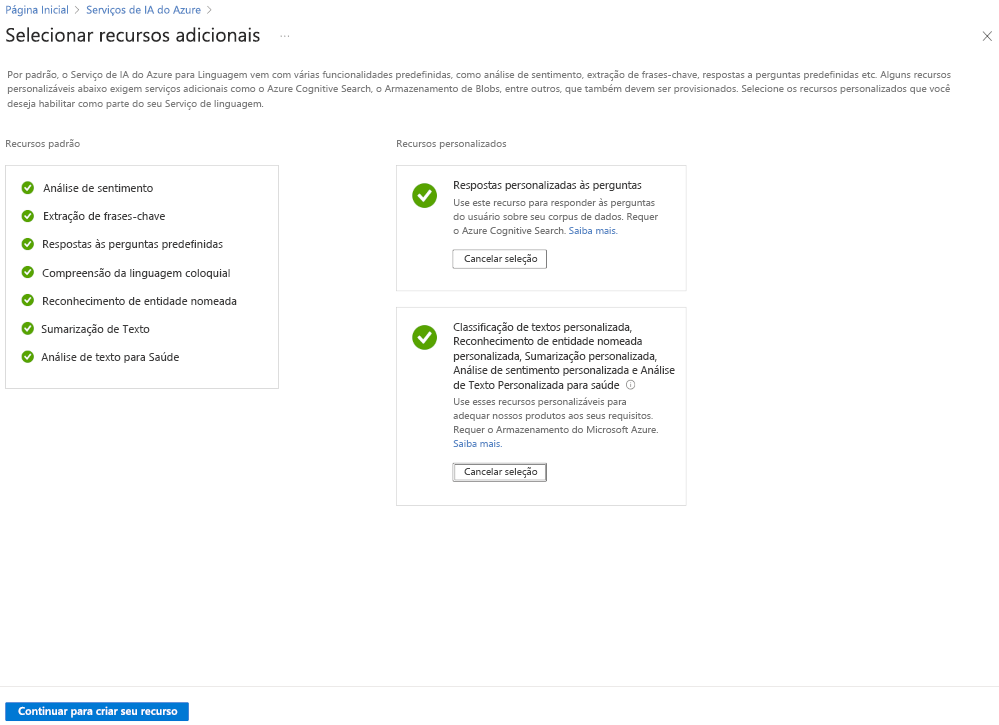
Como você vai criar uma classificação de textos personalizada, selecione esse recurso personalizado ao criar o serviço de linguagem. Você também vinculará o serviço de linguagem a uma conta de armazenamento usando esse método.
Após o recurso ser implantado, você poderá navegar diretamente para o Language Studio no painel de visão geral do serviço de linguagem. Em seguida, você pode criar um projeto de classificação de textos personalizada.
Observação
Caso crie seu serviço de idioma do Language Studio, talvez seja necessário seguir estas etapas. Defina funções para sua conta de armazenamento e recursos de Linguagem do Azure para conectar seu contêiner de armazenamento ao seu projeto de classificação de texto personalizado.
Treinar o modelo de classificação
Assim como ocorre com todos os modelos de IA, você precisa ter dados identificados que possam ser usados para treiná-los. O modelo precisa ver exemplos de como mapear dados para uma classe e ter alguns exemplos que possa usar para testes. Você pode optar por permitir que o modelo divida automaticamente seus dados de treinamento. Por padrão, ele usará 80% dos documentos para treinar o modelo e 20% para fazer um teste cego. Se você tiver alguns documentos específicos com os quais deseja testar o modelo, poderá rotular esses documentos para teste.

No Language Studio, em seu projeto, selecione Rotulagem de dados. Você verá todos os seus documentos. Selecione cada documento que deseja adicionar ao conjunto de testes e selecione Testar o desempenho do modelo. Salve os rótulos atualizados e crie um trabalho de treinamento.
Criar o índice de pesquisa
Não há nada específico que você precisa fazer para criar um índice de pesquisa que será enriquecido por um modelo de classificação de textos personalizada. Siga as etapas em Criar uma solução da Pesquisa de IA do Azure. Você atualizará o índice, o indexador e a habilidade personalizada depois de criar um aplicativo de funções.
Criar um aplicativo de funções do Azure
Você pode escolher a linguagem e as tecnologias desejadas para o aplicativo de funções. O aplicativo precisa ser capaz de passar JSON para o ponto de extremidade de classificação de textos personalizada, por exemplo:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Em seguida, processe a resposta JSON do modelo, por exemplo:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
Em seguida, a função retorna uma mensagem JSON estruturada a um conjunto de habilidades personalizado na Pesquisa de IA, por exemplo:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Há cinco coisas que o aplicativo de funções precisa conhecer:
- O texto a ser classificado.
- O ponto de extremidade do modelo implantado de classificação de textos personalizada.
- A chave primária do projeto de classificação de textos personalizada.
- O nome do projeto.
- O nome da implantação.
O texto a ser classificado é passado do conjunto de habilidades personalizado na Pesquisa de IA para a função como entrada. Os quatro itens restantes podem ser encontrados no Estúdio de Linguagem.

O ponto de extremidade e o nome da implantação estão no painel de implantação do modelo.

O nome do projeto e a chave primária estão no painel de configurações do projeto.
Atualizar a sua solução de Pesquisa de IA do Azure
Há três alterações no portal do Azure que você precisa fazer para enriquecer o índice de pesquisa:
- Você precisa adicionar um campo ao índice para armazenar o enriquecimento da classificação de textos personalizada.
- Você precisa adicionar um conjunto de habilidades personalizado para chamar o aplicativo de funções com o texto a ser classificado.
- Você precisa mapear a resposta do conjunto de habilidades para o índice.
Adicionar um campo a um índice existente
No portal do Azure, acesse o recurso de Pesquisa de IA, selecione o índice e você adicionará o JSON neste formato:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Esse JSON adiciona um campo composto ao índice para armazenar a classe em um campo category pesquisável. O segundo campo confidenceScore armazena a porcentagem de confiança em um campo duplo.
Editar o conjunto de habilidades personalizado
No portal do Azure, selecione o conjunto de habilidades e adicione o JSON neste formato:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Essa definição de habilidade WebApiSill especifica que o idioma e o conteúdo de um documento são passados como entradas para o aplicativo de funções. O aplicativo retornará texto JSON chamado class.
Mapear a saída do aplicativo de funções para o índice
A última alteração é mapear a saída para o índice. No portal do Azure, selecione o indexador e edite o JSON para ter um novo mapeamento de saída:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
O indexador agora sabe que a saída do aplicativo de funções document/class deve ser armazenada no campo classifiedtext. Como ele foi definido como um campo composto, o aplicativo de funções precisa retornar uma matriz JSON contendo um campo category e confidenceScore.
Agora, você pode pesquisar em um índice de pesquisa enriquecido para seu texto classificado personalizado.