Descrever o processamento de consulta inteligente
No SQL Server 2017 e 2019 e com o SQL do Azure, a Microsoft introduziu muitos recursos novos nos níveis de compatibilidade 140 e 150. Muitos desses recursos corrigem o que anteriormente eram antipadrões, como o uso de funções de valor escalar e o uso de variáveis de tabela.
Esses recursos dividem-se em algumas famílias de recursos:
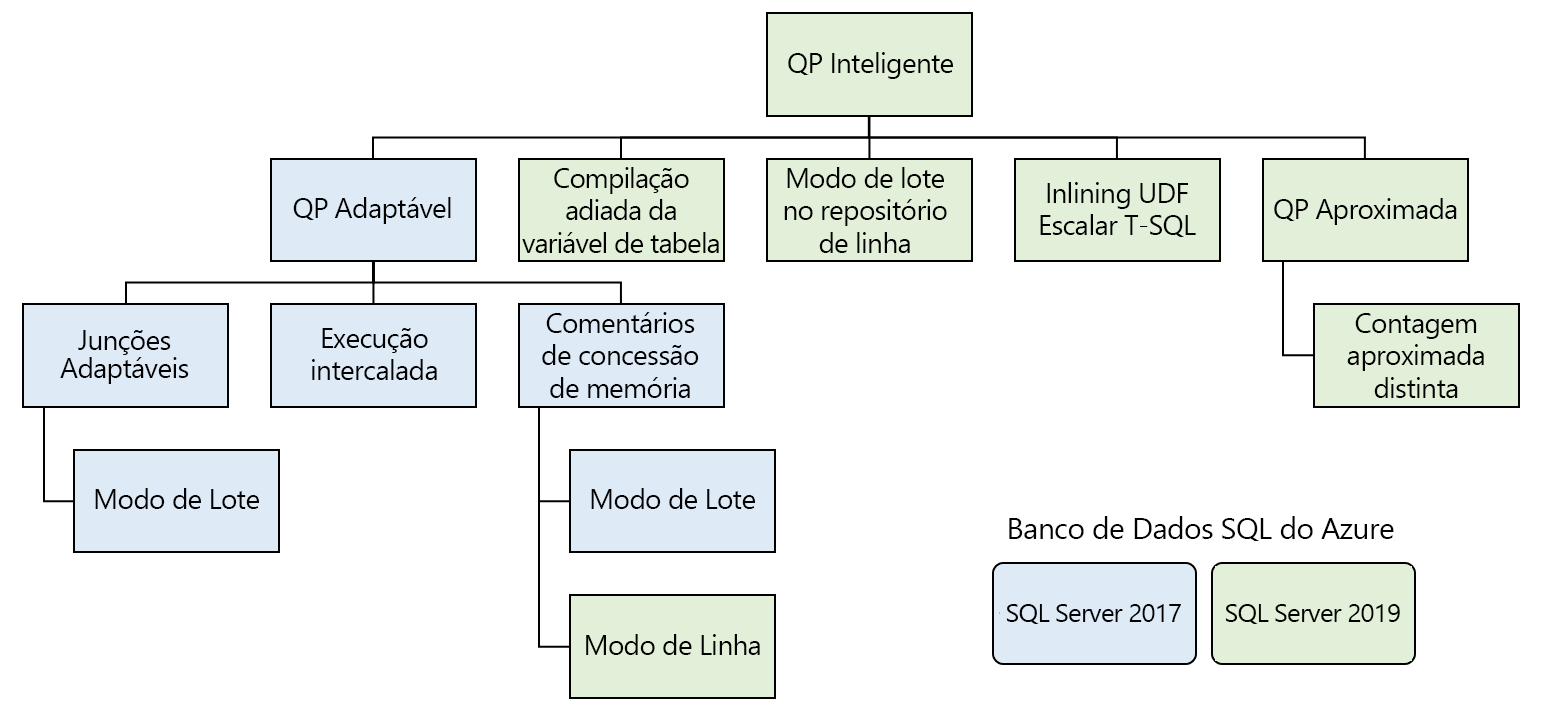
O processamento inteligente de consultas inclui recursos que melhoram o desempenho da carga de trabalho existente com o mínimo esforço de implementação.
Para tornar as cargas de trabalho automaticamente qualificadas para processamento de consulta inteligente, altere o nível de compatibilidade do banco de dados aplicável para 150. Por exemplo:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Processamento de consulta adaptável
O processamento de consulta adaptável inclui muitas opções que tornam o processamento de consultas mais dinâmico, com base no contexto de execução de uma consulta. Essas opções incluem vários recursos que aprimoram o processamento de consultas.
Junções adaptáveis – o mecanismo de banco de dados adia a escolha da junção entre o hash e os loops aninhados com base no número de linhas que entrarão na junção. No momento, as junções adaptáveis funcionam apenas no modo de execução em lotes.
Execução intercalada – no momento, esse recurso dá suporte a MSTVF (funções com valor de tabela de várias instruções). Antes do SQL Server 2017, as MSTVFs usavam uma estimativa de linha fixa de uma ou 100 linhas, dependendo da versão do SQL Server. Essa estimativa poderá levar a planos de consulta de qualidade inferior se a função retornar muito mais linhas. Uma contagem de linhas real é gerada com base na MSTVF antes de o restante do plano ser compilado com a execução intercalada.
Comentários de concessão de memória – o SQL Server gera uma concessão de memória no plano inicial da consulta, com base nas estimativas de contagem de linhas das estatísticas. A distorção de dados grave pode levar a estimativas de contagens de linhas sub ou superestimadas, o que pode causar concessões excessivas de memória que diminuem a simultaneidade ou concessões insuficientes, que podem fazer com que a consulta despeje dados para o tempdb. Com os Comentários de concessão de memória, o SQL Server detecta essas condições e diminui ou aumenta a quantidade de memória concedida à consulta para evitar o despejo ou a superalocação.
Esses recursos são habilitados automaticamente no modo de compatibilidade 150 e não exigem nenhuma outra alteração para serem habilitados.
Compilação adiada de variável da tabela
Assim como as MSTVFs, as variáveis de tabela nos planos de execução do SQL Server realizam uma estimativa de contagem fixa de uma linha. De maneira muito semelhante às MSTVFs, essa estimativa fixa levou a um desempenho insatisfatório quando a variável tinha uma contagem de linhas muito maior do que o esperado. Com o SQL Server 2019, as variáveis de tabela agora são analisadas e têm uma contagem de linhas real. A compilação adiada é semelhante à execução intercalada para MSTVFs, exceto que ela é executada na primeira compilação da consulta, em vez de dinamicamente dentro do plano de execução.
Modo de lote no repositório de linha
O modo de execução em lote permite que os dados sejam processados em lotes em vez de linha por linha. As consultas que incorrem em custos de CPU significativos para cálculos e agregações verão o maior benefício desse modelo de processamento. Ao separar o processamento em lotes e os índices columnstore, mais cargas de trabalho podem se beneficiar do processamento do modo de lote.
Inlining da função escalar definida pelo usuário
Em versões mais antigas do SQL Server, as funções escalares apresentaram um desempenho insatisfatório por diversos motivos. As funções escalares foram executadas iterativamente, processando de maneira eficiente uma linha por vez. Elas não tinham a estimativa de custo adequada em um plano de execução e não permitiam paralelismo em um plano de consulta. Com o inlining da função definida pelo usuário, essas funções são transformadas em subconsultas escalares no lugar do operador de função definido pelo usuário no plano de execução. Essa transformação pode levar a ganhos significativos no desempenho de consultas que envolvem chamadas de função escalar.
Contagem aproximada distinta
Um padrão de consulta do data warehouse comum é executar uma contagem distinta de pedidos ou usuários. Esse padrão de consulta pode ser caro em relação a uma tabela grande. A contagem aproximada distinta apresenta uma abordagem muito mais rápida para a coleta de uma contagem distinta ao agrupar as linhas. Essa função garante uma taxa de erro de 2% com um intervalo de confiança de 97%.