Computação sem servidor
Nos primórdios da computação em nuvem, os provedores de serviços de nuvem, como a Amazon e a Microsoft, se concentraram em oferecer uma ampla variedade de serviços de IaaS para seus clientes. Isso impulsionou o crescimento de nuvens públicas, permitindo que os clientes mudassem facilmente as cargas de trabalho executadas localmente em servidores físicos ou em máquinas virtuais para máquinas virtuais na nuvem. Mas junto com a IaaS, vem a responsabilidade. Uma organização que coloca uma VM para funcionar na nuvem também assume a responsabilidade de manter o que está dentro dessa VM – o sistema operacional, os runtimes que são necessários, os aplicativos que utilizam esses runtimes etc.
A PaaS muda parte dessa responsabilidade para o provedor de serviços de nuvem e impulsionou ainda mais os investimentos na nuvem. Com serviços como o AWS Elastic Beanstalk e o Serviço de Aplicativo do Azure, os clientes podem provisionar servidores Web virtuais com runtimes populares, como Java, Node.js e Microsoft .NET, além de fazer com que o software seja executado neles em minutos. Embora as máquinas virtuais façam o trabalho pesado nos bastidores, a presença dessas máquinas virtuais é bastante abstraída. A PaaS permite que os clientes se concentrem nos aplicativos que escrevem para solucionar problemas de negócios, em vez de gastar ciclos gerenciando VMs e mantendo as plataformas atualizadas e com os devidos patches aplicados.
A computação sem servidor é uma inovação relativamente recente na computação em nuvem que leva essas abstrações ainda mais longe. Suponha que sua organização escreva e mantenha um código que executa backups noturnos de dados críticos, realiza execuções de faturamento semanais ou transmite um pagamento eletrônico sempre que uma fatura é carregada no armazenamento em nuvem. Nesse caso, a meta geral é executar esse código, no momento apropriado. Todo o resto é secundário, incluindo o local em que o código é armazenado e como e em que local ele é executado.
Você poderia adotar uma abordagem de IaaS, criando uma ou mais VMs para executar seu código e instalar as plataformas e bibliotecas necessárias. Você pode provisionar um Elastic Beanstalk ou uma instância do Serviço de Aplicativo e hospedar o código ali. Ou você pode usar um runtime de função como o AWS Lambda ou o Azure Functions para executar seu código sempre que desejar, sem se preocupar com como ou em que local ele está hospedado. O AWS Lambda e o Azure Functions e o Google Cloud Functions são exemplos de computação sem servidor (especificamente, de funções sem servidor). Todos os três representam a próxima etapa na evolução natural da computação em nuvem, originada na IaaS, em que você tem a responsabilidade por tudo, evoluindo depois para a computação sem servidor, em que você se concentra nas ações que deseja executar (o código que deseja executar) na nuvem e permite que o provedor de serviços de nuvem gerencie todo o resto.
As funções sem servidor executadas por runtimes de função na nuvem são a maneira mais comum de computação sem servidor, mas não a única. A Amazon, a Microsoft e o Google oferecem versões sem servidor de alguns de seus outros serviços de PaaS, incluindo bancos de dados sem servidor. Alguns provedores dão suporte para fluxos de trabalho sem servidor, que permitem definir fluxos de trabalho de negócios na nuvem e executá-los em resposta a eventos externos, como faturas sendo carregadas no armazenamento em nuvem, temporizadores que são acionados em intervalos especificados ou emails que acessam uma caixa de entrada, tudo isso muitas vezes sem escrever uma única linha de código. Por fim, muitos dos serviços de contêiner oferecidos pelos provedores de serviço de nuvem, incluindo as Instâncias de Contêiner do Azure e o AWS Elastic Container Service, se qualificam como exemplos de computação sem servidor, pois permitem executar contêineres na nuvem e, simultaneamente, abstraem a infraestrutura subjacente.
Benefícios da computação sem servidor
A computação sem servidor oferece três benefícios principais para as organizações que aproveitam a computação em nuvem:
Custos de computação mais baixos: Os clientes normalmente pagam encargos mensais por máquinas virtuais IaaS e serviços de PaaS, como o Elastic Beanstalk e o Serviço de Aplicativo do Azure. A cobrança continua mesmo que os serviços estejam ociosos. No entanto, a maioria dos serviços de computação sem servidor dá suporte a preços por consumo, permitindo que você seja cobrado apenas pelo tempo em que o código está sendo executado. Imagine que você dedique uma VM de 100 dólares por mês para executar o código que realiza um backup noturno de dados críticos e que o código é executado por 30 minutos a cada noite. Você está pagando 100 dólares por mês para executar código para 1/48 de um mês, que equivale a menos de um dia. Implantar o mesmo código como uma função sem servidor pode custar um pouco mais de alguns dólares por mês. Com o preço por consumo, você não paga pelo tempo ocioso.
Escalabilidade automática: Os provedores de nuvem oferecem mecanismos para dimensionar serviços de IaaS em produtos como o AWS Auto Scaling e os conjuntos de dimensionamento de máquinas virtuais no Azure. Eles também fornecem opções manuais e automáticas de dimensionamento para serviços de PaaS. Mas mesmo que o dimensionamento seja executado automaticamente, um administrador de nuvem precisa habilitar o dimensionamento automático e configurá-lo para que o provedor de nuvem saiba como e quando o dimensionamento deve ocorrer. Uma das considerações subjacentes que os administradores devem fazer é que, como você paga por instâncias individuais de serviços de IaaS e PaaS, convém que você configure o serviço para dimensionar o suficiente, sem dimensionar demais. A computação sem servidor oferece a opção de escalar horizontalmente de forma transparente e automática para atender ao aumento da demanda e de reduzir horizontalmente quando a demanda diminui. Um administrador de nuvem normalmente não executa nenhuma configuração, exceto habilitar essa opção no serviço. Se você receber 100 solicitações ao mesmo tempo para executar uma função sem servidor, o provedor de serviços de nuvem garantirá que as solicitações possam ser executadas em paralelo (ou, na sua maior parte, em paralelo). O custo não é afetado porque, com o preço por consumo, o custo de executar uma função 100 vezes é o mesmo, independentemente de a execução ser serial ou paralela.
Custos administrativos reduzidos: A computação sem servidor permite que você se concentre na execução de código e fluxos de trabalho, transferindo simultaneamente a responsabilidade por todo o resto, incluindo a manutenção da plataforma subjacente, para o provedor de serviços de nuvem.
A computação sem servidor também tem desvantagens. Algumas das limitações a serem consideradas incluem:
Alguns runtimes de função impõem um limite para o tempo pelo qual uma função tem permissão para ser executada.
Alguns runtimes de função não garantem que uma função seja executada imediatamente, a menos que você esteja disposto a pagar mais para que isso aconteça. Com o Azure Functions configurado para utilizar o preço baseado em consumo, por exemplo, uma função pode não ser executada por até 10 minutos após ser disparada. Isso pode não ser um problema para um backup noturno. Você provavelmente não se importa se o backup é executado às 1h00 ou 1h10. Mas pode ser um ponto de interrupção para funções que são funções de tempo crítico – que devem ser executadas em tempo real (ou quase em tempo real).
As funções sem servidor geralmente não têm estado, ou seja, não podem armazenar dados internamente e esperar que eles persistam de uma invocação de função para a próxima. Elas podem usar serviços de armazenamento em nuvem externos, como o Amazon S3 e o Armazenamento do Azure, para manter dados entre chamadas diferentes, mas isso torna o código da função mais complexo.
Alguns provedores de serviço de nuvem dão suporte para funções com estado (o Azure chama-as de "funções duráveis"), mas as funções que mantêm o estado são uma adição relativamente recente à computação sem servidor e não têm compatibilidade universal.
Funções sem servidor
O exemplo mais comum de computação sem servidor são as funções sem servidor. Você carrega o código na nuvem e informa a ela quando executar. O código pode ser escrito em diversas linguagens, incluindo Java e C#.
A Figura 11 lista as linguagens de programação compatíveis com funções sem servidor no Azure, no AWS e no GCP no momento da redação deste artigo:
| Idioma | Azure Functions | AWS Lambda | Google Cloud Functions |
|---|---|---|---|
| C# | x | x | |
| F# | x | ||
| Go | x | x | |
| Java | x | x | |
| JavaScript (Node.js) | x | x | x |
| PowerShell | x | x | |
| Python | x | x | x |
| Ruby | x | ||
| TypeScript | x |
Figura 11: Linguagens de programação compatíveis com runtimes populares de funções sem servidor.
Quando cria uma função e fornece o código que ela executará, você também identifica o evento externo que faz com que a função seja executada. As plataformas de nuvem populares dão suporte a gatilhos de vários tipos, incluindo temporizadores, eventos que ocorrem em outros serviços de nuvem (como o carregamento de um documento no armazenamento em nuvem) e chamadas HTTP. É uma questão simples de carregar o código de cobrança em um runtime de função e configurá-lo para ser executado uma vez por dia, uma vez por semana ou uma vez por mês. É igualmente simples ativar uma função cada vez que uma fatura é carregada no armazenamento em nuvem (por exemplo, no Amazon S3 ou no Armazenamento do Azure) ou sempre que uma chamada é colocada em um ponto de extremidade REST associado à função.
As funções sem servidor são usadas frequentemente para realizar tarefas autônomas, como backups e cobranças noturnos. Elas também são usadas para conectar outros serviços de nuvem e compor soluções avançadas usando serviços de nuvem como blocos de construção. A Figura 12 apresenta uma dessas soluções, que é usada para combinar vários serviços do Azure para monitorar a atividade de ursos polares no Ártico. Uma função do Azure desempenha um papel fundamental na arquitetura, usando a saída do Azure Stream Analytics (disparada por uma chamada HTTP), recuperando uma foto do Armazenamento de Blobs do Azure e enviando essa foto para um modelo treinado com o Serviço de Visão Personalizada do Azure, que usa IA (inteligência artificial) para determinar se a foto contém um urso polar. A função é a cola que une o Stream Analytics, o Armazenamento de Blobs e o Serviço de Visão Personalizada.
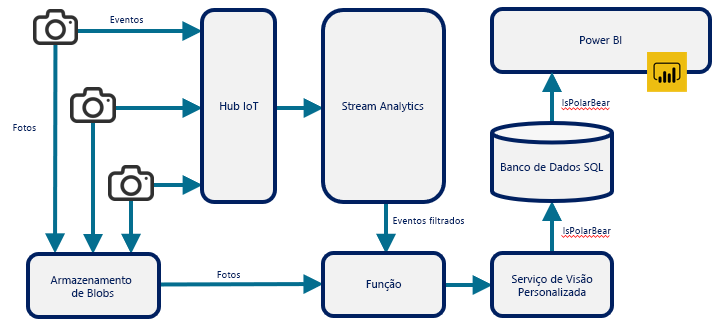
Figura 12: Usar uma função do Azure para conectar outros serviços do Azure.
Fluxos de trabalho sem servidor
Alguns serviços de computação sem servidor permitem que os clientes, sem escrever código, automatizem fluxos de trabalho. Os Aplicativos Lógicos do Azure, por exemplo, fornecem mais de 100 conectores integrados para fazer interface com fontes de dados que variam de bancos de dados Oracle a serviços de mídia social, como o X. Eles fornecem gatilhos para definir quando os fluxos de trabalho devem ser executados, por exemplo, quando um arquivo é carregado no Box.com ou quando algo é tuitado com uma hashtag específica. Eles também fornecem centenas de ações predefinidas que definem o que acontece quando um gatilho é acionado e que podem pode ser encadeadas em conjunto para formar fluxos de trabalho complexos, bem como condições que permitem que as ações sejam executadas condicionalmente. E são infinitamente extensíveis, porque uma das ações às quais os Aplicativos Lógicos do Azure dá suporte é uma que chama uma função do Azure. Se um fluxo de trabalho envolver uma lógica personalizada que não está encapsulada em uma ação, você poderá fornecer o código que implementa essa lógica e incluí-la no fluxo de trabalho como se ela fosse uma ação predefinida.
A Figura 13 mostra um desses fluxos de trabalho no designer de Aplicativos Lógicos do Azure1. Quando um email chega, os Aplicativos Lógicos entram em ação e buscam uma frase-chave na linha do assunto do email, verificando também se há um anexo presente. Se ambas as condições forem satisfeitas, o aplicativo lógico invocará uma função do Azure para retirar qualquer HTML do corpo do email. Em seguida, ele deposita o email limpo de HTML e todos os anexos que o acompanham no Armazenamento de Blobs do Azure e envia um email com links para os documentos relevantes no Armazenamento de Blobs, notificando as partes interessadas de que as informações estão disponíveis e aguardando revisão. Este exemplo combina dois paradigmas sem servidor: um aplicativo lógico que executa ações sem nenhuma necessidade de código (pelo menos não de código que você ou qualquer pessoa em sua organização tenha escrito) e uma função do Azure que contém o código que você forneceu para personalizar o fluxo de trabalho. Além disso, este exemplo representa a mudança que está ocorrendo na computação em nuvem: de máquinas virtuais do tipo "faça você mesmo" para abstrações de nível superior que permitem às organizações concentrar as energias na solução de problemas de negócios, em vez de no gerenciamento de máquinas virtuais e na instalação e manutenção de runtimes.
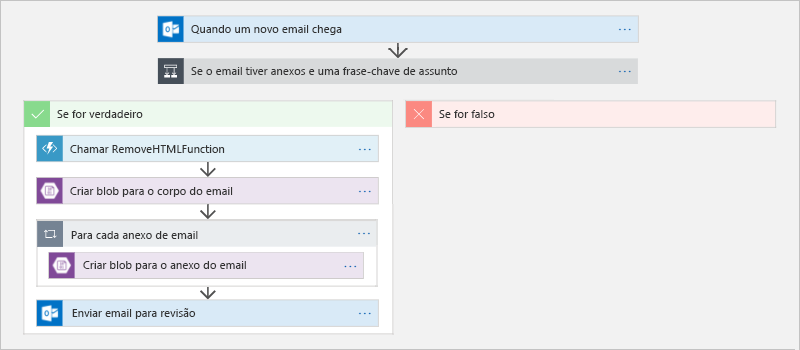
Figura 13: Definir um fluxo de trabalho nos Aplicativos Lógicos do Azure.
A Amazon oferece um serviço semelhante com o AWS Step Functions. Com o Step Functions, você pode compor fluxos de trabalho visuais que combinam outros serviços, como o AWS Lambda e o AWS ECS. Os fluxos de trabalho incluem uma série de etapas, com a saída de uma etapa servindo como entrada para a próxima. Assim como ocorre nos Aplicativos Lógicos do Azure, o AWS Step Functions fornece primitivos para ramificação e execução paralela, evitando que você precise escrever código para realizar essas tarefas. Na verdade, um fluxo de trabalho de negócios torna-se um diagrama de máquina de estado que é fácil de entender, de explicar para outras pessoas e de modificar.
Bancos de dados sem servidor
Nos primórdios da computação em nuvem, hospedar um banco de dados na nuvem significava provisionar uma máquina virtual e instalar um produto de banco de dados, como MySQL, PostgreSQL ou SQL Server. A PaaS alterou isso, oferecendo bancos de dados como um serviço. Com o Banco de Dados SQL do Azure ou o Amazon RDS (serviço de banco de dados relacional), por exemplo, basta provisionar uma instância e, em minutos, ter um banco de dados hospedado na nuvem pronto para atender aos clientes. Além disso, o provedor de serviços de nuvem mantém a plataforma do banco de dados atualizada, aplicando atualizações de software e patches.
Uma inovação mais recente na computação em nuvem é um banco de dados sem servidor, que oferece um modelo com relação preço/desempenho otimizada e que é ideal para bancos de dados individuais com padrões de uso irregulares. O Azure, por exemplo, oferece uma versão sem servidor do Banco de Dados SQL do Azure. Com a versão principal do Banco de Dados SQL do Azure, você escolhe um nível de preço/desempenho com base na carga máxima que você espera que o banco de dados suporte. Se as cargas forem "com picos" ou intermitentes, muitas vezes você acabará pagando como se o banco de dados experimentasse cargas altas o tempo todo.
A versão sem servidor do Banco de Dados SQL do Azure ameniza esse problema dimensionando o banco de dados conforme necessário para lidar com as cargas que ele enfrenta, com custos baseados na soma dos custos de computação e dos custos de armazenamento. Assim como acontece com funções sem servidor usando um modelo baseado em consumo, você paga apenas pelo que usa. A Amazon oferece um serviço semelhante com o AWS Aurora Serverless, que é uma versão sem servidor do serviço de banco de dados Aurora da Amazon. Já o Google oferece aos seus clientes um serviço de banco de dados NoSQL sem servidor conhecido como Google Cloud Firestore.
Referências
- Microsoft (2019). Automatize o tratamento de emails e anexos com os Aplicativos Lógicos do Azure. https://learn.microsoft.com/azure/logic-apps/tutorial-process-email-attachments-workflow.