Dimensionamento automatizado na nuvem
O escalonamento vertical ou horizontal para lidar com o aumento de demanda e a redução vertical ou horizontal para reduzir os custos quando a demanda diminui são procedimentos que podem ser executados manualmente pelos administradores de nuvem. Por exemplo, um administrador atento pode detectar que a demanda está aumentando e usar as ferramentas fornecidas pelos provedores de serviços de nuvem para colocar VMs adicionais online (escalar horizontalmente) ou substituir as VMs existentes por outras maiores, com mais CPU e mais memória (escalar verticalmente). A palavra-chave é "vigilante". Se a demanda atingir o pico e ninguém estiver ciente, o sistema como um todo pode ficar lento, até mesmo sem resposta, para os usuários finais. Por outro lado, se você escalar verticalmente ou horizontalmente para lidar com cargas pesadas e não reduzir de volta quando a carga diminuir, você acabará pagando por recursos dois quais não precisa.
É por isso que as plataformas de nuvem populares oferecem mecanismos de dimensionamento automático mecanismos para dimensionar recursos em resposta à demanda flutuante, sem intervenção humana. Há duas abordagens principais para o dimensionamento automático:
Com base no tempo – dimensionamento de recursos segundo um agendamento predeterminado. Por exemplo, se o site da sua organização tiver as cargas mais altas durante o horário de trabalho, configure o dimensionamento automático para que os recursos aumentem ou diminuam às 8h todas as manhãs e diminuam ou aumentem às 17h cada tarde. O dimensionamento baseado em tempo às vezes é chamado de dimensionamento agendado.
Com base em métricas – se as cargas forem menos previsíveis, dimensione os recursos com base em métricas predefinidas, como utilização da CPU, pressão sobre a memória ou tempo médio de espera da solicitação. Por exemplo, se a utilização média da CPU atingir 70%, colocar automaticamente VMs adicionais online e, ao voltar a 30%, desprovisionar as VMs extras.
Independentemente de você optar por dimensionar com base no tempo, nas métricas ou em ambos, o dimensionamento automático conta com regras de dimensionamento ou políticas de dimensionamento configuradas por um administrador de nuvem. As plataformas de nuvem modernas oferecem suporte a regras de dimensionamento que variam de simples, como expandir de duas instâncias para quatro todos os dias às 8h e reverter para duas instâncias às 17h, até complexas – por exemplo, aumentar a contagem de VMs em um se a utilização máxima da CPU exceder 70% ou o tempo médio de espera da solicitação atingir 5 segundos. Encontrar a combinação certa de regras normalmente envolve alguma experimentação por parte do administrador da nuvem.
Todos os principais provedores de serviços de nuvem, incluindo Amazon, Microsoft e Google, dão suporte ao dimensionamento automático. O AWS Auto Scaling pode ser aplicado a instâncias do EC2, tabelas do DynamoDB e outros serviços de nuvem da AWS. O Azure fornece opções de dimensionamento automático para serviços importantes, incluindo o Serviço de Aplicativo e as Máquinas Virtuais. O Google faz o mesmo para o Google Compute Engine e o Google App Engine.
Em termos gerais, os serviços de dimensionamento automático escalonam e reduzem horizontalmente em vez de verticalmente, em parte porque o escalonamento vertical envolve a substituição de uma instância com outra e, inevitavelmente, implica em um período de tempo de inatividade enquanto novas instâncias são criadas e colocadas online.
Dimensionamento automático baseado em tempo
O dimensionamento automático baseado em tempo é apropriado quando as cargas variam de maneira previsível. Por exemplo, os sistemas de TI de muitas organizações experimentam a carga mais alta durante o horário de trabalho e podem sofrer pouca ou nenhuma carga nas primeiras horas da manhã. O site da Domino's Pizza pode experimentar cargas em todas as horas do dia, pois opera em mais de 16 mil lojas em quase 100 países/regiões. Mas é previsível que haverá cargas mais altas do que o normal durante determinadas épocas do ano.
Qualquer um dos dois cenários é um candidato para o uso do dimensionamento automático baseado em tempo. A Figura 7 mostra como o dimensionamento automático agendado é aplicado no Azure. Neste exemplo, um administrador de nuvem configura um Serviço de Aplicativo do Azure que hospeda o site da organização para executar duas instâncias por padrão, mas escala até quatro instâncias entre 6:00 e 18:00 seis dias por semana, exceto domingo. Ao selecionar em vez disso a opção "especificar datas de início/término", os administradores poderiam configurar facilmente o Serviço de Aplicativo para escalar horizontalmente para dez instâncias no Super Bowl Sunday, data anual em que é decidido o título da NFL. Eles poderiam definir várias condições de escala para também escalar horizontalmente em outras datas.
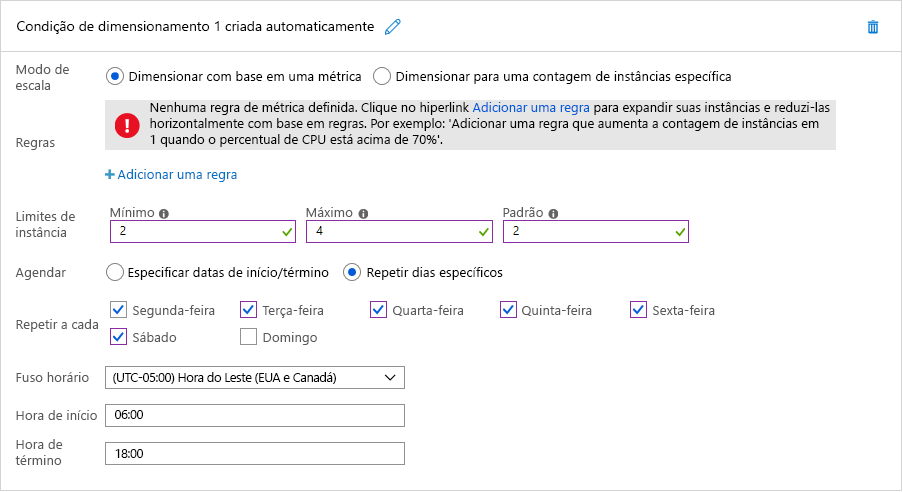
Figura 7: Dimensionamento automático agendado no Azure.
Dimensionamento automático baseado em métricas
O dimensionamento baseado em métricas como a utilização da CPU e o tempo médio de espera da solicitação é apropriado quando as cargas são menos previsíveis. O monitoramento é um elemento crucial para o dimensionamento automático eficiente de recursos com base em métricas de desempenho, pois permite que o dimensionador automático saiba quando entrar em ação. O monitoramento permite a análise dos padrões de tráfego ou da utilização de recursos para fazer uma avaliação informada sobre quando e quanto dimensionar os recursos, visando maximizar a qualidade do serviço e minimizar o custo.
Há vários aspectos dos recursos que são monitorados para disparar o dimensionamento de recursos. A métrica mais comum é a utilização de recursos. Por exemplo, um serviço de monitoramento poderá acompanhar a utilização da CPU de cada nó de recurso e dimensionar os recursos se o uso for excessivo ou muito baixo. Se, por exemplo, o uso de cada recurso for maior do que 90%, provavelmente será uma boa ideia adicionar mais recursos, já que o sistema estará sob uma carga pesada. Os provedores de serviço geralmente decidem esses pontos de disparo analisando o ponto de interrupção dos nós de recursos (o momento em que eles começam a falhar) e mapeando o comportamento deles sob vários níveis de carga. Embora, por motivos de custo, seja importante utilizar ao máximo cada recurso, é aconselhável deixar alguma margem para o sistema operacional, a fim de permitir atividades de sobrecarga. Da mesma forma, se a utilização estiver abaixo de, digamos, 30%, é possível que nem todos os nós de recursos sejam necessários e que alguns possam ser desprovisionados.
Na prática, os provedores de serviço geralmente monitoram uma combinação de várias métricas diferentes de um nó de recurso para avaliar quando dimensionar os recursos. Alguns deles incluem utilização da CPU, consumo de memória, taxa de transferência e latência. A AWS usa o CloudWatch para monitorar recursos do EC2 e fornecer métricas de dimensionamento (Figura 8). O CloudWatch rastreia as métricas de todas as instâncias do EC2 em um grupo de dimensionamento e gera um alarme quando uma métrica especificada ultrapassa um limite, por exemplo, quando a utilização da CPU excede 70%. A AWS então aumenta ou diminui a contagem de instâncias do EC2 com base nas políticas de dimensionamento configuradas por administradores.
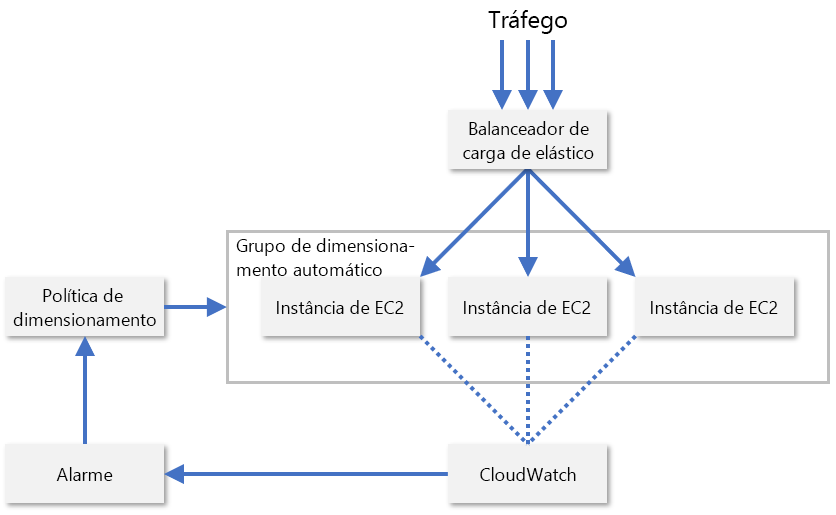
Figura 8: dimensionamento automático de instâncias de EC2 na AWS.
A AWS também dá suporte a dimensionamento preditivo, que usa o aprendizado de máquina para prever padrões de tráfego e gerenciar as contagens de instâncias correspondentemente. A meta é dimensionar de maneira inteligente os recursos de nuvem, sem exigir que um administrador de nuvem configure regras de dimensionamento automático. Os principais provedores de serviços de nuvem estão encontrando continuamente novas maneiras de melhorar suas próprias plataformas com o aprendizado de máquina. A Microsoft, por exemplo, agora usa aprendizado de máquina para melhorar a resiliência das Máquinas Virtuais do Azure, prevendo e mitigando falhas de VM de forma proativa1.
Referências
- Microsoft (2018). Aprimoramento da resiliência de máquina virtual do Azure ML preditivo e migração dinâmica. https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/.