Escalar recursos
Uma das vantagens importantes da nuvem é a capacidade de escalar recursos em um sistema sob demanda. Escalar verticalmente (provisionar recursos maiores) ou horizontalmente (provisionar recursos extra) pode ajudar a reduzir a carga em recursos específicos, diminuindo a utilização como resultado da maior capacidade ou da distribuição mais ampla da carga de trabalho.
A escala pode ajudar a aprimorar o desempenho aumentando a taxa de transferência, uma vez que passa a ser possível atender a um número maior de solicitações. Isso também pode ajudar a diminuir a latência durante cargas de pico, uma vez que um número menor de solicitações é enfileirado em um recurso durante cargas de pico. Além disso, pode ajudar a aprimorar a confiabilidade do sistema, reduzindo a utilização de recursos e afastando-a do ponto de interrupção do recurso.
É importante observar que, embora a nuvem nos permita provisionar facilmente recursos mais recentes ou melhores, o custo sempre é um fator de contraposição que precisa ser considerado. Portanto, mesmo que seja benéfico escalar vertical ou horizontalmente, também é importante reconhecer quando é necessário reduzir vertical ou horizontalmente para economizar custos. Em um aplicativo de N camadas, também é essencial identificar onde estão os gargalos e qual camada escalar, seja ela uma camada de dados ou de servidor.
A escala de recursos é facilitada pelo balanceamento de carga (que discutimos anteriormente), que ajuda a mascarar o aspecto da escala do sistema, ocultando-o atrás de um ponto de extremidade consistente.
Estratégias de escala
Escala horizontal (escalar e reduzir horizontalmente)
A escala horizontal é uma estratégia em que recursos adicionais podem ser adicionados ao sistema ou recursos desnecessários podem ser removidos dele. Esse tipo de escala é benéfico para a camada do servidor quando a carga no sistema flutua de maneira inconsistente ou é imprevisível. A natureza flutuante da carga torna essencial o provisionamento eficiente da quantidade correta de recursos para lidar com a carga em todos os momentos.
Alguns aspectos que fazem dessa uma tarefa desafiadora são o tempo de rotação de uma instância, o modelo de preço do provedor de serviços de nuvem e a possível perda de receita decorrente da degradação da QoS (Qualidade de Serviço) decorrente de não escalar horizontalmente a tempo. Como exemplo, vamos considerar o seguinte padrão de carga:
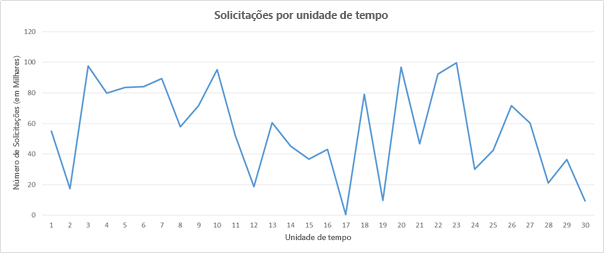
Figura 6: exemplo de padrão de carga de solicitação
Vamos imaginar que estamos usando o Amazon Web Services. E vamos imaginar também que cada unidade de tempo é equivalente a três horas de tempo real e que precisamos que um servidor atenda a 5 mil solicitações. Quando você considera a carga durante as unidades de tempo 16 a 22, há uma enorme flutuação na carga. Podemos detectar uma queda na demanda próxima à unidade de tempo 16 e começar a reduzir o número de recursos alocados. Como estamos indo de aproximadamente 50 mil solicitações para quase nenhuma no espaço de 3 horas, teoricamente podemos economizar o custo de 10 instâncias que estavam ativas na unidade de tempo 16.
Agora, vamos imaginar que cada unidade de tempo é equivalente a 20 minutos de tempo real. Nesse caso, desativar todos os recursos na unidade de tempo 16 apenas para criar recursos depois de 20 minutos aumentaria o custo em vez de economizar, pois a AWS cobra por instância de computação por hora.
Além dos dois aspectos considerados acima, o provedor de serviço também precisa avaliar as perdas que terá por fornecer uma QoS degradada durante a unidade de tempo 20, se ele tiver capacidade para apenas 90 mil solicitações em vez de 100 mil.
A escala depende das características do tráfego e da respectiva carga gerada em um serviço Web. Se o tráfego seguir um padrão previsível (por exemplo, com base no comportamento humano, como assistir a filmes por streaming em um serviço Web à noite), a escala poderá ser preditiva para manter a QoS. No entanto, em muitos casos, o tráfego não pode ser previsto e os sistemas de escala precisam ser reativos com base em critérios diferentes, conforme mostrado pelos exemplos acima.
Escala vertical (escalar e reduzir verticalmente)
Determinadas cargas dos provedores de serviços são mais previsíveis do que outras. Por exemplo, se souber com base em padrões históricos que o número de solicitações sempre será de 10 a 15 mil, você poderá pressupor que um servidor capaz de atender a 20 mil solicitações será suficiente para o provedor de serviços. Essas cargas podem aumentar no futuro, mas, desde que aumentem de maneira uniforme, o serviço poderá ser movido para uma instância maior capaz de atender a mais solicitações. Isso vale para aplicativos pequenos em que há pouco tráfego.
O desafio da escala vertical é que sempre há algum tempo usado para a mudança que pode ser considerado como tempo de inatividade. Isso ocorre porque, para mover todas as operações da instância menor para uma maior, mesmo que o tempo usado para a mudança seja de apenas alguns minutos, a QoS será degradada durante esse intervalo.
Além disso, a maioria dos provedores de nuvem oferece recursos de computação para aumentar a capacidade de computação dobrando-a em um recurso. Sendo assim, a granularidade da escala vertical não é tão refinada quanto a da escala horizontal. Ou seja, mesmo que a carga seja previsível e aumente constantemente conforme a popularidade do serviço aumentar, muitos provedores de serviço optam por escalar horizontalmente em vez de verticalmente.
Considerações sobre a escala
Monitoramento
O monitoramento é um dos elementos mais cruciais para escalar recursos efetivamente, pois permite que você tenha métricas que podem ser usadas para interpretar quais partes do sistema precisam ser escaladas e quando isso precisa ocorrer. O monitoramento permite a análise dos padrões de tráfego ou da utilização de recursos para fazer uma avaliação informada de quando e quanto escalar os recursos, visando maximizar a QoS e os lucros.
Vários aspectos dos recursos são monitorados para disparar ajustes em sua escala. A métrica mais comum é a utilização de recursos. Por exemplo, um serviço de monitoramento poderá acompanhar a utilização de CPU de cada nó de recurso e escalar os recursos se o uso for excessivo ou muito baixo. Se, por exemplo, o uso de cada recurso for maior do que 95%, provavelmente será uma boa ideia adicionar mais recursos, já que o sistema estará sob uma carga pesada. Os provedores de serviço geralmente decidem esses pontos de disparo analisando o ponto de interrupção dos nós de recursos, determinando quando eles começarão a falhar e mapeando seu comportamento sob vários níveis de carga. Embora, por motivos de custo, seja importante utilizar ao máximo cada recurso, é aconselhável deixar alguma margem para o sistema operacional, a fim de permitir atividades com sobrecarga. Da mesma forma, se a utilização estiver significativamente abaixo de, digamos, 50%, é possível que nem todos os nós de recursos sejam necessários e que alguns possam ser desprovisionados.
Na prática, os provedores de serviço geralmente monitoram uma combinação de várias métricas diferentes de um nó de recurso para avaliar quando escalar os recursos. Algumas delas incluem utilização da CPU, consumo de memória, taxa de transferência e latência. O Azure fornece o Azure Monitor como um serviço adicional capaz de monitorar qualquer recurso do Azure e fornecer essas métricas.
Ausência de estado
Um design de serviço sem estado é adequado para uma arquitetura escalonável. Um serviço sem estado significa, essencialmente, que a solicitação do cliente contém todas as informações necessárias para atender a uma solicitação pelo servidor. O servidor não armazena nenhuma informação relacionada ao cliente na instância e armazena eventuais informações relacionada à sessão na instância do servidor.
Ter um serviço sem estado ajuda a alternar entre recursos, sem necessidade de nenhuma configuração para manter o contexto (estado) da conexão do cliente para solicitações posteriores. Se o serviço for com estado, a escala de recursos exigirá uma estratégia para transferir o contexto da configuração do nó existente para a nova configuração do nó. Observe que há técnicas para implementar serviços com estado. Um exemplo é a manutenção de um cache de rede com o Memcached para que o contexto possa ser compartilhado entre servidores.
Decidir o que escalar
Dependendo da natureza do serviço, diferentes recursos precisam ser escalados dependendo do requisito. Para a camada do servidor, à medida que as cargas de trabalho aumentarem, dependendo do tipo de aplicativo, poderá aumentar a contenção de recursos para a CPU, a memória, a largura de banda de rede ou todos os itens acima. O monitoramento do tráfego nos permite identificar qual recurso está ficando restrito e escalar adequadamente esse recurso específico. Os provedores de serviço de nuvem não fornecem necessariamente a granularidade de escalabilidade necessária para escalar apenas a computação ou a memória, mas fornecem tipos diferentes de instâncias de computação que atendem especificamente a cargas com uso intenso de memória ou de computação. Sendo assim, por exemplo, para um aplicativo com cargas de trabalho com uso intensivo de memória, seria mais aconselhável escalar verticalmente os recursos para instâncias com otimização de memória. Para aplicativos que precisam atender a um grande número de solicitações que não têm necessariamente uso intenso de computação ou memória, escalar horizontalmente várias instâncias de computação padrão pode ser uma estratégia melhor.
O aumento de recursos de hardware pode nem sempre ser a melhor solução para aumentar o desempenho de um serviço. Aumentar a eficiência dos algoritmos usados pelo serviço também pode ajudar a reduzir a contenção de recursos e a aprimorar a utilização, eliminando a necessidade de escalar recursos físicos.
Escalar a camada de dados
Em aplicativos orientados a dados, em que há um grande número de leituras e gravações (ou de ambas) em um banco de dados ou sistema de armazenamento, o tempo de ida e volta de cada solicitação geralmente é limitado pelos tempos de leitura e de gravação de E/S do disco rígido. Instâncias maiores permitem um melhor desempenho das leituras e gravações de E/S, o que pode aprimorar os tempos de pesquisa no disco rígido e, por sua vez, reduzir a latência do serviço. Ter várias instâncias de dados na camada de dados pode aprimorar a confiabilidade e a disponibilidade do aplicativo fornecendo redundâncias de failover. A replicação de dados em várias instâncias tem vantagens adicionais quanto à redução da latência de rede quando o cliente é atendido por um datacenter fisicamente mais próximo. A fragmentação ou o particionamento dos dados entre vários recursos é outra estratégia de escala de dados horizontal na qual, em vez de simplesmente replicar os dados em várias instâncias, os dados são particionados em várias partições e armazenados em vários servidores de dados.
O desafio adicional quando se trata de escalar a camada de dados é a manutenção da consistência (que uma operação de leitura em todas as réplicas seja a mesma), a disponibilidade (que leituras e gravações sempre sejam bem-sucedidas) e a tolerância à partição (as propriedades garantidas no sistema serem mantidas quando as falhas impedirem a comunicação entre os nós). Muitas vezes, isso é chamado de teorema CAP, que declara que, dentro de um sistema de banco de dados distribuído, é muito difícil obter todas as três propriedades completamente e, portanto, o sistema poderá exibir, no máximo, uma combinação de duas dessas propriedades. Você aprenderá mais sobre as estratégias de escala de banco de dados e sobre o teorema CAP em módulos posteriores.