Exercício – Criar e treinar uma rede neural
Essa unidade, você usará o Keras para criar e treinar uma rede neural que analisa o texto quanto a sentimento. Para treinar uma rede neural, você precisa de dados. Em vez de baixar um conjunto de dados externo, você usará o conjunto de dados de classificação de sentimento de revisões de filmes do catálogo IMDB que está incluído com o Keras. O conjunto de dados do Catálogo IMDB contém 50.000 revisões de filme foram classificadas individualmente como positivas (1) ou negativas (0). O conjunto de dados é dividido em 25.000 revisões para treinamento e 25.000 revisões para teste. O sentimento que é expresso nessas revisões é a base para a qual a rede neural analisará o texto apresentado a ela e atribuirá a esse texto uma pontuação referente ao sentimento.
O conjunto de dados do Catálogo IMDB é um dos vários conjuntos de dados úteis incluídos com o Keras. Para obter uma lista completa de conjuntos de dados internos, confira https://keras.io/datasets/.
Digite ou cole o código a seguir na primeira célula do notebook e clique no botão Executar (ou pressione Shift + Enter) para executá-la e adicionar uma nova célula abaixo dela:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Esse código carrega o conjunto de dados do Catálogo IMDB incluído com o Keras e cria um dicionário que mapeia as palavras em todas as 50.000 revisões para inteiros que indicam a frequência relativa de ocorrência das palavras. Um inteiro exclusivo é atribuído a cada palavra. O número 1 é atribuído à palavra mais comum, o número 2 é atribuído à segunda palavra mais comum e assim por diante.
load_datatambém retorna um par de tuplas que contém as revisões de filme (neste exemplo,x_trainex_test) e os 1s e 0s classificando essas revisões como positivas e negativas (y_trainey_test).Confirme que você vê a mensagem "Usando back-end de TensorFlow" indicando que o Keras está usando o TensorFlow como seu back-end.
Carregar o conjunto de dados do Catálogo IMDB
Se você quisesse que o Keras usasse o Microsoft Cognitive Toolkit (também conhecido como CNTK) como seu back-end, você poderia fazer isso adicionando algumas linhas de código no início do notebook. Para obter um exemplo, confira CNTK e Keras no Azure Notebooks.
Portanto, o que exatamente a função
load_datacarregou? A variável chamadax_trainé uma lista de 25.000 listas, cada uma delas representando uma revisão de filme. (x_testtambém é uma lista de 25 mil listas que representam 25 mil resenhas.x_trainserá usada para treinamento, enquantox_testserá usada para teste.) Mas as listas internas, aquelas que representam as resenhas de filme, não contêm palavras; elas contêm números inteiros. Aqui está como ela é descrita na documentação do Keras:
O motivo pelo qual as listas internas contêm números em vez de texto é que você não treina uma rede neural com texto; você a treina com números. Especificamente, você a treina com tensores. Nesse caso, cada revisão é um tensor unidimensional (imagine uma matriz unidimensional) que contém inteiros identificando as palavras contidas na revisão. Para demonstrar, digite a seguinte instrução do Python em uma célula vazia e execute-a para ver os inteiros que representam a primeira revisão no conjunto de treinamento:
x_train[0]
Conjunto de inteiros que compõem a primeira revisão no conjunto de treinamento do Catálogo IMDB
O primeiro número na lista (1) não representa nenhuma palavra. Ele marca o início da revisão e é o mesmo para cada revisão no conjunto de dados. Os números 0 e 2 também são reservados e você subtrai 3 dos outros números para mapear um número inteiro em uma revisão para o inteiro correspondente no dicionário. O segundo número, 14, faz referência à palavra que corresponde ao número 11 no dicionário, o terceiro número representa a palavra à qual o número 19 é atribuído no dicionário e assim por diante.
Curioso para ver a aparência de dicionário? Execute a seguinte instrução em uma nova célula do notebook:
imdb.get_word_index()Apenas um subconjunto das entradas do dicionário é mostrado, mas no todo, o dicionário contém mais de 88.000 palavras e os inteiros que correspondem a elas. A saída que você vir provavelmente não corresponderá à saída na captura de tela, porque o dicionário é gerado novamente sempre que
load_dataé chamado.
Dicionário mapeando palavras para inteiros
Como você viu, cada revisão no conjunto de dados é codificada como uma coleção de inteiros em vez de palavras. É possível fazer a codificação reversa de uma revisão para que você possa ver o texto original que a englobou? Insira as instruções a seguir em uma nova célula e execute-os para mostrar a primeira revisão em
x_trainno formato textual:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))Na saída, ">" marca o início da revisão, enquanto "?" marca as palavras que não estão entre as 10 mil palavras mais comuns no conjunto de dados. Essas palavras "desconhecidas" são representadas por 2s na lista de inteiros que representam uma revisão. Lembra-se do parâmetro
num_wordsque você passou paraload_data? É aqui que ele entra em cena. Ela não reduz o tamanho do dicionário, mas restringe o intervalo de inteiros usado para codificar as revisões.
A primeira revisão em formato textual
As revisões estão "limpas", no sentido de que letras foram convertidas em minúsculas e caracteres de pontuação foram removidos. Mas elas não estão prontas para treinar uma rede neural para analisar o texto quanto ao sentimento. Ao treinar uma rede neural com coleção de tensores, cada tensor precisa ser do mesmo tamanho. Atualmente, as listas que representam revisões em
x_trainex_testtêm diversos tamanhos.Felizmente, o Keras inclui uma função que usa uma lista de listas como entrada e converte as listas internas para um comprimento especificado, truncando-as se necessário ou preenchendo-as com 0s. Digite o código a seguir no notebook e execute-o para forçar todas as listas que representam as resenhas de filme em
x_trainex_testpara um comprimento de 500 inteiros:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Agora que os dados de treinamento e de teste estão preparados, é hora de criar o modelo! Execute o código a seguir no notebook para criar uma rede neural que executa a análise de sentimento:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Confirme se a saída se parece com esta:
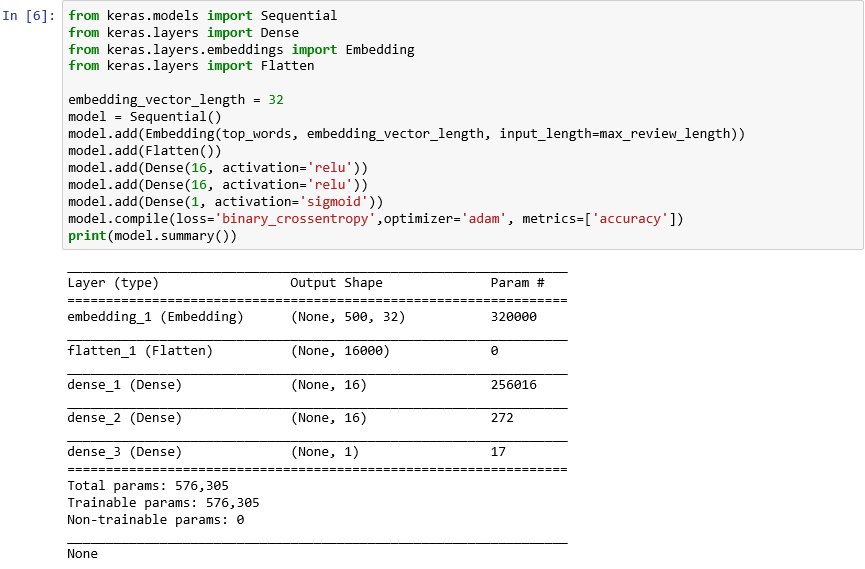
Criar uma rede neural com o Keras
Este código é a essência de como construir uma rede neural com o Keras. Ele primeiro cria uma instância de um objeto
Sequentialque representa um modelo "sequencial" – um que é composto de uma pilha de ponta a ponta de camadas na qual a saída de uma camada fornece uma entrada para a próxima.As diversas próximas instruções adicionam camadas ao modelo. A primeira é uma camada de incorporação, que é crucial para redes neurais que processam palavras. A camada de incorporação essencialmente mapeia matrizes multidimensionais que contêm índices de palavra de número inteiro em matrizes de ponto flutuante que contêm menos dimensões. Ele também permite que palavras com significados semelhantes sejam tratadas de modo parecido. Um tratamento completo de incorporações de palavras está além do escopo deste laboratório, mas você pode aprender mais lendo Por que você precisa começar a usar camadas de incorporação. Se você preferir uma explicação mais acadêmica, confira Estimativa eficiente de representações de palavras em espaço de vetor. A chamada para Flatten após a adição da camada de incorporação redimensiona a saída para a entrada da próxima camada.
As próximas três camadas adicionadas ao modelo são camadas densas, também conhecidas como camadas totalmente conectadas. Essas são as camadas tradicionais que são comuns em redes neurais. Cada camada contém n nós ou neurônios e cada neurônio recebe entrada de cada neurônio na camada anterior. Portanto, o termo "totalmente conectado". São essas camadas que permitem que uma rede neural "aprenda" com os dados de entrada adivinhando iterativamente na saída, verificando os resultados e ajustando as conexões para produzir melhores resultados. As duas primeiras camadas densas nessa rede contêm 16 neurônios. Esse número foi escolhido arbitrariamente; você poderá melhorar a precisão do modelo por experimentação com diferentes tamanhos. A camada densa final contém apenas um neurônio porque a meta final da rede é prever uma saída, ou seja, uma pontuação de sentimento de 0,0 a 1,0.
O resultado é a rede neural representada abaixo. A rede contém uma camada de entrada, uma camada de saída e duas camadas ocultas (as camadas densas que contêm 16 neurônios cada). Em comparação, algumas das redes neurais mais sofisticadas de hoje têm mais de 100 camadas. Um exemplo é a ResNet-152 da Microsoft Research, cuja precisão na identificação de objetos em fotografias às vezes excede a de um ser humano. Você pode criar a ResNet-152 com o Keras, mas você precisará de um cluster de computadores equipados com GPU para treiná-la do zero.
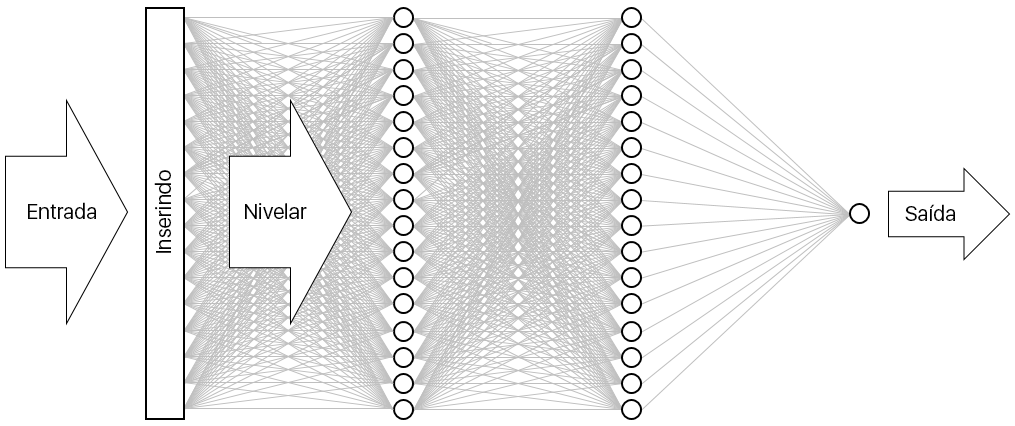
Visualizar a rede neural
A chamada à função compile "compila" o modelo, especificando parâmetros importantes, tais como qual otimizador usar e quais métricas usar para avaliar a precisão do modelo em cada etapa de treinamento. O treinamento não começa até que você chame a função
fitdo modelo, portanto, a chamadacompilenormalmente é executada rapidamente.Agora, chame a função fit para treinar a rede neural:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)O treinamento deve levar cerca de seis minutos ou um pouco mais de um minuto por época. O
epochs=5informa ao Keras para dar 5 passos para frente e para trás no modelo. A cada passagem, o modelo aprende com os dados de treinamento e mede ("valida") quão bem ele aprendeu usando os dados de teste. Em seguida, ele faz ajustes e volta para a próxima passagem ou época. Isso é refletido na saída da funçãofit, que mostra a precisão de treinamento (acc) e a precisão de validação (val_acc) de cada época.batch_size=128diz ao Keras para usar 128 exemplos de treinamento simultaneamente para treinar a rede. Tamanhos de lote maiores aceleram o tempo de treinamento (menos de passagens são necessárias em cada época para consumir todos os dados de treinamento), mas lotes menores, às vezes, aumentam a precisão. Depois de concluir este laboratório, você talvez deseje voltar e readaptar o modelo com um tamanho de lote de 32 para ver que efeito, se houver, ele tem sobre a precisão do modelo. Ele aproximadamente dobra o tempo de treinamento.
Treinamento do modelo
Esse modelo é incomum, no sentido de que ele aprende bem com apenas algumas épocas. A precisão de treinamento é ampliada rapidamente para quase 100%, enquanto a precisão de validação sobe por uma época ou duas e, em seguida, se estabiliza. Você geralmente não deseja treinar um modelo por mais tempo do que o necessário para essas precisões se estabilizarem. O risco é o sobreajuste, que resulta em um bom desempenho do modelo com os dados de teste, mas não dados reais. Uma indicação de que há sobreajuste em um modelo é uma crescente discrepância entre a precisão de treinamento e a precisão de validação. Para obter uma introdução excelente ao sobreajuste, confira Sobreajuste no aprendizado de máquina: o que é e como evitá-lo.
Para visualizar as alterações na precisão de treinamento e de validação conforme o progresso do treinamento, execute as seguintes instruções em uma nova célula do notebook:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()Os dados de precisão são provenientes do objeto
historyretornado pela funçãofitdo modelo. Com base no gráfico que vê, você recomendaria aumentar o número de épocas de treinamento, reduzi-lo ou deixá-lo como está?Outra maneira de verificar se há sobre é comparar a perda de treinamento à perda de validação conforme o treinamento prossegue. Problemas de otimização como esse buscam minimizar uma função de perda. Leia mais aqui. Para uma determinada época, uma perda de treinamento muito maior do que a perda de validação pode ser uma evidência de sobreajuste. Na etapa anterior, você usou as propriedades
acceval_accda propriedadehistorydo objetohistorypara criar gráficos da precisão de treinamento e de validação. A mesma propriedade também contém valores denominadoslosseval_lossrepresentando a perda de treinamento e a de validação, respectivamente. Se você quiser criar gráficos com estes valores para produzir um gráfico como aquele mostrado abaixo, como você modificaria o código acima para fazê-lo?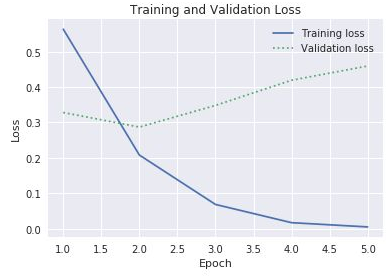
Perda de treinamento e de validação
Considerando que a lacuna entre a perda de treinamento e a de validação começa a aumentar na terceira época, o que você diria se alguém sugerisse a você aumentar o número de épocas para 10 ou 20?
Conclua chamando o método
evaluatedo modelo para determinar com que exatidão o modelo é capaz de quantificar o sentimento expresso em texto com base nos dados de teste emx_test(revisões) ey_test(0s e 1s ou "rótulos", indicando quais revisões são positivas e quais são negativas):scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))Qual é a precisão calculada do seu modelo?
Você provavelmente alcançou uma precisão no intervalo de 85% a 90%. Isso é aceitável, considerando que você criou o modelo do zero (em vez de usar uma rede neural pré-treinada) e que o tempo de treinamento foi curto, mesmo sem uma GPU. É possível alcançar precisões de 95% ou superiores com arquiteturas de rede neural alternativas, particularmente RNNs (redes neurais recorrentes) que utilizam camadas de LSTM (memória de longo prazo). O Keras torna fácil criar essas redes, mas o tempo de treinamento pode aumentar exponencialmente. O modelo que você criou tem um equilíbrio razoável entre a precisão e o tempo de treinamento. No entanto, se você quiser saber mais sobre a criação de RNNs com o Keras, confira Entendendo LSTM e sua implementação rápida no Keras para análise de sentimento.