Escala com KEDA
Dimensionamento Automático Orientado por Eventos do Kubernetes
O Dimensionamento Automático Controlado por Eventos do Kubernetes (KEDA) é um componente de uso único e leve que simplifica o dimensionamento automático do aplicativo. Você pode adicionar o KEDA a qualquer cluster do Kubernetes e usá-lo junto com componentes padrão do Kubernetes, como o Horizontal Pod Autoscaler (HPA) ou Cluster Autoscaler, para estender sua funcionalidade. Com o KEDA, você pode direcionar a aplicativos específicos que deseja que aproveitem o dimensionamento orientado por eventos e permitir que outros aplicativos usem diferentes métodos de dimensionamento. O KEDA é uma opção flexível e segura para ser executada junto com qualquer número de aplicativos ou estruturas do Kubernetes.
Principais funcionalidades e recursos
- Criar aplicativos sustentáveis e econômicos com funcionalidades de escala até zero
- Dimensionar as cargas de trabalho de aplicativo para atender à demanda usando dimensionadores do KEDA
- Dimensionamento automático de aplicativos com o
ScaledObjects - Dimensionamento automático de trabalhos com o
ScaledJobs - Use a segurança de nível de produção desvinculando o dimensionamento automático e a autenticação das cargas de trabalho
- Trazer seu dimensionador externo para usar configurações de dimensionamento automático personalizadas
Arquitetura
O KEDA fornece dois componentes principais:
- Operador KEDA: Permite que os usuários finais dimensionem cargas de trabalho dentro ou fora de zero a N instâncias, com suporte para Implantações do Kubernetes, Trabalhos, StatefulSets ou qualquer recurso personalizado que defina um sub-recurso
/scale. - Servidor de métricas: Expõe métricas externas ao HPA, como mensagens num tópico do Kafka ou eventos em Hubs de Eventos do Azure, para impulsionar ações de dimensionamento automático. Devido às limitações de upstream, o servidor de métricas do KEDA deve ser o único adaptador de métricas instalado no cluster.
O seguinte diagrama mostra como o KEDA se integra ao HPA do Kubernetes, às origens de eventos externos e ao Servidor de API do Kubernetes para fornecer funcionalidade de dimensionamento automático:
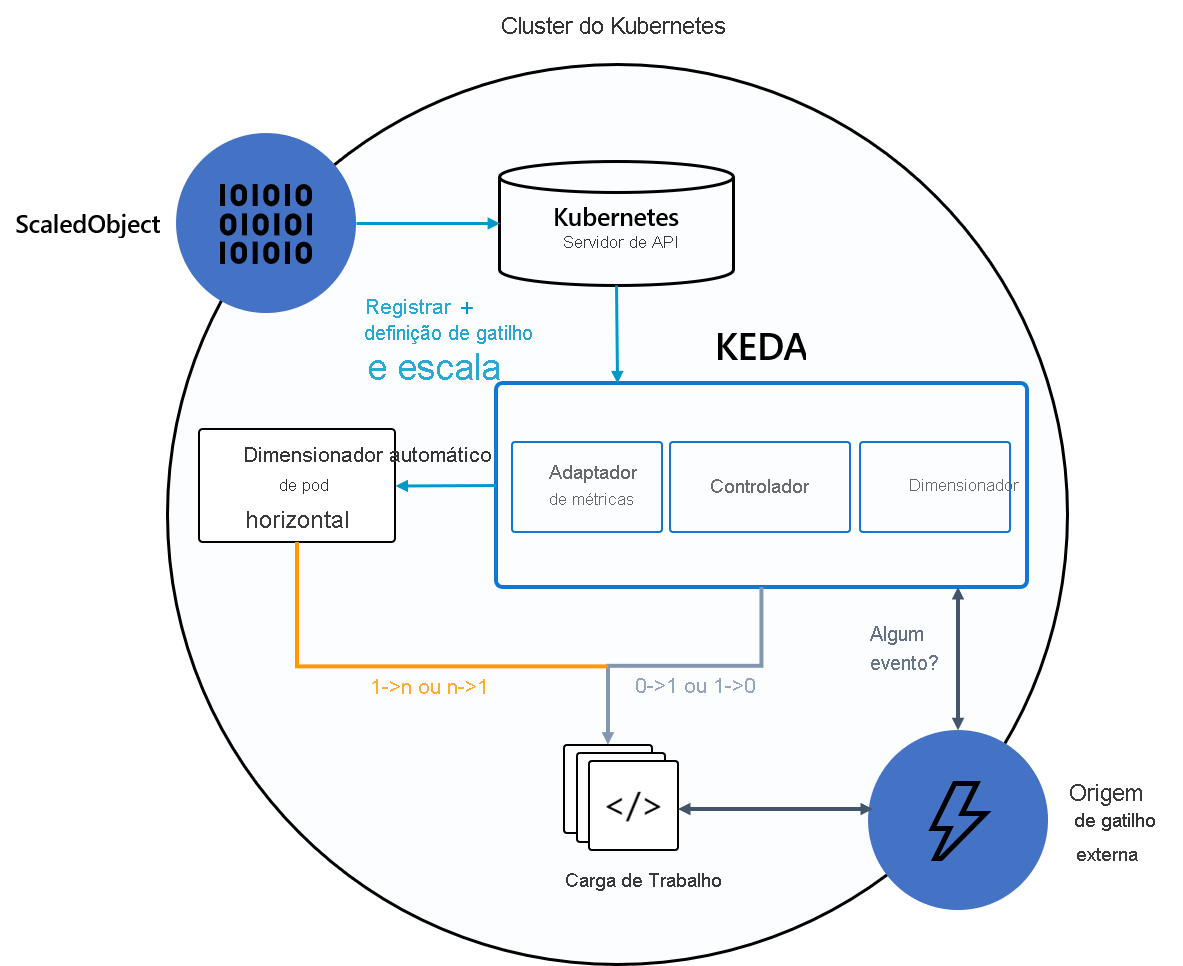
Dica
Para obter mais informações, confira a documentação oficial do KEDA.
Fontes de eventos e escalonadores
Os dimensionadores do KEDA podem detectar se uma implantação deve ser ativada ou desativada e alimentar métricas personalizadas para uma fonte de evento específica. Implantações e StatefulSets são a maneira mais comum de escalar cargas de trabalho com o KEDA. Também é possível dimensionar recursos personalizados que implementam o sub-recurso /scale. Você pode definir a implantação do Kubernetes ou StatefulSet que deseja que o KEDA dimensione com base em um gatilho de dimensionamento. O KEDA monitora esses serviços e os dimensiona automaticamente dentro ou fora com base nos eventos que ocorrem.
Nos bastidores, o KEDA monitora a origem do evento e alimenta esses dados com o Kubernetes e o HPA para impulsionar o rápido dimensionamento de recursos. Cada réplica de um recurso extrai ativamente itens da origem do evento. Com o KEDA e o Deployments/StatefulSets, você pode dimensionar com base em eventos e, ao mesmo tempo, preservar a conexão avançada e a semântica de processamento com a origem do evento (por exemplo, processamento em ordem, novas tentativas, colocar mensagem na fila de mensagens mortas ou ponto de verificação).
Especificação de objeto escalonado
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Especificação de trabalho em escala
Como alternativa ao dimensionamento do código orientado a eventos como implantações, você também pode executar e dimensionar seu código como um Trabalho do Kubernetes. O principal motivo para considerar essa opção é se você precisar processar execuções prolongadas. Em vez de processar vários eventos em uma implantação, cada evento detectado agenda seu próprio Trabalho do Kubernetes. Essa abordagem permite processar cada evento isoladamente e dimensionar o número de execuções simultâneas com base no número de eventos na fila.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}