DBCC SHOW_STATISTICS (Transact-SQL)
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() PDW (Analytics Platform System)
PDW (Analytics Platform System) ![]() Ponto de extremidade de análise do SQL
Ponto de extremidade de análise do SQL ![]() Warehouse no Microsoft Fabric
Warehouse no Microsoft Fabric
Exibe as estatísticas de otimização de consulta atuais de uma tabela ou exibição indexada. O otimizador de consulta usa estatísticas para estimar a cardinalidade ou o número de linhas no resultado da consulta, o que permite que o Otimizador de Consulta crie um plano de consulta de alta qualidade. Por exemplo, o Otimizador de Consulta pode usar estimativas de cardinalidade para escolher o operador de busca do índice, em vez do operador de verificação do índice no plano de consulta, melhorando o desempenho da consulta ao evitar uma verificação de índice que consome muitos recursos.
O Otimizador de Consulta armazena estatísticas para uma tabela ou exibição indexada em um objeto de estatísticas. Para uma tabela, o objeto de estatísticas é criado em um índice ou uma lista de colunas de tabela. O objeto de estatísticas inclui um cabeçalho com metadados sobre as estatísticas, um histograma com a distribuição de valores na primeira coluna de chave do objeto de estatísticas e um vetor de densidade para medir a correlação entre colunas. O Mecanismo de Banco de Dados pode calcular estimativas de cardinalidade com qualquer dos dados no objeto de estatísticas. Para obter mais informações, confira Estatísticas e Estimativa de Cardinalidade (SQL Server).
DBCC SHOW_STATISTICS exibe o cabeçalho, o histograma e o vetor de densidade com base nos dados armazenados no objeto de estatísticas. A sintaxe lhe permite especificar uma tabela ou exibição indexada junto com um nome de índice de destino, nome de estatísticas ou nome da coluna.
Atualizações importantes em versões anteriores do SQL Server:
Desde o SQL Server 2012 (11.x) Service Pack 1, a exibição de gerenciamento dinâmico sys.dm_db_stats_properties está disponível para a recuperação programática das informações de cabeçalho contidas no objeto de estatísticas com relação a estatísticas não incrementais.
Desde o SQL Server 2014 (12.x) Service Pack 2 e o SQL Server 2012 (11.x) Service Pack 1, a exibição de gerenciamento dinâmico sys.dm_db_incremental_stats_properties está disponível para a recuperação programática das informações de cabeçalho contidas no objeto de estatísticas com relação a estatísticas incrementais.
Desde o SQL Server 2016 (13.x) Service Pack 1 CU 2, a exibição de gerenciamento dinâmico sys.dm_db_stats_histogram está disponível para a recuperação programática das informações de histograma contidas no objeto de estatísticas.
-
Não há suporte a essa sintaxe para o pool de SQL sem servidor no Azure Synapse Analytics.
Para obter mais informações sobre estatísticas no Microsoft Fabric, confira Estatísticas.
![]() Convenções de sintaxe de Transact-SQL
Convenções de sintaxe de Transact-SQL
Sintaxe
Sintaxe do SQL Server e do Banco de Dados SQL do Azure:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Sintaxe para Azure Synapse Analytics, PDW (Analytics Platform System) e Microsoft Fabric:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
Argumentos
table_or_indexed_view_name
O nome da tabela ou exibição indexada das quais exibir informações de estatísticas.
table_name
Nome da tabela que contém as estatísticas a serem exibidas. A tabela não pode ser uma tabela externa.
destino
O nome do índice, das estatísticas ou da coluna para a qual exibir informações de estatísticas. target é colocado entre colchetes, aspas simples, aspas ou sem aspas.
- Se target for um nome de uma estatística ou um índice existente em uma tabela ou exibição indexada, as informações de estatísticas sobre esse destino serão retornadas.
- Se target for o nome de uma coluna existente e houver um objeto de estatística criado automaticamente nessa coluna, as informações sobre essa estatística criada de forma automática serão retornadas.
Se uma estatística criada automaticamente não existir para um destino de coluna, a mensagem de erro 2767 será retornada.
No Azure Synapse PDW (Analytics and Analytics Platform System), o destino não pode ser um nome de coluna.
No Warehouse no Microsoft Fabric, o destino pode ser o nome de uma coluna única de estatísticas de histograma ou uma coluna. Se o nome de coluna for usado para destino, esse comando retornará informações de distribuição apenas sobre a estatística de histograma gerada automaticamente. Para exibir as informações sobre uma estatística de histograma criada manualmente, especifique o nome das estatísticas como destino.
NO_INFOMSGS
Suprime todas as mensagens informativas com níveis de severidade de 0 a 10.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
A especificação de um ou mais desses parâmetros limita os conjuntos de resultados retornados pela instrução para a opção ou as opções especificadas. Se nenhuma opção for especificada, todas as informações de estatísticas serão retornadas.
STATS_STREAM é identificado apenas para fins informativos. Não há suporte. A compatibilidade futura não está garantida.
Conjunto de resultados
A tabela a seguir descreve as colunas retornadas no conjunto de resultados quando STAT_HEADER está especificado.
| Nome da coluna | Descrição |
|---|---|
| Nome | O nome do objeto de estatísticas. |
| Atualizado | Data e hora da última atualização de estatísticas. A função STATS_DATE é uma maneira alternativa de recuperar essas informações. Para obter mais informações, consulte a seção de Comentários nesta página. |
| Linhas | O número total de linhas na tabela ou exibição indexada quando as estatísticas foram atualizadas pela última vez. Se as estatísticas forem filtradas ou corresponderem a um índice filtrado, o número de linhas talvez seja menor do que o número de linhas na tabela. Para obter mais informações, consulte Estatísticas. |
| Linhas Amostradas | O número total de linhas amostradas para cálculos de estatísticas. Se Linhas Amostradas < Linhas, o histograma e os resultados de densidade exibidos serão estimativas com base nas linhas amostradas. |
| Etapas | O número de etapas no histograma. Cada etapa abrange uma gama de valores de colunas seguidos por um valor de coluna associada superior. As etapas do histograma são definidas na primeira coluna de chave nas estatísticas. O número máximo de etapas é 200. |
| Densidade | Calculado como 1 / valores distintos para todos os valores na primeira coluna de chave do objeto de estatísticas, excluindo os valores de limite de histograma. Esse valor de Densidade não é usado pelo otimizador de consulta e é exibido para fins de compatibilidade com versões anteriores ao SQL Server 2008 (10.0.x). |
| Comprimento Médio de Chave | O número médio de bytes por valor para todas as colunas de chave do objeto de estatísticas. |
| Índice de Cadeia de Caracteres | Sim indica que o objeto de estatísticas contém estatísticas do resumo da cadeia de caracteres para melhorar a estimativa de cardinalidade para predicados de consulta que usam o operador LIKE; por exemplo, WHERE ProductName LIKE '%Bike'. As estatísticas de resumo da cadeia de caracteres são armazenadas separadamente do histograma e são criadas na primeira coluna de chave do objeto de estatísticas quando ela é do tipo char, varchar, nchar, nvarchar, varchar(max), nvarchar(max), text ou ntext. |
| Expressão de filtro | Predicado do subconjunto de linhas de tabela incluído no objeto de estatísticas. NULL = estatísticas não filtradas. Para obter mais informações sobre predicados filtrados, consulte Criar índices filtrados. Para obter mais informações sobre estatísticas filtradas, consulte Estatísticas. |
| Linhas não filtradas | O número total de linhas na tabela antes da aplicação da expressão de filtro. Se a expressão de filtro for NULL, Unfiltered Rows será igual a Rows. |
| Percentual de amostra persistente | Percentual de amostra persistente usado para as atualizações de estatísticas que não especifica explicitamente um percentual de amostragem. Se o valor for zero, nenhum percentual de amostra persistente será definido para essa estatística. Aplica-se a: SQL Server 2016 (13.x) Service Pack 1 CU 4 |
A tabela a seguir descreve as colunas retornadas no conjunto de resultados quando DENSITY_VECTOR é especificado.
| Nome da coluna | Descrição |
|---|---|
| Toda Densidade | A densidade é 1 / valores distintos. Os resultados exibem a densidade de cada prefixo de colunas no objeto de estatísticas, uma linha por densidade. Um valor distinto é uma lista distinta dos valores de coluna por linha e por prefixo de colunas. Por exemplo, se o objeto de estatísticas contiver colunas de chave (A, B, C), os resultados reportarão a densidade de listas distintas de valores em cada um desses prefixos de colunas: (A), (A,B) e (A, B, C). Usando o prefixo (A, B, C), cada uma dessas listas é uma lista de valores distintos: (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). Usando o prefixo (A, B), os mesmos valores de coluna têm estas listas de valores distintos: (3, 5), (4, 4) e (4, 5) |
| Comprimento Médio | O comprimento médio, em bytes, para armazenar uma lista dos valores das colunas para o prefixo da coluna. Por exemplo, se os valores na lista (3, 5, 6) exigirem cada um 4 bytes, o comprimento será de 12 bytes. |
| Colunas | Os nomes das colunas no prefixo para o qual as opções Toda a densidade e Comprimento médio são exibidos. |
A tabela a seguir descreve as colunas retornadas no conjunto de resultados quando a opção HISTOGRAM está especificada.
| Nome da coluna | Descrição |
|---|---|
| RANGE_HI_KEY | Valor da coluna associada superior de uma etapa do histograma. O valor da coluna também será denominado um valor de chave. |
| RANGE_ROWS | Número estimado de linhas cujo valor de coluna fica dentro de uma etapa do histograma, excluindo-se o limite superior. |
| EQ_ROWS | Número estimado de linhas cujo valor de coluna é igual ao limite superior da etapa do histograma. |
| DISTINCT_RANGE_ROWS | Número estimado de linhas com um valor de coluna distinto dentro de uma etapa do histograma, excluindo-se o limite superior. |
| AVG_RANGE_ROWS | Número médio de linhas com valores de coluna duplicados dentro de uma etapa do histograma, excluindo o limite superior. Quando DISTINCT_RANGE_ROWS é maior que 0, AVG_RANGE_ROWS é calculado pela divisão RANGE_ROWS pelo DISTINCT_RANGE_ROWS. Quando DISTINCT_RANGE_ROWS é 0, AVG_RANGE_ROWS retorna 1 para a etapa de histograma. |
Comentários
A data de atualização de estatísticas é armazenada no objeto de blob de estatísticas, junto com o histograma e o vetor de densidade, não nos metadados. Quando nenhum dado é lido para gerar dados de estatísticas, o blob de estatísticas não é criado, a data não fica disponível e a coluna updated é NULL. Esse é o caso para estatísticas filtradas para as quais o predicado não retorna nenhuma linha ou para novas tabelas vazias.
Histograma
Um histograma mede a frequência de ocorrência de cada valor distinto em um conjunto de dados. O otimizador de consulta calcula um histograma com base nos valores de coluna na primeira coluna de chave do objeto de estatísticas, selecionando os valores de coluna por amostragem estatística das linhas ou pela execução de uma verificação completa de todas as linhas na tabela ou na exibição. Se o histograma for criado com base em um conjunto amostrado de linhas, os totais armazenados para o número de linhas e o número de valores distintos são estimativas e não precisam ser números inteiros.
Para criar o histograma, o otimizador de consulta classifica os valores de colunas, calcula o número de valores que correspondem a cada valor de coluna distinta e agrega os valores de colunas em um máximo de 200 etapas de histograma contíguas. Cada etapa inclui uma gama de valores de colunas seguidos por um valor de coluna associada superior. O intervalo inclui todos os possíveis valores de coluna entre valores de limite, excluindo-se os próprios valores de limite em si. O mais baixo dos valores de coluna classificados é o valor do limite superior da primeira etapa do histograma.
O diagrama a seguir mostra um histograma com seis etapas: A área à esquerda do primeiro valor do limite superior corresponde à primeira etapa.

Para cada etapa do histograma:
- A linha em negrito representa o valor do limite superior (RANGE_HI_KEY) e o número de vezes que ele ocorre (EQ_ROWS)
- A área sólida à esquerda de RANGE_HI_KEY representa o intervalo de valores de coluna e o número médio de vezes em que cada valor de coluna ocorre (AVG_RANGE_ROWS). AVG_RANGE_ROWS para a primeira etapa do histograma é sempre 0.
- As linhas pontilhadas representam os valores amostrados usados para estimar o número total de valores distintos no intervalo (DISTINCT_RANGE_ROWS) e o número total de valores no intervalo (RANGE_ROWS). O otimizador de consulta usa RANGE_ROWS e DISTINCT_RANGE_ROWS para calcular AVG_RANGE_ROWS e não armazena os valores amostrados.
O otimizador de consulta define as etapas do histograma de acordo com o significado estatístico delas. Ele usa um algoritmo de diferença máxima para minimizar o número de etapas no histograma, enquanto maximiza a diferença entre os valores de limite. O número máximo de etapas é 200. O número de etapas do histograma pode ser menor do que o número de valores distintos, até mesmo para colunas com menos de 200 pontos de limite. Por exemplo, uma coluna com 100 valores distintos pode ter um histograma com menos de 100 pontos de limite.
Vetor de densidade
O otimizador de consulta usa densidades para aprimorar as estimativas de cardinalidade de consultas que retornam várias colunas da mesma tabela ou exibição indexada. O vetor de densidade contém uma densidade para cada prefixo de colunas no objeto de estatísticas. Por exemplo, se um objeto de estatísticas tiver as colunas de chave CustomerId, ItemId e Price, a densidade será calculada em cada um dos prefixos de coluna a seguir.
| Prefixo de coluna | Densidade calculada em |
|---|---|
(CustomerId) |
Linhas com valores correspondentes para CustomerId |
(CustomerId, ItemId) |
Linhas com valores correspondentes para CustomerId e ItemId |
(CustomerId, ItemId, Price) |
Linhas com valores correspondentes para CustomerId, ItemId e Price |
Limitações
DBCC SHOW_STATISTICS não fornece estatísticas para índices espaciais nem índices columnstore com otimização de memória.
Permissões do SQL Server e do Banco de Dados SQL
Para exibir o objeto de estatísticas, o usuário deve ter a permissão SELECT na tabela.
Para que as permissões SELECT sejam suficientes para executar o comando, é necessário atender aos seguintes requisitos:
- Os usuários devem ter permissões em todas as colunas do objeto de estatísticas
- Os usuários devem ter permissão em todas as colunas em uma condição de filtro (se houver)
- A tabela não pode ter uma política de segurança em nível de linha.
- Se qualquer uma das colunas em um objeto de estatísticas for mascarada com regras de Máscara Dinâmica de Dados, além da permissão
SELECT, o usuário deverá ter a permissãoUNMASKou ser membro da função db_ddladmin.
Em versões anteriores ao SQL Server 2012 (11.x) Service Pack 1, o usuário deve ser proprietário da tabela ou um membro da função de servidor fixa sysadmin, da função de banco de dados fixa db_owner ou da função de banco de dados fixa db_ddladmin.
Observação
Para alterar o comportamento para o anterior ao SQL Server 2012 (11.x) Service Pack 1, use o sinalizador de rastreamento 9485.
Permissões para Azure Synapse Analytics e PDW (Analytics Platform System)
DBCC SHOW_STATISTICS requer a permissão SELECT na tabela ou a associação à função de servidor fixa sysadmin, à função de banco de dados fixa db_owner ou à função de banco de dados fixa db_ddladmin.
Limitações e restrições de Azure Synapse Analytics e PDW (Analytics Platform System)
DBCC SHOW_STATISTICS mostra as estatísticas armazenadas no banco de dados Shell no nível do nó de controle. Ele não mostra as estatísticas criadas automaticamente pelo SQL Server nos nós de Computação.
DBCC SHOW_STATISTICS não tem suporte em tabelas externas.
No Microsoft Fabric, DBCC SHOW_STATISTICS mostra apenas resultados para estatísticas de histograma, não estatísticas ACE-*.
Exemplos: SQL Server e Banco de Dados SQL do Azure
a. Retornar todas as informações de estatísticas
O exemplo a seguir exibe todas as informações de estatísticas para o índice AK_Address_rowguid da tabela Person.Address no banco de dados AdventureWorks2022.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. Especificar a opção HISTROGRAM
Isso limita as informações de estatísticas exibidas para Customer_LastName aos dados de HISTOGRAM.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
Exemplos: Azure Synapse Analytics e PDW (Analytics Platform System)
C. Exibir o conteúdo de um objeto de estatísticas
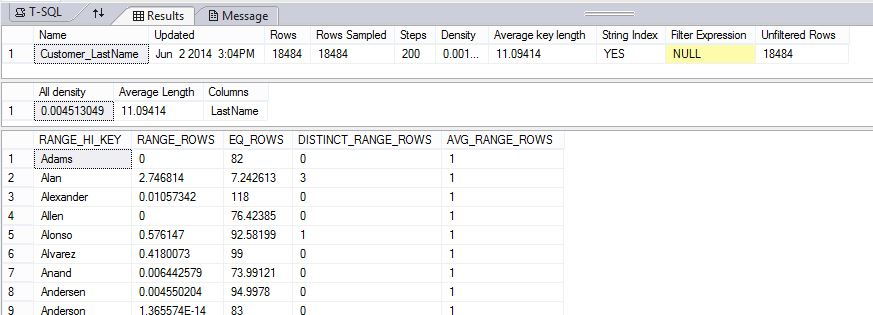
O exemplo a seguir cria um objeto de estatísticas e exibe o conteúdo das estatísticas Customer_LastName na tabela DimCustomer no banco de dados de exemplo AdventureWorksPDW2022.
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
Os resultados mostram o cabeçalho, o vetor de densidade e parte do histograma.
Confira também
- Estatísticas
- Estatísticas no Microsoft Fabric
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)