Heaps (Tabelas sem índices clusterizados)
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Banco de Dados SQL no Microsoft Fabric
Banco de Dados SQL no Microsoft Fabric
Heap é uma tabela sem índice clusterizado. Podem ser criados um ou mais índices não clusterizados em tabelas armazenadas como um heap. Dados são armazenados no heap sem especificar uma ordem. Normalmente, os dados são inicialmente armazenados na ordem em que as linhas são inseridas. No entanto, o Mecanismo de Banco de Dados pode mover dados no heap para armazenar as linhas com eficiência. Nos resultados da consulta, a ordem dos dados não pode ser prevista. Para garantir a ordem de linhas retornadas de um heap, use a cláusula ORDER BY. Para especificar uma ordem lógica permanente para armazenar as linhas, crie um índice clusterizado na tabela, de modo que a tabela não seja um heap.
Observação
Às vezes, há boas razões para deixar uma tabela como heap em vez de criar um índice clusterizado, mas usar heaps efetivamente é uma habilidade avançada. A maioria das tabelas deve ter um índice clusterizado cuidadosamente escolhido, a menos que haja uma boa razão boa para deixar a tabela como heap.
Quando usar um heap
Um heap é ideal para tabelas que são frequentemente truncadas e recarregadas. O mecanismo de banco de dados otimiza o espaço em um heap preenchendo o espaço disponível mais cedo.
Considere o seguinte:
- Localizar espaço livre em um heap pode ser caro, especialmente se houver muitas exclusões ou atualizações.
- Os índices clusterizados oferecem desempenho estável para tabelas que não são truncadas com frequência.
Para tabelas que são truncadas ou recriadas regularmente, como tabelas temporárias ou de preparo, o uso de um heap geralmente é mais eficiente.
A escolha entre usar um heap e um índice clusterizado pode afetar significativamente o desempenho e a eficiência do banco de dados.
Quando uma tabela é armazenada como heap, linhas individuais são identificadas por referência a um RID (identificador de linha) de 8 bytes, que é composto pelo número do arquivo, pelo número da página de dados e pelo local na página (FileID:PageID:SlotID). A ID da linha é uma estrutura pequena e eficiente.
Os heaps podem ser usados como tabelas de preparo para operações de inserção grandes e não ordenadas. Como os dados são inseridos sem impor uma ordem estrita, a operação de inserção é geralmente mais rápida do que a inserção equivalente em um índice clusterizado. Se os dados do heap forem lidos e processados em um destino final, talvez seja útil criar um índice não clusterizado estreito que aborde o predicado de pesquisa usado pela consulta.
Observação
Os dados são recuperados de um heap na ordem das páginas de dados, mas não necessariamente a ordem na qual os dados foram inseridos.
Às vezes, os profissionais de dados também usam heaps quando os dados são sempre acessados por índices não clusterizados e o RID é menor que uma chave de índice clusterizado.
Se uma tabela for um heap e não tiver um índice clusterizado, a tabela inteira deverá ser lida (uma verificação de tabela) para localizar as linhas. O SQL Server não pode buscar um RID diretamente no heap. Esse comportamento pode ser aceitável quando a tabela é pequena.
Quando não usar um heap
Não use um heap quando os dados são retornados frequentemente em uma ordem classificada. Um índice clusterizado na coluna de classificação pode evitar a operação de classificação.
Não use um heap quando os dados forem agrupados com frequência. Os dados devem ser classificados antes de serem agrupados, e um índice clusterizado na coluna de classificação pode evitar a operação de classificação.
Não use um heap quando intervalos de dados são consultados frequentemente na tabela. Um índice clusterizado na coluna de intervalo evita a classificação do heap inteiro.
Não use um heap quando não houver índice não clusterizado e a tabela for grande. A única aplicação para esse design é retornar todo o conteúdo da tabela sem nenhuma ordem especificada. Em um heap, o Mecanismo de Banco de Dados lê todas as linhas para localizar qualquer linha.
Não use um heap se os dados forem atualizados com frequência. Se você atualizar um registro e a atualização usar mais espaço nas páginas de dados do que está sendo usando no momento, o registro precisará ser movido para uma página de dados que tenha espaço livre suficiente. Isso cria um registro encaminhado apontando para o novo local dos dados, e o ponteiro de encaminhamento precisa ser escrito na página que mantinha esses dados anteriormente, para indicar o novo local físico. Isso introduz fragmentação no heap. Quando o Mecanismo de Banco de Dados verifica um heap, ele segue esses ponteiros. Essa ação limita o desempenho de leitura antecipada e pode incorrer em E/S adicional, o que reduz o desempenho da verificação.
Gerenciar heaps
Para criar um heap, crie uma tabela sem um índice clusterizado. Se uma tabela já tiver um índice clusterizado, descarte o índice clusterizado para retornar a tabela a um heap.
Para remover um heap, crie um índice clusterizado no heap.
Para recompilar um heap para recuperar o espaço desperdiçado:
- Crie um índice clusterizado no heap e descarte esse índice clusterizado.
- Use o comando
ALTER TABLE ... REBUILDpara recompilar o heap.
Aviso
Criar ou descartar índices clusterizados requer a regravação da tabela inteira. Se a tabela tiver índices não clusterizados, todos os índices não clusterizados deverão ser recriados sempre que o índice clusterizado for alterado. Portanto, mudar de um heap para uma estrutura de índice clusterizado ou vice-versa pode demorar muito e exigir espaço em disco para reorganizar os dados em tempdb.
Identificar heaps
A consulta a seguir retorna umaa lista de heaps do banco de dados atual. A lista inclui:
- Nomes da tabela
- Nomes do esquema
- Número de linhas
- Tamanho da tabela em KB
- Tamanho do índice em KB
- Espaço não utilizado
- Uma coluna para identificar um heap
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Estruturas de heap
Heap é uma tabela sem índice clusterizado. Heaps têm uma linha em sys.partitions, com index_id = 0 para cada particionamento usado pelo heap. Por padrão, um heap tem um único particionamento. Quando um heap tem particionamentos múltiplos, cada particionamento tem uma estrutura de heap que contém os dados para aquele específico. Por exemplo, se um heap tiver quatro particionamentos, haverá quatro estruturas de heap; uma em cada particionamento.
Dependendo dos tipos de dados no heap, cada estrutura de heap terá uma ou mais unidades de alocação para armazenar e gerenciar os dados de um particionamento específico. No mínimo, cada heap terá uma IN_ROW_DATA unidade de alocação por particionamento. O heap também terá uma LOB_DATA unidade de alocação por particionamento, caso tenha colunas LOB (objetos grandes). Também terá uma ROW_OVERFLOW_DATA unidade de alocação por particionamento, se tiver colunas de comprimento variável excedendo o limite de tamanho de linha de 8.060 bytes.
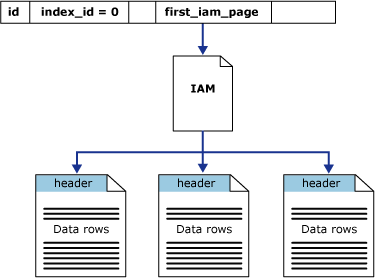
A coluna first_iam_page no modo de exibição do sistema sys.system_internals_allocation_units aponta para a primeira página IAM na cadeia de páginas IAM, que gerencia o espaço alocado no heap em uma partição específica. SQL Server usa as páginas IAM para percorrer o heap. As páginas de dados e as linhas dentro delas não estão em nenhuma ordem específica e não estão vinculadas. A única conexão lógica entre as páginas de dados são as informações registradas nas páginas IAM.
Importante
O sys.system_internals_allocation_units exibição do sistema é reservado somente para uso interno do SQL Server. A compatibilidade futura não está garantida.
Os exames de tabela ou as leituras consecutivas de um heap podem ser executados examinando as páginas IAM para localizar as extensões que estão mantendo páginas do heap. Como o IAM representa extensões na mesma ordem que elas existem nos arquivos de dados, isso significa que esses exames de heap consecutivo progridem sequencialmente em cada arquivo. O uso das páginas IAM para definir a sequência de exame também significa que as linhas do heap não são retornadas normalmente na ordem em que foram inseridas.
A ilustração a seguir mostra como o Mecanismo de Banco de Dados do SQL Server usa páginas IAM para recuperar linhas de dados em um único heap de particionamento.
Conteúdo relacionado
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
Índices clusterizados e não clusterizados descritos