Arquivos e grupos de arquivos do banco de dados
Aplica-se a: ![]() SQL Server
SQL Server ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
No mínimo, todo banco de dados SQL Server possui dois arquivos de sistema operacional: um arquivo de dados e um arquivo de log. Os arquivos de dados contêm dados e objetos como tabelas, índices, procedimentos armazenados e exibições. Os arquivos de log contêm as informações necessárias para recuperar todas as transações no banco de dados. Os arquivos de dados podem ser agrupados em grupos de arquivos para propósitos de alocação e administração.
Arquivos de banco de dados
Os bancos de dados SQL Server têm três tipos de arquivos, conforme mostrado na tabela a seguir.
| Arquivo | Descrição |
|---|---|
| Primária | Contém informações de inicialização do banco de dados e aponta para os outros arquivos no banco de dados. Todo banco de dados possui um arquivo de dados primário. A extensão do nome de arquivo indicada para arquivos de dados primários é .mdf. |
| Secundário | Arquivos de dados opcionais definidos pelo usuário. Os dados podem ser distribuídos em vários discos, colocando cada arquivo em uma unidade de disco diferente. A extensão do nome de arquivo indicada para arquivos de dados secundários é .ndf. |
| Log de Transações | O log contém informações usadas para recuperar o banco de dados. Deve haver, no mínimo, um arquivo de log para cada banco de dados. A extensão do nome de arquivo indicada para logs de transações é .ldf. |
Por exemplo, um simples banco de dados nomeado como Sales tem um arquivo primário que contém todos os dados e objetos e um arquivo de log que contém as informações do log de transações. Um banco de dados mais complexo nomeado como Orders pode ser criado incluindo um arquivo primário e cinco arquivos secundários. Os dados e objetos no banco de dados distribuem-se pelos seis arquivos, e os quatro arquivos de log contêm as informações do log de transação.
Por padrão, os dados e logs de transação são colocados na mesma unidade e caminho para lidar com sistemas de disco único. Essa opção não é o ideal para ambientes de produção. Recomendamos que você coloque os dados e arquivos de log em discos separados.
Nomes de arquivos lógico e físico
Os arquivos do SQL Server têm dois tipos de nome de arquivo:
logical_file_name:Ological_file_nameé o nome usado para se referir ao arquivo físico em todas as instruções Transact-SQL. O nome de arquivo lógico deve estar de acordo com as regras de identificadores do SQL Server e deve ser exclusivo entre os nomes de arquivos lógicos no banco de dados.os_file_name:Oos_file_nameé o nome do arquivo físico que inclui o caminho de diretório. Ele deve seguir as regras dos nomes de arquivo de sistema operacional.
Para obter mais informações sobre os argumentos NAME e FILENAME, consulte Opções de arquivo e grupo de arquivos de ALTER DATABASE (Transact-SQL).
Dica
Os arquivos de log e os dados do SQL Server podem ser colocados em sistemas de arquivos FAT ou NTFS. Em sistemas Windows, a Microsoft recomenda o uso do sistema de arquivos NTFS devido aos aspectos de segurança do NTFS.
Aviso
Os grupos de arquivos de dados de leitura/gravação e os arquivos de log não são compatíveis com um sistema de arquivos compactados NTFS. Só podem ser colocados bancos de dados somente leitura e grupos de arquivos secundários somente leitura em um sistema de arquivos compactados NTFS. Para economia de espaço, é altamente recomendável usar a compactação de dados em vez da compactação do sistema de arquivos.
Quando são executadas várias instâncias do SQL Server em um único computador, cada uma recebe um diretório padrão diferente para manter os arquivos dos bancos de dados criados na instância. Para obter mais informações, consulte Locais de Arquivos para Instâncias Padrão e Nomeadas do SQL Server.
Páginas de arquivo de dados
As páginas de um arquivo de dados do SQL Server são numeradas em sequência, iniciando com zero (0) na primeira página do arquivo. Cada arquivo em um banco de dados tem um número de ID de arquivo exclusivo. Para identificar de forma exclusiva uma página em um banco de dados, são necessários ID do arquivo e número de página. O exemplo a seguir mostra os números de página em um banco de dados que tem um arquivo de dados primário de 4 MB e um arquivo de dados secundário de 1 MB.
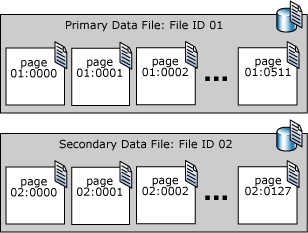
Uma página de cabeçalho de arquivo é a primeira página que contém informações sobre os atributos do arquivo. Várias outras páginas do início do arquivo também têm informações de sistema, como mapas de alocação. Uma das páginas de sistema armazenada no arquivo de dados primário e no primeiro arquivo de log é uma página de inicialização de banco de dados que contém informações sobre os atributos do banco de dados.
Tamanho do arquivo
Os arquivos do SQL Server podem aumentar automaticamente do tamanho original especificado. Ao definir um arquivo, você poderá definir um incremento de crescimento específico. Sempre que o arquivo estiver cheio, seu tamanho aumentará com base no incremento de crescimento. Se houver vários arquivos em um grupo de arquivos, eles não crescerão automaticamente até que todos os arquivos estejam cheios.
Para obter mais informações sobre páginas e tipos de página, consulte o Guia de arquitetura de páginas e extensões.
Cada arquivo também pode ter um tamanho máximo especificado. Se um tamanho máximo não for especificado, o arquivo continuará crescendo até usar todo o espaço disponível no disco. Esse recurso é muito útil quando o SQL Server é usado como um banco de dados inserido em um aplicativo no qual o usuário não tem acesso conveniente a um administrador de sistema. O usuário pode deixar o crescimento automático de arquivos conforme exigido para reduzir a carga administrativa de monitoramento do espaço livre do banco de dados e de alocação manual de espaço adicional.
Para obter mais informações sobre o gerenciamento de arquivos de log de transações, consulte Gerenciar o tamanho do arquivo de log de transações.
Arquivos de instantâneo do banco de dados
O formulário do arquivo usado por um instantâneo do banco de dados para armazenar seus dados de cópia-na-gravação depende de o instantâneo ser criado por um usuário ou usado internamente:
- Um instantâneo do banco de dados criado por um usuário armazena seus dados em um ou mais arquivos esparsos. A tecnologia de arquivo esparso é um recurso do sistema de arquivos NTFS. A princípio, um arquivo esparso não contém dados de usuário e o espaço em disco para dados de usuário não foi alocado ao arquivo esparso. Para obter informações gerais sobre o uso de arquivos esparsos em instantâneos do banco de dados e como os instantâneos do banco de dados aumentam, consulte Exibir o Tamanho do Arquivo Esparso do Instantâneo de Banco de Dados.
- Os instantâneos de banco de dados são usados internamente por determinados comandos DBCC. Esses comandos incluem
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOCeDBCC CHECKFILEGROUP. Um instantâneo do banco de dados interno usa fluxos de dados alternativos esparsos dos arquivos de banco de dados originais. Assim como os arquivos esparsos, os fluxos de dados alternativos são um recurso do sistema de arquivos NTFS. O uso de fluxos de dados alternativos esparsos permite que as alocações de dados múltiplas sejam associadas a um único arquivo ou pasta sem afetar o tamanho do arquivo ou as estatísticas de volume.
Grupos de arquivos
- O grupo de arquivos primário contém o arquivo de dados primário e todos os arquivos secundários que não são colocados em outros grupos de arquivos.
- Grupos de arquivos definidos pelo usuário podem ser criados para agrupar os arquivos de dados para fins administrativos, de alocação de dados e de posicionamento.
Por exemplo: Data1.ndf, Data2.ndf e Data3.ndf, podem ser criados em três unidades de disco, respectivamente, e atribuídos ao grupo de arquivos fgroup1. Uma tabela pode ser criada especificamente no grupo de arquivos fgroup1. As consultas para obter dados da tabela serão distribuídas pelos três discos; isso aprimorará o desempenho. A mesma melhora no desenvolvimento pode acontecer, usando um único arquivo criado em um conjunto distribuído RAID (redundant array of independent disks). Porém, arquivos e grupos de arquivos permitem que novos arquivos sejam facilmente adicionados aos novos discos.
Todos os arquivos de dados são armazenados nos grupos de arquivos listados na tabela a seguir.
| Grupo de arquivos | Descrição |
|---|---|
| Primária | O grupo de arquivos que contém o arquivo primário. Todas as tabelas do sistema fazem parte do grupo de arquivos primário. |
| Dados otimizados para memória | Um grupo de arquivos com otimização de memória baseia-se no grupo de arquivos do fluxo de arquivos |
| Filestream | |
| Definido pelo usuário | Qualquer grupo de arquivos que seja criado pelo usuário quando o usuário cria o banco de dados pela primeira vez ou quando o modifica posteriormente. |
Grupo de arquivos padrão (primário)
Quando objetos são criados no banco de dados sem especificar a qual grupo de arquivos eles pertencem, os objetos são atribuídos ao grupo de arquivos padrão. A qualquer hora, um grupo de arquivos é designado como o grupo de arquivos padrão. Os arquivos no grupo de arquivos padrão devem ser grandes o suficientes para armazenar qualquer objeto novo alocado a outros grupos de arquivo.
O grupo de arquivos PRIMÁRIO é o grupo de arquivos padrão, a menos que seja alterado usando a instrução ALTER DATABASE. A alocação para os objetos de sistema e de tabelas permanece no grupo de arquivos PRIMÁRIO, e não no novo grupo de arquivos padrão.
Grupo de arquivos de dados com otimização de memória
Para obter mais informações sobre grupos de arquivos com otimização de memória, consulte Grupo de arquivos otimizado para memória.
Grupos de arquivos FILESTREAM
Para obter mais informações sobre grupos de arquivos FILESTREAM, confira FILESTREAM e Criar um banco de dados habilitado para FILESTREAM.
Exemplo de arquivo e grupo de arquivos
O exemplo a seguir cria um banco de dados em uma instância do SQL Server. O banco de dados tem um arquivo de dados primário, um grupo de arquivos definido pelo usuário e um arquivo de log. O arquivo de dados primário está no grupo de arquivos primário e o grupo de arquivos definido pelo usuário tem dois arquivos de dados secundários. Uma instrução ALTER DATABASE torna padrão o grupo de arquivos definido pelo usuário. Depois, é criada uma tabela que especifica o grupo de arquivos definido pelo usuário. (Este exemplo usa um caminho genérico c:\Program Files\Microsoft SQL Server\MSSQL.1 para evitar especificando uma versão do SQL Server.)
USE master;
GO
-- Create the database with the default data
-- filegroup, filestream filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Dat2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
GO
-- Create a table in the user-defined filegroup.
USE MyDB;
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
GO
-- Create a table in the filestream filegroup
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
)
GO
A ilustração a seguir resume os resultados do exemplo anterior (exceto para os dados do fluxo de arquivos).

Estratégia de arquivo e de preenchimento de grupo de arquivos
Os grupos de arquivos usam uma estratégia de preenchimento proporcional em todos os arquivos de cada grupo de arquivos. Como os dados são gravados no grupo de arquivos, o Mecanismo de Banco de Dados do SQL Server grava uma quantidade proporcional no espaço livre de cada arquivo dentro do grupo de arquivos, em vez de gravar todos os dados no primeiro arquivo até que ele seja preenchido. Em seguida, grava no arquivo seguinte. Por exemplo, se o arquivo f1 tiver 100 MB livres e o arquivo f2 tiver 200 MB livres, uma extensão será dada pelo arquivo f1, duas extensões do arquivo f2 e assim por diante. Dessa forma, todos os arquivos são preenchidos quase simultaneamente, e uma distribuição simples é obtida.
Por exemplo, um grupo de arquivos compõe-se de três arquivos, todos definidos para aumentar automaticamente. Quando se extingue o espaço em todos os arquivos do grupo de arquivos, somente o primeiro arquivo é expandido. Quando o primeiro arquivo é preenchido e não é mais possível gravar dados no grupo de arquivos, o segundo arquivo é expandido. Quando o segundo arquivo está cheio e não é mais possível gravar dados no grupo de arquivos, o terceiro arquivo é expandido. Se o terceiro arquivos se tornar cheio e não for mais possível gravar dados no grupo de arquivos, o primeiro arquivo é expandido novamente, e assim por diante.
Regras para criar arquivos e grupos de arquivos
As regras a seguir pertencem aos arquivos e grupos de arquivos:
- Arquivo ou grupos de arquivos não podem ser usados por mais que um banco de dados. Por exemplo, os arquivos
sales.mdfesales.ndf, que contêm dados e objetos do banco de dados de vendas, não podem ser usados por nenhum outro banco de dados. - Um arquivo pode ser um membro apenas de um único grupo de arquivos.
- Os arquivos de log de transação nunca integram nenhum grupo de arquivos.
Recomendações
Recomendações ao trabalhar com arquivos e grupos de arquivos:
- A maioria dos bancos de dados funcionará bem com um único arquivo de dados e um único arquivo de log de transação.
- Se estiver usando vários arquivos de dados, crie um segundo grupo de arquivos para o arquivo adicional e transforme o grupo de arquivos no grupo de arquivos padrão. Desse modo, o arquivo primário conterá somente tabelas e objetos do sistema.
- Para maximizar o desempenho, crie arquivos ou grupos de arquivos no maior número possível de discos disponíveis diferentes. Insira objetos que disputem pesadamente por espaço em diferentes grupos de arquivos.
- Use grupos de arquivos para ativar a colocação de objetos em discos físicos específicos.
- Insira tabelas diferentes usadas nas mesmas consultas de junção em diferentes grupos de arquivos. Essa etapa aprimorará o desempenho por conta da busca por dados ingressados pela E/S paralela do disco.
- Insira tabelas excessivamente acessadas e índices não clusterizados que pertençam às tabelas de diferentes grupos de arquivos. O uso de grupos de arquivos diferentes aprimorará o desempenho por causa da E/S paralela, caso os arquivos estejam localizados em discos físicos diferentes.
- Não insira os arquivos de log de transações no mesmo disco físico que contém os outros arquivos e grupos de arquivos.
- Caso você precise estender uma partição ou um volume no qual os arquivos de banco de dados residem usando ferramentas como o Diskpart, faça backup de todos os bancos de dados do sistema e de usuário e interrompa os serviços do SQL Server primeiro. Além disso, quando os volumes de disco forem estendidos com êxito, considere a possibilidade de executar o comando
DBCC CHECKDBpara garantir a integridade física de todos os bancos de dados que residem no volume.
Para obter mais informações sobre recomendações sobre o gerenciamento de arquivos de log de transações, consulte Gerenciar o tamanho do arquivo de log de transações.
Conteúdo relacionado
- CREATE DATABASE (SQL Server Transact-SQL)
- Opções de arquivo e grupos de arquivos ALTER DATABASE (Transact-SQL)
- Anexar e desanexar bancos de dados (SQL Server)
- Guia de arquitetura e gerenciamento de log de transações do SQL Server
- Guia de arquitetura de página e extensões
- Gerenciar o tamanho do arquivo de log de transações