Serialização do modelo de dados de e para diferentes repositórios (versão prévia)
Para que seu modelo de dados seja armazenado em um banco de dados, ele precisa ser convertido em um formato que o banco de dados possa entender. Bancos de dados diferentes exigem esquemas e formatos de armazenamento diferentes. Alguns têm um esquema estrito que precisa ser cumprido, enquanto outros permitem que o esquema seja definido pelo usuário.
Opções de mapeamento
Os conectores do repositório de vetores fornecidos pelo Kernel Semântico fornecem várias maneiras de obter esse mapeamento.
Mapeadores integrados
Os conectores do repositório de vetores fornecidos pelo Kernel Semântico têm mapeadores internos que mapearão seu modelo de dados de e para os esquemas de banco de dados. Consulte a página para cada conector para obter mais informações sobre como os mapeadores internos mapeiam dados para cada banco de dados.
Mapeadores personalizados
Os conectores de armazenamento vetorial fornecidos pelo Kernel Semântico permitem o uso de mapeadores personalizados em combinação com um VectorStoreRecordDefinition. Nesse caso, o VectorStoreRecordDefinition pode ser diferente do modelo de dados fornecido.
O VectorStoreRecordDefinition é usado para definir o esquema de banco de dados, enquanto o modelo de dados é usado pelo desenvolvedor para interagir com o repositório de vetores.
Nesse caso, um mapeador personalizado é necessário para mapear do modelo de dados para o esquema de banco de dados personalizado definido pelo VectorStoreRecordDefinition.
Dica
Consulte Como criar um mapeador personalizado para um conector da Vector Store para obter um exemplo sobre como criar seu próprio mapeador personalizado.
Para que seu modelo de dados definido como uma classe ou uma definição seja armazenado em um banco de dados, ele precisa ser serializado em um formato que o banco de dados possa entender.
Há duas maneiras de fazer isso, usando a serialização interna fornecida pelo Kernel Semântico ou fornecendo sua própria lógica de serialização.
Os dois diagramas seguintes ilustram os fluxos envolvidos na serialização e desserialização de modelos de dados de e para um modelo de repositório.
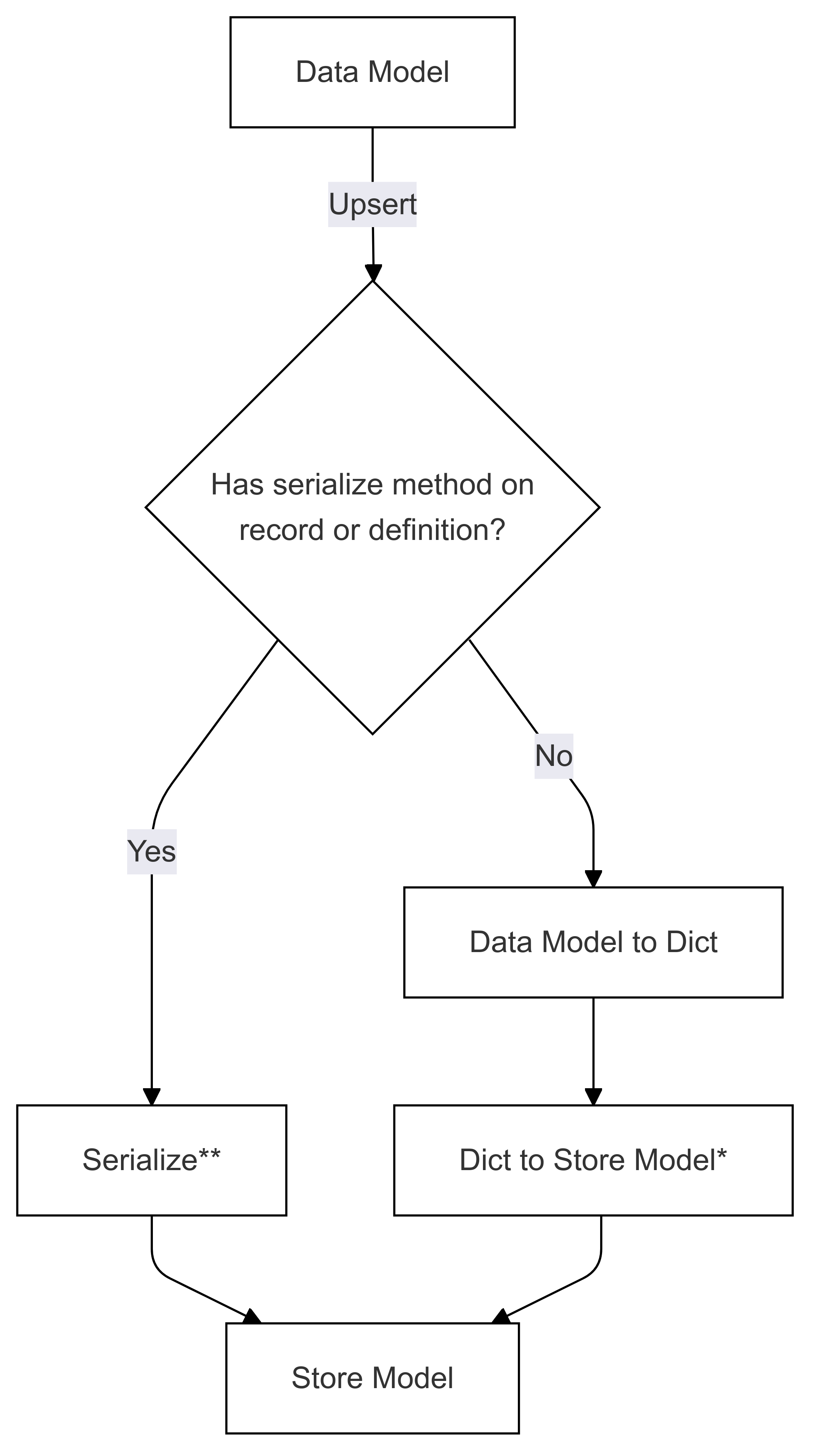
Fluxo de serialização (usado em Upsert)
Fluxo de Desserialização (usado em Get e Search)
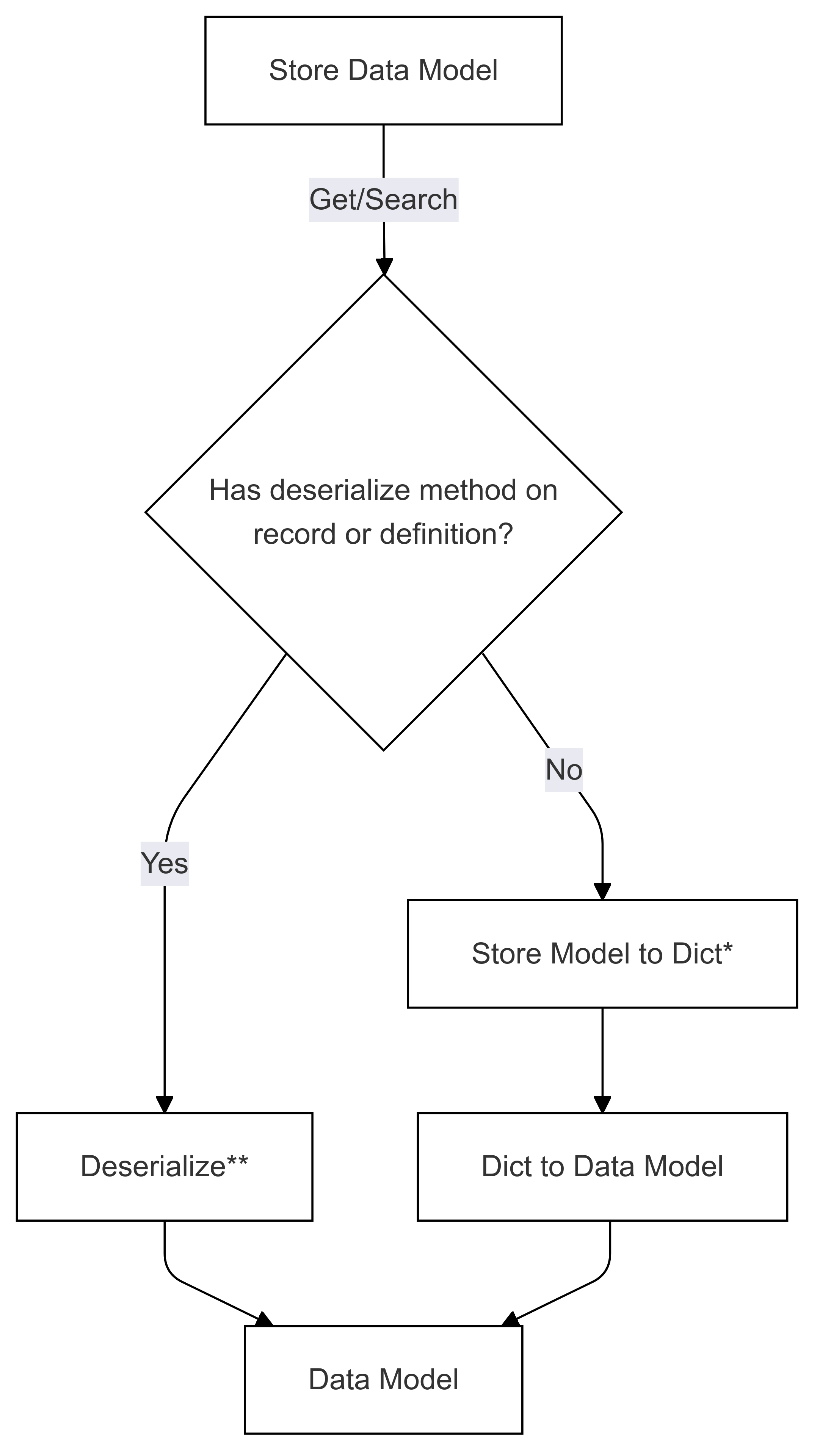
As etapas marcadas com * (em ambos os diagramas) são implementadas pelo desenvolvedor de um conector específico e são diferentes para cada repositório. As etapas marcadas com ** (em ambos os diagramas) são fornecidas como um método em um registro ou como parte da definição de registro, isso sempre é fornecido pelo usuário, consulte de Serialização Direta para obter mais informações.
(De)serialização: abordagens
Serialização direta (modelo de dados para armazenar modelo)
A serialização direta é a melhor maneira de garantir o controle total sobre como seus modelos são serializados e otimizar o desempenho. A desvantagem é que ele é específico para um armazenamento de dados e, portanto, ao usá-lo, não é tão fácil alternar entre repositórios diferentes com o mesmo modelo de dados.
Você pode usá-lo implementando um método que segue o protocolo SerializeMethodProtocol em seu modelo de dados ou adicionando funções que seguem o SerializeFunctionProtocol à definição de registro, ambas podem ser encontradas em semantic_kernel/data/vector_store_model_protocols.py.
Quando uma dessas funções estiver presente, ela será usada para serializar diretamente o modelo de dados para o modelo de armazenamento.
Você poderia até mesmo implementar apenas um dos dois e usar a serialização interna (de)para a outra direção, isso poderia, por exemplo, ser útil ao lidar com uma coleção que foi criada fora do seu controle e você precisa fazer alguma personalização da maneira como ela é desserializada (e você não pode fazer um upsert de qualquer maneira).
Serialização embutida (de)serialização (Modelo de Dados para Dicionário e Dicionário para Modelo de Armazenamento e vice-versa)
A serialização interna é feita primeiro convertendo o modelo de dados em um dicionário e, em seguida, serializando-o no modelo que esse repositório entende, para cada repositório diferente e definido como parte do conector interno. A desserialização é feita na ordem inversa.
Etapa de serialização 1: modelo de dados para ditado
Dependendo do tipo de modelo de dados que você tem, as etapas são feitas de maneiras diferentes. Há quatro maneiras de tentar serializar o modelo de dados em um dicionário:
-
to_dictmétodo na definição (alinha-se ao atributo to_dict do modelo de dados, seguindo oToDictFunctionProtocol) - verificar se o registro é um
ToDictMethodProtocole usar o métodoto_dict - verifique se o registro é um modelo Pydantic e use o
model_dumpdo modelo; veja a nota abaixo para mais informações. - percorrer os campos na definição e criar o dicionário
Etapa de serialização 2: Dic to Store Model
Um método deve ser fornecido pelo conector para converter o dicionário no modelo de repositório. Isso é feito pelo desenvolvedor do conector e é diferente para cada loja.
Etapa de Desserialização 1: Armazenar modelo para Ditado
Um método deve ser fornecido pelo conector para converter o modelo de repositório em um dicionário. Isso é feito pelo desenvolvedor do conector e é diferente para cada loja.
Etapa de Desserialização 2: Ditar para o Modelo de Dados
A desserialização é feita na ordem inversa, ela tenta estas opções:
-
from_dictmétodo na definição (alinha-se ao atributo from_dict do modelo de dados, seguindo oFromDictFunctionProtocol) - Verifique se o registro é um
FromDictMethodProtocole utilize o métodofrom_dict. - Verifique se o registro é um modelo Pydantic e use o
model_validatedo modelo; veja a observação abaixo para mais informações. - Percorra os campos na definição e defina os valores, então esse dicionário é passado para o construtor do modelo de dados como parâmetros nomeados (a menos que o modelo de dados seja um dicionário por si mesmo, nesse caso ele é retornado como está)
Nota
Usando Pydantic com serialização embutida
Quando você define seu modelo usando um Pydantic BaseModel, ele usará os model_dump métodos and model_validate para serializar e desserializar o modelo de dados de e para um dict. Isso é feito usando o método model_dump sem parâmetros, se você quiser controlar isso, considere implementar o ToDictMethodProtocol em seu modelo de dados, pois isso é tentado primeiro.
Serialização de vetores
Quando você tem um vetor em seu modelo de dados, ele precisa ser uma lista de floats ou uma lista de ints, já que é isso que a maioria das lojas precisa, se você quiser que sua classe armazene o vetor em um formato diferente, você pode usar o serialize_function e deserialize_function definido na VectorStoreRecordVectorField anotação. Por exemplo, para uma matriz numpy, você pode usar a seguinte anotação:
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
Se você usar um armazenamento de vetores que possa lidar com matrizes numpy nativas e não quiser convertê-las para frente e para trás, você deverá configurar os métodos de serialização e desserialização diretas para o modelo e esse armazenamento.
Nota
Isso só é usado quando se utiliza a serialização interna; ao usar a serialização direta, você pode manipular o vetor da maneira desejada.
Em breve
Mais informações em breve.