O que é um plug-in?
Plug-ins são um componente chave do Kernel Semântico. Se você já usou plug-ins de extensões ChatGPT ou Copilot no Microsoft 365, já está familiarizado com eles. Com plug-ins, você pode encapsular suas APIs existentes em uma coleção que pode ser usada por uma IA. Isso permite que você dê à IA a capacidade de executar ações que não seriam capazes de fazer de outra forma.
Nos bastidores, o Kernel Semântico aproveita chamada de função, um recurso nativo da maioria das LLMs mais recentes para permitir LLMs, executar planejamento e invocar suas APIs. Com a chamada de função, as LLMs podem solicitar (ou seja, chamar) uma função específica. O Kernel Semântico, em seguida, realiza a intermediação da solicitação para a função apropriada em sua base de código e retorna os resultados de volta para a LLM para que a LLM possa gerar uma resposta final.
plugin de kernel semântico 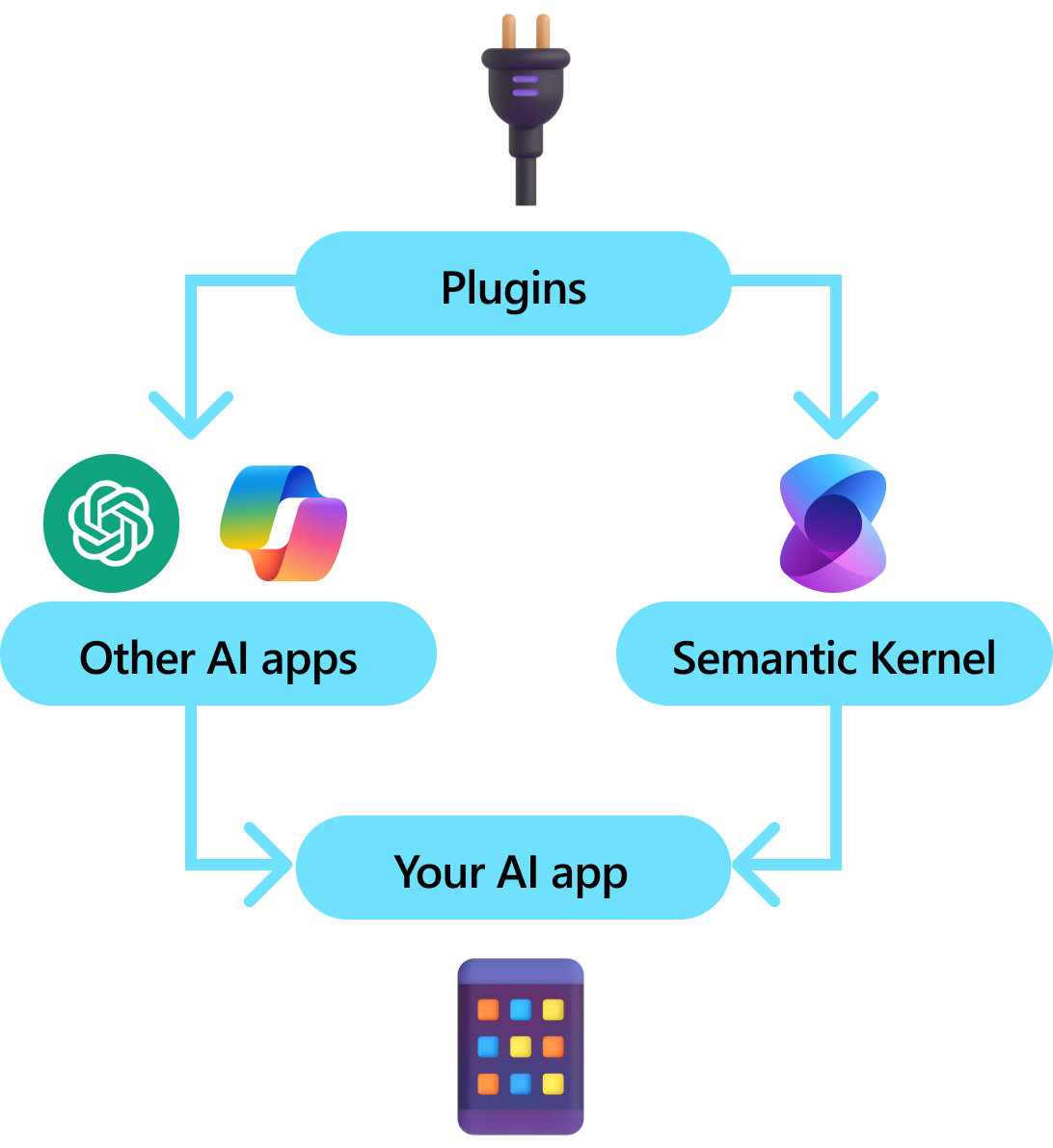
Nem todos os SDKs de IA têm um conceito análogo aos plug-ins (a maioria tem apenas funções ou ferramentas). Em cenários empresariais, no entanto, os plug-ins são valiosos porque encapsulam um conjunto de funcionalidades que espelha como os desenvolvedores empresariais já desenvolvem serviços e APIs. Plugins também funcionam bem com injeção de dependência. No construtor de um plug-in, você pode injetar serviços necessários para executar o trabalho do plug-in (por exemplo, conexões de banco de dados, clientes HTTP etc.). Isso é difícil de realizar com outros SDKs que não têm plug-ins.
Anatomia de um plug-in
Em um alto nível, um plug-in é um grupo de funções que podem ser expostas a aplicativos e serviços de IA. As funções dentro de plug-ins podem ser orquestradas por um aplicativo de IA para realizar solicitações de usuário. No Kernel Semântico, você pode invocar essas funções automaticamente com a chamada de função.
Nota
Em outras plataformas, as funções geralmente são conhecidas como "ferramentas" ou "ações". No Kernel Semântico, usamos o termo "funções", pois elas normalmente são definidas como funções nativas em sua base de código.
Apenas fornecer funções, no entanto, não é suficiente para fazer um plug-in. Para alimentar a orquestração automática com chamada de função, os plug-ins também precisam fornecer detalhes que descrevem semanticamente como se comportam. Tudo, desde a entrada, saída e efeitos colaterais da função, precisa ser descrito de uma maneira que a IA possa entender, caso contrário, a IA não chamará corretamente a função.
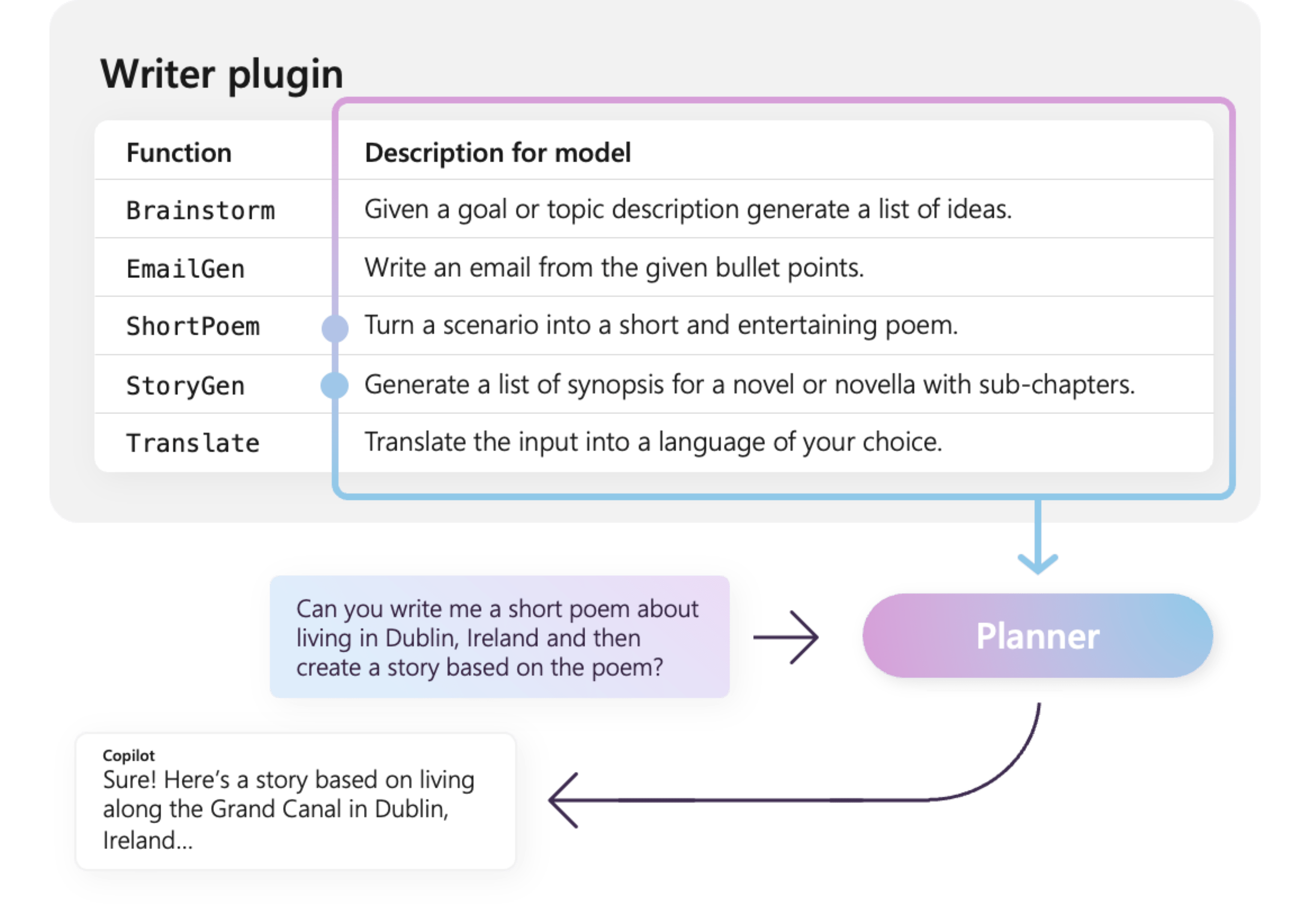
Por exemplo, o exemplo WriterPlugin plug-in à direita tem funções com descrições semânticas que descrevem o que cada função faz. Em seguida, uma LLM pode usar essas descrições para escolher as melhores funções para chamar para atender à pergunta de um usuário.
Na imagem à direita, uma LLM provavelmente chamaria as funções ShortPoem e StoryGen para satisfazer o pedido dos usuários, graças às descrições semânticas fornecidas.
Importando diferentes tipos de plug-ins
Há duas maneiras principais de importar plugins para o Kernel Semântico: código nativo ou uma especificação OpenAPI. O primeiro permite criar plug-ins em sua base de código existente que podem aproveitar dependências e serviços que você já tem. Este último permite importar plug-ins de uma especificação OpenAPI, que pode ser compartilhada entre diferentes linguagens e plataformas de programação.
Abaixo, fornecemos um exemplo simples de importação e uso de um plug-in nativo. Para saber mais sobre como importar esses diferentes tipos de plug-ins, consulte os seguintes artigos:
Dica
Ao começar, recomendamos usar plug-ins de código nativos. À medida que seu aplicativo amadurece e, à medida que você trabalha entre equipes multiplataforma, convém considerar o uso de especificações do OpenAPI para compartilhar plug-ins em diferentes linguagens de programação e plataformas.
Os diferentes tipos de funções de plug-in
Em um plug-in, você normalmente terá dois tipos diferentes de funções: aquelas que recuperam dados para Geração Aumentada de Recuperação (RAG) e aquelas que automatizam tarefas. Embora cada tipo seja funcionalmente o mesmo, eles normalmente são usados de forma diferente em aplicativos que usam Kernel Semântico.
Por exemplo, com funções de recuperação, talvez você queira usar estratégias para melhorar o desempenho (por exemplo, cache e uso de modelos intermediários mais baratos para resumo). Considerando que, com as funções de automação de tarefas, você provavelmente desejará implementar processos de aprovação com intervenção humana para garantir que as tarefas sejam concluídas corretamente.
Para saber mais sobre os diferentes tipos de funções de plug-in, consulte os seguintes artigos:
- funções de recuperação de dados
- Funções de automação de tarefas
Introdução aos plug-ins
Usar plug-ins no Kernel Semântico é sempre um processo de três etapas:
- Defina seu plug-in
- Adicione o plugin ao kernel
- E, em seguida, invoque as funções do plug-in em um prompt com a chamada de função
Abaixo, forneceremos um exemplo de alto nível de como usar um plug-in no Kernel Semântico. Consulte os links acima para obter informações mais detalhadas sobre como criar e usar plug-ins.
1) Definir seu plug-in
A maneira mais fácil de criar um plug-in é definindo uma classe e anotando seus métodos com o atributo KernelFunction. Isso permite que o Kernel Semântico saiba que essa é uma função que pode ser chamada por uma IA ou referenciada em um prompt.
Você também pode importar plug-ins de uma especificação OpenAPI.
Abaixo, criaremos um plug-in que pode recuperar o estado das luzes e alterar seu estado.
Dica
Como a maioria das LLMs foram treinadas com Python para chamadas de função, é recomendável usar snake_case para nomes de função e nomes de propriedades, mesmo se você estiver usando o SDK do C# ou o Java.
using System.ComponentModel;
using Microsoft.SemanticKernel;
public class LightsPlugin
{
// Mock data for the lights
private readonly List<LightModel> lights = new()
{
new LightModel { Id = 1, Name = "Table Lamp", IsOn = false, Brightness = 100, Hex = "FF0000" },
new LightModel { Id = 2, Name = "Porch light", IsOn = false, Brightness = 50, Hex = "00FF00" },
new LightModel { Id = 3, Name = "Chandelier", IsOn = true, Brightness = 75, Hex = "0000FF" }
};
[KernelFunction("get_lights")]
[Description("Gets a list of lights and their current state")]
public async Task<List<LightModel>> GetLightsAsync()
{
return lights
}
[KernelFunction("get_state")]
[Description("Gets the state of a particular light")]
public async Task<LightModel?> GetStateAsync([Description("The ID of the light")] int id)
{
// Get the state of the light with the specified ID
return lights.FirstOrDefault(light => light.Id == id);
}
[KernelFunction("change_state")]
[Description("Changes the state of the light")]
public async Task<LightModel?> ChangeStateAsync(int id, LightModel LightModel)
{
var light = lights.FirstOrDefault(light => light.Id == id);
if (light == null)
{
return null;
}
// Update the light with the new state
light.IsOn = LightModel.IsOn;
light.Brightness = LightModel.Brightness;
light.Hex = LightModel.Hex;
return light;
}
}
public class LightModel
{
[JsonPropertyName("id")]
public int Id { get; set; }
[JsonPropertyName("name")]
public string Name { get; set; }
[JsonPropertyName("is_on")]
public bool? IsOn { get; set; }
[JsonPropertyName("brightness")]
public byte? Brightness { get; set; }
[JsonPropertyName("hex")]
public string? Hex { get; set; }
}
from typing import TypedDict, Annotated
class LightModel(TypedDict):
id: int
name: str
is_on: bool | None
brightness: int | None
hex: str | None
class LightsPlugin:
lights: list[LightModel] = [
{"id": 1, "name": "Table Lamp", "is_on": False, "brightness": 100, "hex": "FF0000"},
{"id": 2, "name": "Porch light", "is_on": False, "brightness": 50, "hex": "00FF00"},
{"id": 3, "name": "Chandelier", "is_on": True, "brightness": 75, "hex": "0000FF"},
]
@kernel_function
async def get_lights(self) -> List[LightModel]:
"""Gets a list of lights and their current state."""
return self.lights
@kernel_function
async def get_state(
self,
id: Annotated[int, "The ID of the light"]
) -> Optional[LightModel]:
"""Gets the state of a particular light."""
for light in self.lights:
if light["id"] == id:
return light
return None
@kernel_function
async def change_state(
self,
id: Annotated[int, "The ID of the light"],
new_state: LightModel
) -> Optional[LightModel]:
"""Changes the state of the light."""
for light in self.lights:
if light["id"] == id:
light["is_on"] = new_state.get("is_on", light["is_on"])
light["brightness"] = new_state.get("brightness", light["brightness"])
light["hex"] = new_state.get("hex", light["hex"])
return light
return None
public class LightsPlugin {
// Mock data for the lights
private final Map<Integer, LightModel> lights = new HashMap<>();
public LightsPlugin() {
lights.put(1, new LightModel(1, "Table Lamp", false));
lights.put(2, new LightModel(2, "Porch light", false));
lights.put(3, new LightModel(3, "Chandelier", true));
}
@DefineKernelFunction(name = "get_lights", description = "Gets a list of lights and their current state")
public List<LightModel> getLights() {
System.out.println("Getting lights");
return new ArrayList<>(lights.values());
}
@DefineKernelFunction(name = "change_state", description = "Changes the state of the light")
public LightModel changeState(
@KernelFunctionParameter(name = "id", description = "The ID of the light to change") int id,
@KernelFunctionParameter(name = "isOn", description = "The new state of the light") boolean isOn) {
System.out.println("Changing light " + id + " " + isOn);
if (!lights.containsKey(id)) {
throw new IllegalArgumentException("Light not found");
}
lights.get(id).setIsOn(isOn);
return lights.get(id);
}
}
Observe que fornecemos descrições para a função e parâmetros. Isso é importante para que a IA entenda o que a função faz e como usá-la.
Dica
Não tenha medo de fornecer descrições detalhadas para suas funções se uma IA estiver tendo problemas para chamá-las. Exemplos de poucas capturas, recomendações para quando usar (e não usar) a função e diretrizes sobre onde obter os parâmetros necessários podem ser úteis.
2) Adicionar o plug-in ao kernel
Depois de definir o plug-in, você pode adicioná-lo ao kernel criando uma nova instância do plug-in e adicionando-a à coleção de plug-ins do kernel.
Este exemplo demonstra a maneira mais fácil de adicionar uma classe como um plug-in com o método AddFromType. Para saber mais sobre outras maneiras de adicionar plug-ins, consulte o artigo adição de plug-ins nativos.
var builder = new KernelBuilder();
builder.Plugins.AddFromType<LightsPlugin>("Lights")
Kernel kernel = builder.Build();
kernel = Kernel()
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
// Import the LightsPlugin
KernelPlugin lightPlugin = KernelPluginFactory.createFromObject(new LightsPlugin(),
"LightsPlugin");
// Create a kernel with Azure OpenAI chat completion and plugin
Kernel kernel = Kernel.builder()
.withAIService(ChatCompletionService.class, chatCompletionService)
.withPlugin(lightPlugin)
.build();
3) Invocar as funções do plug-in
Por fim, você pode fazer com que a IA invoque as funções do plug-in usando a chamada de função. Veja abaixo um exemplo que demonstra como persuadir a IA a chamar a função get_lights do plug-in Lights antes de chamar a função change_state para ativar uma luz.
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Create a kernel with Azure OpenAI chat completion
var builder = Kernel.CreateBuilder().AddAzureOpenAIChatCompletion(modelId, endpoint, apiKey);
// Build the kernel
Kernel kernel = builder.Build();
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
// Add a plugin (the LightsPlugin class is defined below)
kernel.Plugins.AddFromType<LightsPlugin>("Lights");
// Enable planning
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// Create a history store the conversation
var history = new ChatHistory();
history.AddUserMessage("Please turn on the lamp");
// Get the response from the AI
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
// Print the results
Console.WriteLine("Assistant > " + result);
// Add the message from the agent to the chat history
history.AddAssistantMessage(result);
import asyncio
from semantic_kernel import Kernel
from semantic_kernel.functions import kernel_function
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.chat_completion_client_base import ChatCompletionClientBase
from semantic_kernel.contents.chat_history import ChatHistory
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.connectors.ai.open_ai.prompt_execution_settings.azure_chat_prompt_execution_settings import (
AzureChatPromptExecutionSettings,
)
async def main():
# Initialize the kernel
kernel = Kernel()
# Add Azure OpenAI chat completion
chat_completion = AzureChatCompletion(
deployment_name="your_models_deployment_name",
api_key="your_api_key",
base_url="your_base_url",
)
kernel.add_service(chat_completion)
# Add a plugin (the LightsPlugin class is defined below)
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
# Enable planning
execution_settings = AzureChatPromptExecutionSettings()
execution_settings.function_choice_behavior = FunctionChoiceBehavior.Auto()
# Create a history of the conversation
history = ChatHistory()
history.add_message("Please turn on the lamp")
# Get the response from the AI
result = await chat_completion.get_chat_message_content(
chat_history=history,
settings=execution_settings,
kernel=kernel,
)
# Print the results
print("Assistant > " + str(result))
# Add the message from the agent to the chat history
history.add_message(result)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())
// Enable planning
InvocationContext invocationContext = new InvocationContext.Builder()
.withReturnMode(InvocationReturnMode.LAST_MESSAGE_ONLY)
.withToolCallBehavior(ToolCallBehavior.allowAllKernelFunctions(true))
.build();
// Create a history to store the conversation
ChatHistory history = new ChatHistory();
history.addUserMessage("Turn on light 2");
List<ChatMessageContent<?>> results = chatCompletionService
.getChatMessageContentsAsync(history, kernel, invocationContext)
.block();
System.out.println("Assistant > " + results.get(0));
Com o código acima, você deve obter uma resposta semelhante à seguinte:
| Papel | Mensagem |
|---|---|
| 🔵 Usuário | Por favor, acenda a lâmpada |
| Assistente (chamada de função) de 🔴 | Lights.get_lights() |
| Ferramenta 🟢 | [{ "id": 1, "name": "Table Lamp", "isOn": false, "brightness": 100, "hex": "FF0000" }, { "id": 2, "name": "Porch light", "isOn": false, "brightness": 50, "hex": "00FF00" }, { "id": 3, "name": "Chandelier", "isOn": true, "brightness": 75, "hex": "0000FF" }] |
| Assistente (chamada de função) de 🔴 | Lights.change_state(1, { "isOn": true }) |
| Ferramenta 🟢 | { "id": 1, "name": "Table Lamp", "isOn": true, "brightness": 100, "hex": "FF0000" } |
| 🔴 Assistente | A lâmpada agora está ativada |
Dica
Embora você possa invocar uma função de plug-in diretamente, isso não é aconselhável porque a IA deve ser aquela que decide quais funções chamar. Se você precisar de controle explícito sobre quais funções são chamadas, considere usar métodos padrão em sua base de código em vez de plug-ins.
Recomendações gerais para criar plug-ins
Considerando que cada cenário tem requisitos exclusivos, utiliza designs de plugin distintos e pode incorporar várias LLMs, é um desafio fornecer um guia único para design de plugin. No entanto, abaixo estão algumas recomendações gerais e diretrizes para garantir que os plug-ins sejam amigáveis com IA e possam ser consumidos com facilidade e eficiência por LLMs.
Importar somente os plug-ins necessários
Importe apenas os plug-ins que contêm funções necessárias para seu cenário específico. Essa abordagem não apenas reduzirá o número de tokens de entrada consumidos, mas também minimizará a ocorrência de chamadas incorretas de função para funções que não são usadas no cenário. De modo geral, essa estratégia deve melhorar a precisão das chamadas de função e diminuir o número de falsos positivos.
Além disso, o OpenAI recomenda que você use no máximo 20 ferramentas em uma única chamada à API; idealmente, não mais do que 10 ferramentas. Conforme indicado pelo OpenAI: "Recomendamos que você use no máximo 20 ferramentas em uma única chamada à API. Os desenvolvedores normalmente veem uma redução na capacidade do modelo de selecionar a ferramenta correta depois que tiverem entre 10 e 20 ferramentas definidas."* Para obter mais informações, você pode visitar a documentação em Guia de Chamada de Funções do OpenAI.
Tornar os plug-ins amigáveis à IA
Para aprimorar a capacidade do LLM de entender e utilizar plug-ins, é recomendável seguir estas diretrizes:
Usar nomes de função descritivos e concisos: Verifique se os nomes de função transmitem claramente sua finalidade para ajudar o modelo a entender quando selecionar cada função. Se um nome de função for ambíguo, considere renomeá-lo para maior clareza. Evite usar abreviações ou acrônimos para reduzir nomes de função. Utilize o
DescriptionAttributepara fornecer contexto e instruções adicionais somente quando necessário, minimizando o consumo de token.Minimizar parâmetros de função: Limite o número de parâmetros de função e use tipos primitivos sempre que possível. Essa abordagem reduz o consumo de token e simplifica a assinatura da função, facilitando que o LLM corresponda efetivamente aos parâmetros de função.
Nomeie claramente parâmetros de função: Atribua nomes descritivos aos parâmetros de função para esclarecer sua finalidade. Evite usar abreviações ou acrônimos para reduzir nomes de parâmetros, pois isso ajudará a LLM no raciocínio sobre os parâmetros e no fornecimento de valores precisos. Assim como acontece com os nomes de função, use o
DescriptionAttributesomente quando necessário para minimizar o consumo de token.
Encontrar um equilíbrio correto entre o número de funções e suas responsabilidades
Por um lado, ter funções com uma única responsabilidade é uma boa prática que permite manter as funções simples e reutilizáveis em vários cenários. Por outro lado, cada chamada de função incorre em um custo adicional devido à latência de ida e volta da rede e ao número de tokens de entrada e saída consumidos: os tokens de entrada são usados para enviar a definição da função e o resultado da invocação ao LLM, enquanto os tokens de saída são consumidos ao receber a chamada de função do modelo.
Como alternativa, uma única função com várias responsabilidades pode ser implementada para reduzir o número de tokens consumidos e reduzir a sobrecarga de rede, embora isso tenha o custo de redução da reutilização em outros cenários.
No entanto, consolidar muitas responsabilidades em uma única função pode aumentar o número e a complexidade dos parâmetros de função e seu tipo de retorno. Essa complexidade pode levar a situações em que o modelo pode ter dificuldades para corresponder corretamente aos parâmetros de função, resultando em parâmetros ou valores perdidos de tipo incorreto. Portanto, é essencial atingir o equilíbrio certo entre o número de funções para reduzir a sobrecarga de rede e o número de responsabilidades que cada função tem, garantindo que o modelo possa corresponder com precisão aos parâmetros de função.
Transformar funções do Kernel Semântico
Utilize as técnicas de transformação para funções de Kernel Semântico, conforme descrito na postagem do blog Transforming Semântico Kernel Functions para:
Alterar o comportamento da função: Há cenários em que o comportamento padrão de uma função pode não se alinhar com o resultado desejado e não é viável modificar a implementação da função original. Nesses casos, você pode criar uma nova função que encapsula a original e modifica seu comportamento adequadamente.
Fornecer informações de contexto: Funções podem exigir parâmetros que a LLM não pode ou não deve inferir. Por exemplo, se uma função precisar agir em nome do usuário atual ou exigir informações de autenticação, esse contexto normalmente estará disponível para o aplicativo host, mas não para o LLM. Nesses casos, você pode transformar a função para invocar a original ao fornecer as informações de contexto necessárias do aplicativo de hospedagem, juntamente com os argumentos fornecidos pela LLM.
Alterar lista de parâmetros, tipos e nomes: Se a função original tiver uma assinatura complexa que a LLM luta para interpretar, você poderá transformar a função em uma com uma assinatura mais simples que a LLM possa entender com mais facilidade. Isso pode envolver a alteração de nomes de parâmetros, tipos, número de parâmetros e nivelamento ou desatenção de parâmetros complexos, entre outros ajustes.
Utilização de estado local
Ao criar plug-ins que operam em conjuntos de dados relativamente grandes ou confidenciais, como documentos, artigos ou emails que contêm informações confidenciais, considere utilizar o estado local para armazenar dados originais ou resultados intermediários que não precisam ser enviados para a LLM. As funções para esses cenários podem aceitar e retornar uma ID de estado, permitindo que você pesquise e acesse os dados localmente em vez de passar os dados reais para a LLM, apenas para recebê-los de volta como um argumento para a próxima invocação de função.
Ao armazenar dados localmente, você pode manter as informações privadas e seguras, evitando o consumo desnecessário de token durante chamadas de função. Essa abordagem não apenas aprimora a privacidade de dados, mas também melhora a eficiência geral no processamento de conjuntos de dados grandes ou confidenciais.
Fornecer esquema de tipo de retorno de função para o modelo de IA
Use uma das técnicas descritas na seção Fornecimento do esquema de tipo de retorno de funções para LLM para fornecer o esquema de tipo de retorno da função ao modelo de IA.
Ao utilizar um esquema de tipo de retorno bem definido, o modelo de IA pode identificar com precisão as propriedades pretendidas, eliminando possíveis imprecisões que podem surgir quando o modelo faz suposições com base em informações incompletas ou ambíguas na ausência do esquema. Consequentemente, isso aprimora a precisão das chamadas de função, levando a resultados mais confiáveis e precisos.