Sistemas e dependências de IA/ML da modelagem de ameaças
Por Andrew Marshall, Jugal Parikh, Emre Kiciman e Ram Shankar Siva Kumar
Agradecimentos especiais a Raul Rojas e ao fluxo de trabalho de engenharia de segurança da AETHER
Novembro de 2019
Este documento é resultado das práticas de engenharia da AETHER do grupo de trabalho de IA e complementa as práticas de modelagem de ameaças do SDL existentes, fornecendo novas diretrizes sobre a enumeração e a mitigação de ameaças específicas para IA e o espaço de Machine Learning. Ele deve ser usado como uma referência durante as revisões de design de segurança do seguinte:
Produtos/serviços que interagem com serviços baseados em IA/ML ou dependem deles
Produtos/serviços desenvolvidos com foco em IA/ML
A mitigação de ameaças à segurança tradicional é mais importante do que nunca. Os requisitos estabelecidos pelo ciclo de vida de desenvolvimento de segurança são essenciais para estabelecer uma base de segurança de produtos para essas diretrizes. A falha em lidar com as ameaças de segurança tradicionais ajuda a possibilitar ataques específicos de IA/ML abordados neste documento, tanto no software como nos domínios físicos, além de simplificar o comprometimento na pilha de software. Para obter uma introdução às novas ameaças de segurança nesse espaço, consulte Proteger o futuro da IA e do ML na Microsoft.
Os conjuntos de habilidades dos engenheiros de segurança e dos cientistas de dados normalmente não se sobrepõem. Essa orientação proporciona um modo de ambas as áreas dialogarem de forma estruturada sobre novas ameaças/mitigações sem exigir que os engenheiros de segurança se tornem cientistas de dados ou vice-versa.
Este documento é dividido em duas seções:
- "As principais considerações novas na modelagem de ameaças" se concentram em novas formas de pensar e novas perguntas a serem feitas durante a modelagem de ameaças de sistemas de IA/ML. Os cientistas de dados e os engenheiros de segurança devem estudar esse conteúdo, pois será seu manual para discussões de modelagem de ameaças e priorização de mitigação.
- "Ameaças específicas de IA/ML e suas mitigações" fornecem detalhes sobre ataques específicos, bem como etapas de mitigação específicas em uso atualmente para proteger os produtos e serviços da Microsoft contra essas ameaças. Esta seção destina-se principalmente a cientistas de dados que talvez precisem implementar atenuações de ameaças específicas como um resultado do processo de análise de ameaça/segurança.
Essas diretrizes são organizadas em uma taxonomia de ameaça, contraditória ao Machine Learning, criada por Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen e Jeffrey Snover e intitulada “Modos de falha no Machine Learning”. Para obter as diretrizes de gerenciamento de incidentes sobre ameaças de segurança de triagem detalhadas neste documento, consulte a Barra de bugs do SDL para ameaças de IA/ML. Todos esses são documentos ativos que evoluirão com o tempo com o cenário de ameaças.
Principais novas considerações na modelagem de ameaças: como alterar a maneira como você visualiza os limites de confiança
Assuma o comprometimento/envenenamento dos dados treinados, bem como o provedor de dados. Saiba como detectar entradas de dados anormais e mal-intencionadas e também como conseguir distingui-las e recuperá-las
Resumo
Os armazenamentos de dados de treinamento e os sistemas que os hospedam fazem parte do seu escopo de modelagem de ameaças. A maior ameaça de segurança no Machine Learning atualmente é o envenenamento de dados devido à falta de detecções e mitigações padrão nesse espaço, combinado com a dependência de conjuntos de dados públicos não confiáveis/não estruturados como fontes de dados de treinamento. Assim, é essencial acompanhar a comprovação e a linhagem de seus dados para garantir sua confiabilidade e evitar um ciclo de treinamento do tipo "entra lixo, sai lixo".
Perguntas em caso de revisão de segurança
Caso os dados sejam envenenados ou adulterados, como você saberia?
-Qual telemetria você precisa para detectar uma distorção na qualidade dos dados de treinamento?
Você está treinando as entradas fornecidas pelo usuário?
-Qual tipo de validação/limpeza de entrada você está fazendo no conteúdo?
-A estrutura desses dados foi documentada de forma semelhante a Planilhas para conjuntos de dados?
Se você treinar com armazenamentos de dados online, quais etapas serão executadas para garantir a segurança da conexão entre o modelo e os dados?
-Eles têm uma maneira de reportar comprometimentos aos consumidores de seus feeds?
-Eles têm essa capacidade?
Qual é a confidencialidade dos dados usados para o treinamento?
-Você cataloga os dados ou controla a adição/atualização/exclusão de entradas de dados?
Seu modelo pode gerar dados confidenciais?
-Esses dados foram obtidos com a permissão da origem?
O modelo gera apenas resultados de saída necessários para atingir sua meta?
O modelo retorna pontuações de confiança brutas ou qualquer outro resultado direto que poderia ser gravado e duplicado?
Qual é o impacto da recuperação dos dados de treinamento ao atacar/inverter seu modelo?
Se os níveis de confiança de sua saída do modelo forem descartados repentinamente, você poderá descobrir como e por que isso aconteceu, bem como os dados que causaram o problema?
Você definiu uma entrada bem formada para seu modelo? O que você está fazendo para garantir que as entradas atendam a esse formato e o que fará caso isso não aconteça?
Se as saídas estão erradas, mas não causam erros a serem relatados, como você descobrirá o problema?
Você sabe se os algoritmos de treinamento são resilientes a entradas adversárias em um nível matemático?
Como você se recupera da contaminação adversária de seus dados de treinamento?
-Você pode isolar/colocar conteúdo de adversário em quarentena e treinar novamente os modelos afetados?
-Você pode reverter/recuperar para um modelo de uma versão anterior e treinar novamente?
Você está usando o aprendizado por reforço em conteúdo público não organizado?
Comece a pensar sobre a linhagem dos dados: se você encontrou um problema, seria possível rastreá-lo até sua introdução no conjunto de dados? Caso contrário, isso é um problema?
Saiba de onde vêm seus dados de treinamento e identifique as normas estatísticas para começar a entender como funcionam as anomalias
-Quais elementos dos dados de treinamento estão vulneráveis à influência externa?
-Quem pode contribuir com os conjuntos de dados treinados por você?
-Como você atacaria as fontes de dados de treinamento para danificar um concorrente?
Ameaças e mitigações relacionadas neste documento
Perturbação de adversário (todas as variantes)
Envenenamento de dados (todas as variantes)
Exemplo de ataques
Forçar emails benignos a serem classificados como spam ou fazer com que um exemplo mal-intencionado não seja detectado
Entradas criadas pelo invasor que reduzem o nível de confiança da classificação correta, especificamente em cenários de alta consequência
O invasor injeta o ruído aleatoriamente nos dados de origem que estão sendo classificados para reduzir a probabilidade de a classificação correta ser usada no futuro, diminuindo efetivamente o modelo
Contaminação dos dados de treinamento para forçar a classificação indesejada de pontos de dados selecionados, resultando em ações específicas executadas ou omitidas por um sistema
Identificar as ações que seus modelos ou seu produto/serviço podem usar, o que pode causar danos online ao cliente ou domínio físico
Resumo
Sem mitigação, os ataques a sistemas de IA/ML podem chegar ao mundo físico. Qualquer cenário que possa ser usado para prejudicar psicológica ou fisicamente os usuários é um risco catastrófico para seu produto/serviço. Isso se estende a quaisquer dados confidenciais sobre seus clientes que são usados para opções de treinamento e design e podem revelar esses pontos de dados privados.
Perguntas em caso de revisão de segurança
Você treina com exemplos de adversário? Que impacto eles têm no resultado do modelo no domínio físico?
Como o engano se parece para seu produto/serviço? Como você pode detectar e reagir a isso?
O que seria necessário para fazer seu modelo retornar um resultado que faça seu serviço negar acesso a usuários legítimos?
Qual é o impacto da cópia/roubo do modelo?
O modelo pode ser usado para inferir a associação de um indivíduo em um determinado grupo ou apenas nos dados de treinamento?
Um invasor pode causar danos de reputação ou relações públicas ao seu produto, forçando-o a executar ações específicas?
Como você lida com dados devidamente formatados, mas tendenciosos, como de enganos?
Como cada maneira de interagir ou consultar seu modelo é exposta, esse método pode ser interrogado para divulgar dados de treinamento ou funcionalidade de modelo?
Ameaças e mitigações relacionadas neste documento
Inferência de associação
Inversão do modelo
Roubo de modelos
Exemplo de ataques
Reconstrução e extração de dados de treinamento ao consultar repetidamente o modelo para obter os resultados máximos de confiança
Duplicação do próprio modelo por correspondência de consulta/resposta exaustiva
Consultar o modelo de modo a revelar um elemento específico de dados privados que foi incluído no conjunto de treinamento
Carro autônomo sendo induzido a ignorar sinais de parada/semáforos
Bots de conversação manipulados para enganar usuários bem-intencionados
Identifique todas as fontes de dependências de IA/ML, bem como camadas de apresentação de front-end em sua cadeia de fornecimento de dados/modelo
Resumo
Muitos ataques à IA e ao Machine Learning começam com acesso legítimo às APIs que são apresentadas para fornecer acesso de consulta a um modelo. Por causa das sofisticadas fontes de dados e experiências de usuário envolvidas aqui, o acesso autenticado, mas "inapropriado" (há uma área cinza aqui) de terceiros aos seus modelos é um risco devido à capacidade de atuar como uma camada de apresentação acima de um serviço fornecido pela Microsoft.
Perguntas em caso de revisão de segurança
Quais clientes/parceiros são autenticados para terem acesso ao seu modelo ou às suas APIs de serviço?
-Eles podem atuar como uma camada de apresentação sobre seu serviço?
-Você pode revogar seu acesso imediatamente em caso de comprometimento?
-Qual é sua estratégia de recuperação no caso de uso mal-intencionado de seu serviço ou de suas dependências?
Terceiros podem criar uma fachada em seu modelo para darem a ele um novo propósito e prejudicar a Microsoft ou seus clientes?
Os clientes fornecem dados de treinamento diretamente para você?
-Como você protege esses dados?
-E se forem mal-intencionados e seu serviço for o alvo?
Como seria um falso positivo neste caso? Qual é o impacto de um falso negativo?
Você pode acompanhar e medir o desvio de taxas de positivos verdadeiros e falsos positivos em vários modelos?
De qual tipo de telemetria você precisa para provar a confiabilidade da saída do modelo para seus clientes?
Identifique todas as dependências de terceiros na sua cadeia de fornecimento de dados de ML/treinamento, não apenas de software livre, mas também de provedores de dados
-Por que você os utiliza e como verificar sua confiabilidade?
Você está usando modelos predefinidos de terceiros ou enviando dados de treinamento para provedores MLaaS de terceiros?
Notícias de inventário sobre ataques a produtos/serviços semelhantes. Depois de reconhecer que muitas ameaças de IA/ML são transferidas entre tipos de modelo, que impacto esses ataques teriam em seus próprios produtos?
Ameaças e mitigações relacionadas neste documento
Reprogramação de rede neural
Exemplos de adversário no domínio físico
Provedores de ML mal-intencionados recuperando dados de treinamento
Ataque à cadeia de suprimentos de ML
Modelo de backdoor
Dependências de ML específicas comprometidas
Exemplo de ataques
O provedor de MLaaS mal-intencionado usa cavalos de Troia em seu modelo com um bypass específico
O cliente adversário encontra uma vulnerabilidade na dependência de OSS comum que você usa, carrega a carga de dados de treinamento criada para comprometer seu serviço
O parceiro inescrupuloso usa APIs de reconhecimento facial e cria uma camada de apresentação sobre seu serviço para produzir falsificações detalhadas.
Ameaças específicas de IA/ML e suas mitigações
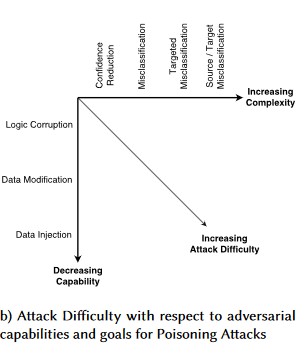
Nº 1: perturbação de adversário
Descrição
Em ataques de estilo de perturbação, o invasor modifica furtivamente a consulta para obter uma resposta desejada de um modelo implantado por produção[1]. Essa é uma violação da integridade de entrada do modelo que resulta em ataques de estilo difuso, nos quais o resultado final não é necessariamente uma violação de acesso ou EOP, mas, em vez disso, compromete o desempenho de classificação do modelo. Isso também pode ser manifestado por enganadores usando determinadas palavras de destino de modo que a IA as proíba, negando efetivamente o serviço a usuários legítimos com um nome correspondente a uma palavra "banida".
 [24]
[24]
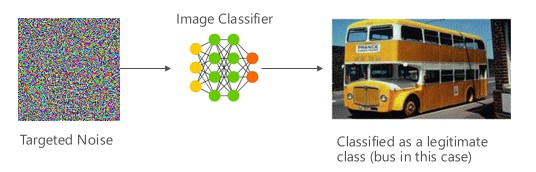
Variante nº 1a: classificação incorreta direcionada
Neste caso, os invasores geram um exemplo que não está na classe de entrada do classificador de destino, mas é classificado pelo modelo como aquela classe de entrada específica. O exemplo de adversário pode parecer um ruído aleatório aos olhos humanos, mas os invasores têm algum conhecimento sobre o sistema de Machine Learning de destino para gerar um ruído permitido que não é aleatório, mas explora alguns aspectos específicos do modelo de destino. O adversário fornece um exemplo de entrada que não é um exemplo legítimo, mas o sistema de destino o classifica como uma classe legítima.
Exemplos
 [6]
[6]
Mitigações
Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training (Reforçar a robustez de adversário usando confiança de modelo induzida por treinamento de adversário, em tradução livre) [19]: os autores propõem um HCNN (vizinho próximo altamente confiável), uma estrutura que combina informações de confiança e a pesquisa de vizinho mais próximo, para reforçar a robustez de adversário de um modelo de base. Isso pode ajudar a distinguir entre previsões de modelo corretas e incorretas em uma vizinhança de um ponto de amostragem da distribuição de treinamento subjacente.
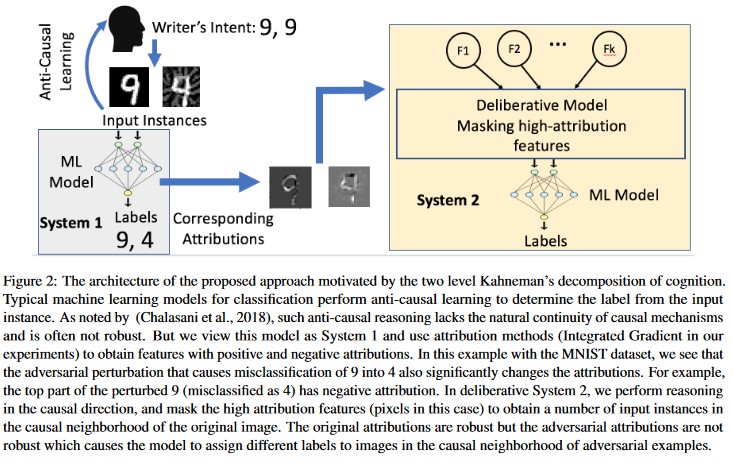
Attribution-driven Causal Analysis (Análise causal orientada para atribuição, em tradução livre) [20]: os autores estudam a conexão entre a resiliência para perturbações de adversário e a explicação com base em atribuição de decisões individuais geradas por modelos de machine learning. Eles relatam que as entradas de adversário não são robustas no espaço de atribuição, ou seja, mascarar alguns recursos com alta atribuição resulta na mudança da decisão do modelo de Machine Learning nos exemplos de adversário. Por outro lado, as entradas naturais são robustas no espaço de atribuição.
 [20]
[20]
Essas abordagens podem tornar os modelos de Machine Learning mais resilientes a ataques de adversário, pois enganar esse sistema cognição de duas camadas requer não apenas atacar o modelo original, mas também garantir que a atribuição gerada para o exemplo de adversário seja semelhante aos exemplos originais. Ambos os sistemas devem ser comprometidos simultaneamente para que um ataque de adversário seja bem-sucedido.
Paralelos tradicionais
Elevação remota de privilégio, pois o invasor agora está no controle do seu modelo
Severidade
Crítico
Variante nº 1b: classificação incorreta de origem/destino
Isso é caracterizado como uma tentativa de um invasor obter um modelo para retornar seu rótulo desejado para uma entrada específica. Isso geralmente força um modelo a retornar um falso positivo ou falso negativo. O resultado final é uma tomada sutil da precisão de classificação do modelo, na qual um invasor pode induzir bypasses específicos de acordo com sua vontade.
Embora esse ataque tenha um impacto prejudicial significativo na precisão da classificação, ele também pode ser mais demorado, pois um adversário deve não apenas manipular os dados de origem para que não sejam mais rotulados corretamente, mas também rotulá-los especificamente com o rótulo fraudulento desejado. Em geral, esses ataques envolvem várias etapas/tentativas para forçar a classificação indesejada [3]. Se o modelo estiver suscetível a ataques de transferência de aprendizado que forçam a classificação indireta, pode não haver nenhum volume de tráfego de invasor discernível, pois os ataques de investigação podem ser executados offline.
Exemplos
Forçar emails benignos a serem classificados como spam ou fazer com que um exemplo mal-intencionado não seja detectado. Eles também são conhecidos como evasão de modelo ou ataques do tipo mimicry.
Mitigações
Ações de detecção reativas/defensivas
- Implemente um limite de tempo mínimo entre chamadas para a API fornecendo resultados de classificação. Isso reduz o teste de ataque de várias etapas aumentando a quantidade geral de tempo necessária para encontrar uma perturbação bem-sucedida.
Ações proativas/de proteção
Feature Denoising for Improving Adversarial Robustness (Cancelamento de ruído de recursos para melhoria da robustez de adversário, em tradução livre) [22]: os autores desenvolvem uma nova arquitetura de rede que aumenta a robustez de adversários executando o recurso de remoção do ruído. As redes contêm blocos que removem o ruído dos recursos usando meios não locais ou outros filtros; as redes inteiras são treinadas de ponta a ponta. Quando combinado com o treinamento de adversário, o recurso de remoção de ruído das redes melhora substancialmente a eficiência na robustez de adversários nas configurações de ataque de caixa branca e de caixa preta.
Adversarial Training and Regularization (Treinamento de adversário e regularização, em tradução livre): treine com exemplos conhecidos do adversário para criar resiliência e robustez em relação a entradas mal-intencionadas. Isso também pode ser visto como uma forma de regularização, que penaliza a norma de gradientes de entrada e suaviza a função de previsão do classificador (aumentando a margem de entrada). Isso inclui as classificações corretas com taxas de confiança mais baixas.
Invista no desenvolvimento de classificação monotônico com a seleção de recursos monotônicos. Isso garante que o adversário não será capaz de escapar do classificador ao preencher os recursos da classe negativa [13].
O recurso de compactação [18] pode ser usado para proteger os modelos de DNN detectando exemplos de adversários. Ele reduz o espaço de pesquisa disponível para um adversário por meio da mescla de exemplos que correspondem a muitos vetores de recursos diferentes no espaço original em uma única amostra. Ao comparar uma previsão do modelo DNN na entrada original com o da entrada compactada, o recurso compactado pode ajudar a detectar exemplos de adversário. Se os exemplos originais e compactados produzirem saídas substancialmente diferentes do modelo, a entrada provavelmente será um adversário. Ao avaliar a diferença entre previsões e selecionando um valor de limite, o sistema pode gerar a previsão correta para exemplos legítimos e rejeitar as entradas de adversários.

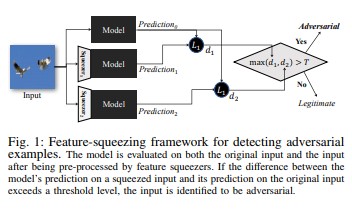 [18]
[18]Certified Defenses against Adversarial Examples (Exemplos de defesas certificadas contra adversários, em tradução livre) [22]: os autores propõem um método com base em um relaxamento semidefinido que gera um certificado para uma determinada rede e entrada de teste; nenhum ataque pode forçar o erro a exceder um determinado valor. Em segundo lugar, como esse certificado é diferenciável, os autores o otimizam em conjunto com os parâmetros de rede, fornecendo uma regularizador adaptável que incentiva a robustez contra todos os ataques.
Ações de resposta
- A emissão de alertas sobre resultados de classificação com alta variação entre classificadores, especialmente de um único usuário ou um pequeno grupo de usuários.
Paralelos tradicionais
Elevação de privilégio remota
Severidade
Crítico
Variante nº 1c: classificação incorreta aleatória
Essa é uma variação especial em que a classificação de destino do invasor pode ser diferente da classificação de origem legítima. Em geral, o ataque envolve a injeção do ruído aleatoriamente nos dados de origem que estão sendo classificados para reduzir a probabilidade de a classificação correta ser usada no futuro [3].
Exemplos
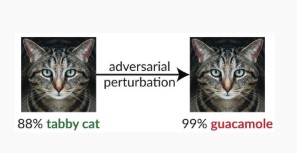
Mitigações
Igual à variante 1a.
Paralelos tradicionais
Negação de serviço não persistente
Severidade
Importante
Variante nº 1d: redução da confiança
Um invasor pode criar entradas para reduzir o nível de confiança da classificação correta, especificamente em cenários de alta consequência. Essa ação também pode assumir a forma de um grande número de falsos positivos para sobrecarregar os administradores ou os sistemas de monitoramento com alertas fraudulentos indistinguíveis de alertas legítimos [3].
Exemplos

Mitigações
- Além das ações abordadas na variante 1a, a limitação de eventos pode ser empregada para reduzir o volume de alertas de uma única fonte.
Paralelos tradicionais
Negação de serviço não persistente
Severidade
Importante
Nº 2a Envenenamento de dados de destino
Descrição
A meta do invasor é contaminar o modelo do computador gerado na fase de treinamento, para que as previsões sobre novos dados sejam modificadas na fase de teste [1]. Em ataques por envenenamento direcionados, o invasor deseja classificar exemplos específicos incorretamente para fazer com que ações específicas sejam executadas ou omitidas.
Exemplos
O envio de software AV como malware para forçar a classificação incorreta como maliciosa e eliminar o uso de software AV direcionado nos sistemas clientes.
Mitigações
Defina sensores de anomalias para examinar a distribuição de dados diariamente e alertar sobre variações
-Verifique a variação dos dados de treinamento diariamente; use a telemetria para distorção/descompasso
Validação de entrada, limpeza e verificação de integridade
O envenenamento injeta amostras de treinamento remotos. Duas estratégias principais para combater essa ameaça:
-Limpeza/validação de dados: remova amostras de envenenamento dos dados de treinamento -Bagging para combater ataques de envenenamento [14]
-Defesa por RONI (Rejeição por impacto negativo) [15]
-Aprendizado robusto: escolha os algoritmos de aprendizado que sejam robustos na presença de amostras de envenenamento.
-Tal abordagem é descrita em [21] em que os autores abordam o problema de envenenamento de dados em duas etapas: 1) apresentando um método de fatoração de matriz robusto para recuperar o verdadeiro subespaço e 2) realizando a regressão do componente principal novo para remover instâncias de adversário, fundamentada na base recuperada na etapa (1). Elas caracterizam as condições necessárias e suficientes para recuperar com êxito o subespaço real e apresentar um limite de perda de previsão esperada em comparação à verdade.
Paralelos tradicionais
Host com cavalo de Troia pelo qual o invasor continua na rede. Os dados de treinamento ou a configuração foram comprometidos e estão sendo ingeridos/confiados para a criação do modelo.
Severidade
Crítico
Nº 2b Envenenamento de dados indiscriminado
Descrição
A meta é arruinar a qualidade/integridade do conjunto de dados que está sendo atacado. Muitos conjuntos de dados são públicos/não confiáveis/não listados; portanto, isso gera mais preocupações em relação à capacidade de identificar essas violações de integridade de dados em primeiro lugar. O treinamento sobre dados comprometidos inadvertidamente é uma situação de lixo na entrada/lixo na saída. Depois de detectada, a triagem precisa determinar a extensão dos dados que foram violados e colocar em quarentena/fazer novo treinamento.
Exemplos
Uma empresa extrai um site conhecido e confiável para obter dados futuros do setor de petróleo para treinar seus modelos. O site do provedor de dados é posteriormente comprometido por um ataque de injeção de SQL. O invasor pode envenenar o conjunto de dados, e o modelo que está sendo treinado não tem nenhuma noção de que eles foram afetados.
Mitigações
Igual à variante 2a.
Paralelos tradicionais
Negação de serviço autenticada em um ativo de alto valor
Severidade
Importante
Nº 3 Ataques de inversão do modelo
Descrição
Os recursos privados usados em modelos de machine learning podem ser recuperados [1]. Isso inclui a reconstrução de dados de treinamento privado aos quais o invasor não tem acesso. Essas ações também são conhecidas como ataques de escalada na comunidade biométrica [16, 17]. Elas são realizadas uma vez descoberta a entrada que maximiza o nível de confiança retornado, sujeito à classificação correspondente ao destino [4].
Exemplos
 [4]
[4]
Mitigações
As interfaces para modelos treinados de dados confidenciais precisam de controle de acesso forte.
Consultas de limite de taxa são permitidas pelo modelo.
Implemente portas entre usuários/chamadores e o modelo real executando a validação de entrada em todas as consultas propostas, rejeitando qualquer item que não atenda à definição do modelo de exatidão de entrada e retornando apenas a quantidade mínima de informações necessárias consideradas úteis.
Paralelos tradicionais
Divulgação de informações confidenciais direcionada e oculta
Severidade
O padrão nessa situação é de severidade importante, de acordo com a barra de bugs SDL padrão, mas os dados confidenciais ou de identificação pessoal que estão sendo extraídos aumentam essa severidade para um estado crítico.
Nº 4 Ataque de inferência de associação
Descrição
O invasor pode determinar se um determinado registro de dados faz parte ou não do conjunto de dados de treinamento do modelo [1]. Os pesquisadores foram capazes de prever o procedimento principal de um paciente (por exemplo: cirurgia pela qual o paciente passou) com base nos atributos (por exemplo: idade, sexo, hospital) [1].
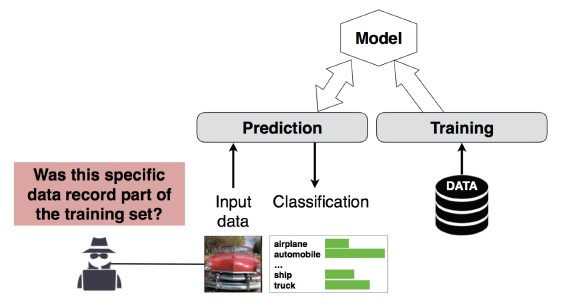 [12]
[12]
Mitigações
Os documentos de pesquisa que demonstram a viabilidade desse ataque indicam que a privacidade diferencial [4, 9] seria uma mitigação eficaz. Isso ainda é um campo recente na Microsoft, e a AETHER Security Engineering recomenda a o desenvolvimento da especialização com investimentos de pesquisa nesse espaço. Essa pesquisa precisaria enumerar recursos de privacidade diferenciais e avaliar sua eficácia prática como mitigações e, em seguida, formas de design para essas defesas serem herdadas de modo transparente em nossas plataformas de serviços online, em um processo semelhante ao modo como a compilação de código no Visual Studio oferece proteções de segurança por padrão, que são transparentes para o desenvolvedor e os usuários.
O desligamento de neurônio e a pilha de modelos podem ser mitigações efetivas até certo ponto. O desligamento de neurônio não apenas aumenta a resiliência de uma rede neural a esse ataque, mas também aumenta o desempenho do modelo [4].
Paralelos tradicionais
Privacidade de dados. Estão sendo feitas inferências sobre a inclusão de um ponto de dados no conjunto de treinamento, mas os próprios dados de treinamento não estão sendo divulgados.
Severidade
Esse é um problema de privacidade e não de segurança. Ele é abordado na diretriz de modelagem de ameaças, pois os domínios se sobrepõem, mas qualquer resposta aqui seria orientada pela privacidade, não pela segurança.
Nº 5 Roubo de modelo
Descrição
Os invasores recriam o modelo subjacente consultando legitimamente o modelo. A funcionalidade do novo modelo é a mesma do modelo subjacente [1]. Depois que o modelo é recriado, ele pode ser invertido para recuperar informações de recursos ou fazer inferências sobre dados de treinamento.
Resolução de equações – para um modelo que retorna probabilidades de classe pela saída de API, um invasor pode criar consultas para determinar variáveis desconhecidas em um modelo.
Localização de caminho: um ataque que explora as particularidades da API para extrair as "decisões" tomadas por uma árvore ao classificar uma entrada [7].
Ataque de capacidade de transferência: um adversário pode treinar um modelo local, possivelmente emitindo consultas de previsão para o modelo de destino, e usá-lo para criar exemplos de adversário que são transferidos para o modelo de destino [8]. Se seu modelo for extraído e estiver vulnerável a um tipo de entrada de adversário, novos ataques contra o modelo implantado de produção poderão ser desenvolvidos totalmente offline pelo invasor que extraiu uma cópia do modelo.
Exemplos
Em configurações em que um modelo de ML serve para detectar o comportamento do adversário, como identificação de spam, classificação de malware e detecção de anomalias de rede, a extração de modelo pode facilitar ataques de evasão [7].
Mitigações
Ações proativas/de proteção
Minimize ou oculte os detalhes retornados em APIs de previsão e, ao mesmo tempo, mantenha sua utilidade para aplicativos "honestos" [7].
Defina uma consulta bem formada para suas entradas de modelo e retorne apenas os resultados em resposta às entradas concluídas e bem formadas correspondentes a esse formato.
Retorne valores de confiança arredondados. Os autores de chamada mais legítimos não precisam de várias casas decimais de precisão.
Paralelos tradicionais
A violação de dados do sistema não autenticada, somente leitura, busca a divulgação de informações confidenciais de alto valor?
Severidade
Importante em modelos com detecção de segurança; moderado nos outros casos.
Nº 6 Reprogramação de rede neural
Descrição
Por meio de uma consulta especial criada com base em um adversário, os sistemas de Machine Learning podem ser reprogramados para uma tarefa que se desvia da intenção original do criador [1].
Exemplos
Controles de acesso fracos em uma API de reconhecimento facial, que permitem a terceiros incorporar aplicativos criados para danificar os clientes da Microsoft, como um gerador de falsificações detalhadas.
Mitigações
A autenticação cliente<->servidor mútua e forte e o controle de acesso para interfaces de modelo
Remoção das contas de invasores
Identificar e aplicar um contrato de nível de serviço às suas APIs, determinando o tempo de correção aceitável para um problema depois de reportado, e garantir a não reprodução do problema quando o SLA expirar
Paralelos tradicionais
Esse é um cenário de abuso. É menos provável que você abra um incidente de segurança sobre isso em vez de simplesmente desabilitar a conta do invasor.
Severidade
Importante a crítico
Nº 7 Exemplo de adversário no domínio físico (bits->átomos)
Descrição
Um exemplo de adversário é uma entrada/consulta de uma entidade mal-intencionada enviada com o único objetivo de enganar o sistema de aprendizado de máquina [1]
Exemplos
Esses exemplos podem ser manifestados no domínio físico, como um carro autônomo sendo induzido a ignorar um sinal de parada devido a uma determinada cor de luz (a entrada de adversário) no sinal, forçando o sistema de reconhecimento de imagem a não ver mais o sinal como indicador de parada.
Paralelos tradicionais
Elevação de privilégio, execução de código remota
Mitigações
Esses ataques se manifestam porque os problemas na camada de Machine Learning (a camada de dados e algoritmo por trás da tomada de decisões orientada por IA) não foram mitigados. Assim como acontece com qualquer outro software *ou* sistema físico, a camada abaixo do alvo sempre pode ser atacada por meio de vetores tradicionais. Assim, as práticas de segurança tradicionais são mais importantes do que nunca, especialmente com a camada de vulnerabilidades não atenuadas (a camada de dados/algoritmo) usada entre a IA e o software tradicional.
Severidade
Crítico
Nº 8 Provedores do ML mal-intencionados que podem recuperar dados de treinamento
Descrição
Um provedor mal-intencionado apresenta um algoritmo com backdoor, no qual os dados de treinamento privado são recuperados. Eles conseguiram reconstruir rostos e textos, considerando apenas o modelo.
Paralelos tradicionais
Divulgação de informações confidenciais direcionada
Mitigações
Os documentos de pesquisa que demonstram a viabilidade desse ataque indicam que a Criptografia homomórfica seria uma mitigação eficaz. Essa é uma área com poucos investimentos atualmente na Microsoft, e a AETHER Security Engineering recomenda a inclusão de especialistas com investimentos de pesquisa nesse espaço. Essa pesquisa precisaria enumerar as filosofias de criptografia homomórfica e avaliar sua eficácia prática como mitigações diante de provedores de ML como serviço mal-intencionados.
Severidade
Importante se os dados forem PII; moderada nos outros casos.
Nº 9 Ataque à cadeia de suprimentos de ML
Descrição
Devido a recursos grandes (dados + computação) necessários para treinar algoritmos, a prática atual é reutilizar modelos treinados por grandes empresas e modificá-los um pouco para a tarefa em questão (por exemplo: ResNet é um modelo de reconhecimento de imagem popular da Microsoft). Esses modelos são coletados no Model Zoo (o Caffe hospeda modelos populares de reconhecimento de imagem). Nesse ataque, o adversário ataca os modelos hospedados no Caffe, o que, portanto, envenena para qualquer outra pessoa. [1]
Paralelos tradicionais
Comprometimento de dependências não relacionadas à segurança de terceiros
App Store que hospeda malware sem saber
Mitigações
Minimize dependências de terceiros para modelos e dados sempre que possível.
Incorpore essas dependências ao processo de modelagem de ameaças.
Aproveite a autenticação forte, o controle de acesso e a criptografia entre sistemas primários/de terceiros.
Severidade
Crítico
Nº 10 Aprendizado de máquina de backdoor
Descrição
O processo de treinamento é terceirizado para um indivíduo mal-intencionado que viola dados de treinamento e fornece um modelo de cavalo de Troia para forçar classificações incorretas de destino, como a de um determinado vírus como não mal-intencionado [1]. Isso é um risco em cenários de geração de modelos de ML como serviço.
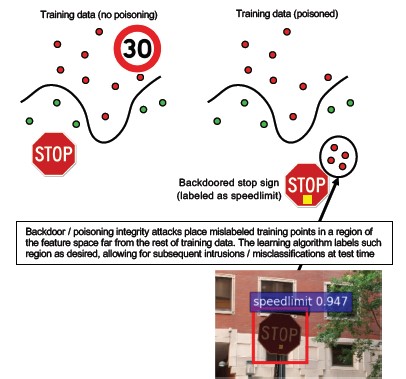 [12]
[12]
Paralelos tradicionais
Comprometimento de dependências de segurança de terceiros
Mecanismo de atualização de software comprometido
Comprometimento da autoridade de certificação
Mitigações
Ações de detecção reativas/defensivas
- O dano já foi feito após a descoberta dessa ameaça, portanto, o modelo e os dados de treinamento fornecidos pelo provedor mal-intencionado não podem ser confiáveis.
Ações proativas/de proteção
Treine todos os modelos confidenciais internamente
Catalogue dados de treinamento ou garanta que estes venham de terceiros confiáveis com práticas de segurança fortes
Modelo de ameaça da interação entre o provedor de MLaaS e seus próprios sistemas
Ações de resposta
- O mesmo que para o comprometimento da dependência externa
Severidade
Crítico
Nº 11 Explorar dependências do software do sistema de ML
Descrição
Nesse ataque, o invasor NÃO manipula os algoritmos. Em vez disso, explora vulnerabilidades de software, como estouros de buffer ou scripts entre sites. Ainda é mais fácil comprometer camadas de software abaixo da IA/ML do que atacar a camada de aprendizado diretamente, portanto, as práticas de mitigação de ameaças de segurança tradicionais detalhadas no ciclo de vida do desenvolvimento da segurança são essenciais.
Paralelos tradicionais
Dependência de software livre comprometido
Vulnerabilidade do servidor Web (XSS, CSRF, falha na validação da entrada da API)
Mitigações
Trabalhe com a equipe de segurança para seguir as melhores práticas do ciclo de vida de desenvolvimento de segurança/garantia de segurança operacional.
Severidade
Variável, até crítica, dependendo do tipo de vulnerabilidade de software tradicional.
Bibliografia
[1] Failure Modes in Machine Learning (Modos de falha em aprendizado de máquina, em tradução livre), Ram Shankar Siva Kumar, David O’ Brien, Kendra Albert, Salome Viljoen e Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] Fluxo de trabalho da AETHER Security Engineering, proveniência dos dados/equipe-v de linhagem
[3] Adversarial Examples in Deep Learning: Characterization and Divergence, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf (Exemplos de adversários no aprendizado profundo: caracterização e divergência, em tradução livre)
[4] ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf (ML-Leaks: ataques e defesas de inferência de associação independente de modelo e dados em modelos de machine learning, em tradução livre)
[5] M. Fredrikson, S. Jha e T. Ristenpart, "Ataques de inversão de modelo que exploram informações confidenciais e medidas básicas", em procedimentos da Conferência do ACM SIGSAC de 2015 sobre CCS (Segurança de computador e comunicação).
[6] Nicolas Papernot e Patrick McDaniel- Exemplos de adversários no Machine Learning AIWTB 2017
[7] Roubo de modelos de Machine Learning por APIs de previsão, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina em Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] O espaço de exemplos de adversário transferível, Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh e Patrick McDaniel
[9] Reconhecimento das inferências de associação em modelos de aprendizado bem generalizados Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 e Kai Chen3,4
[10] Simon-Gabriel et al., Vulnerabilidade de adversários das redes neurais aumenta com a dimensão de entrada, ArXiv 2018;
[11] Lyu et al., Uma família de regularização de gradiente unificada para exemplos de adversários, ICDM 2015
[12] Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning — NeCS 2019 Battista Biggioa, Fabio Roli (Dez anos após o surgimento do aprendizado de máquina de adversários — NeCS 2019 Battista Biggioa, Fabio Roli, em tradução livre)
[13] Detecção de malware robusto contra adversários usando classificação monotônica Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto e Fabio Roli. Classificadores de bagging para combater ataques de envenenamento em tarefas de classificação de adversário
[15] An Improved Reject on Negative Impact Defense Hongjiang Li and Patrick P.K. Chan (Uma rejeição aprimorada de proteção de impacto negativo, em tradução livre)
[16] Adler. Vulnerabilidades em sistemas de criptografia biométricos. 5ª Conf. Int. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Sobre a vulnerabilidade de sistemas de verificação facial para ataques de escalada. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. (Detecção de exemplos de adversários em redes neurais profundas). Simpósio de segurança de rede e do sistema distribuído de 2018. 18 a 21 de fevereiro.
[19] Reforço da robustez de adversário usando a confiança do modelo induzida por treinamento de adversário — Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Análise de causa orientada por atribuição para detecção de exemplos de adversários, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Regressão linear robusta em relação ao envenenamento de dados de treinamento – Chang Liu et al.
[22] Recurso de cancelamento de ruído para melhorar a robustez a adversários, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Defesas certificadas contra exemplos de adversários — Aditi Raghunathan, Jacob Steinhardt, Percy Liang