Saiba mais e crie regras de qualidade de dados
A qualidade dos dados é a medição da integridade dos dados numa organização e é avaliada através de classificações de qualidade de dados. Pontuações geradas com base na avaliação dos dados relativamente às regras definidas no Catálogo unificado do Microsoft Purview.
As regras de qualidade dos dados são diretrizes essenciais que as organizações estabelecem para garantir a exatidão, consistência e integridade dos dados. Estas regras ajudam a manter a integridade e fiabilidade dos dados.
Seguem-se alguns aspetos fundamentais das regras de qualidade dos dados:
Precisão – os dados devem representar com precisão entidades do mundo real. O contexto é importante! Por exemplo, se estiver a armazenar endereços de clientes, certifique-se de que correspondem às localizações reais.
Conclusão – o objetivo desta regra é identificar os dados vazios, nulos ou em falta. Esta regra valida que todos os valores estão presentes (embora não necessariamente corretos).
Conformidade – esta regra garante que os dados seguem padrões de formatação de dados, como a representação de datas, endereços e valores permitidos.
Consistência – esta regra verifica se diferentes valores do mesmo registo estão em conformidade com uma determinada regra e não existem contradições. A consistência dos dados garante que as mesmas informações são representadas uniformemente em registos diferentes. Por exemplo, se tiver um catálogo de produtos, os nomes e descrições de produtos consistentes são cruciais.
Linha cronológica – esta regra tem como objetivo garantir que os dados estão acessíveis no mais curto espaço de tempo possível. Garante que os dados estão atualizados.
Exclusividade – esta regra verifica se os valores não são duplicados, por exemplo, se for suposto existir apenas um registo por cliente, não existem vários registos para o mesmo cliente. Cada cliente, produto ou transação deve ter um identificador exclusivo.
Ciclo de vida da qualidade de dados
A criação de regras de qualidade de dados é o sexto passo no ciclo de vida da qualidade de dados. Os passos anteriores são:
- Atribua permissões de administrador de qualidade de dados aos utilizadores no Catálogo unificado para utilizar todas as funcionalidades de qualidade de dados.
- Registe e analise uma origem de dados no seu Mapa de Dados do Microsoft Purview.
- Adicionar o recurso de dados a um produto de dados
- Configure uma ligação de origem de dados para preparar a sua origem para a avaliação da qualidade dos dados.
- Configure e execute a criação de perfis de dados para um recurso na sua origem de dados.
Funções necessárias
- Para criar e gerir regras de qualidade de dados, os seus utilizadores têm de ter a função de responsável pela qualidade dos dados.
- Para ver as regras de qualidade existentes, os seus utilizadores têm de estar na função de leitor de qualidade de dados.
Ver regras de qualidade de dados existentes
Em Catálogo unificado do Microsoft Purview, selecione o menu Gestão do Estado de Funcionamento e o submenu Qualidade dos dados.
No submenu de qualidade dos dados, selecione um domínio de governação.
Selecione um produto de dados.
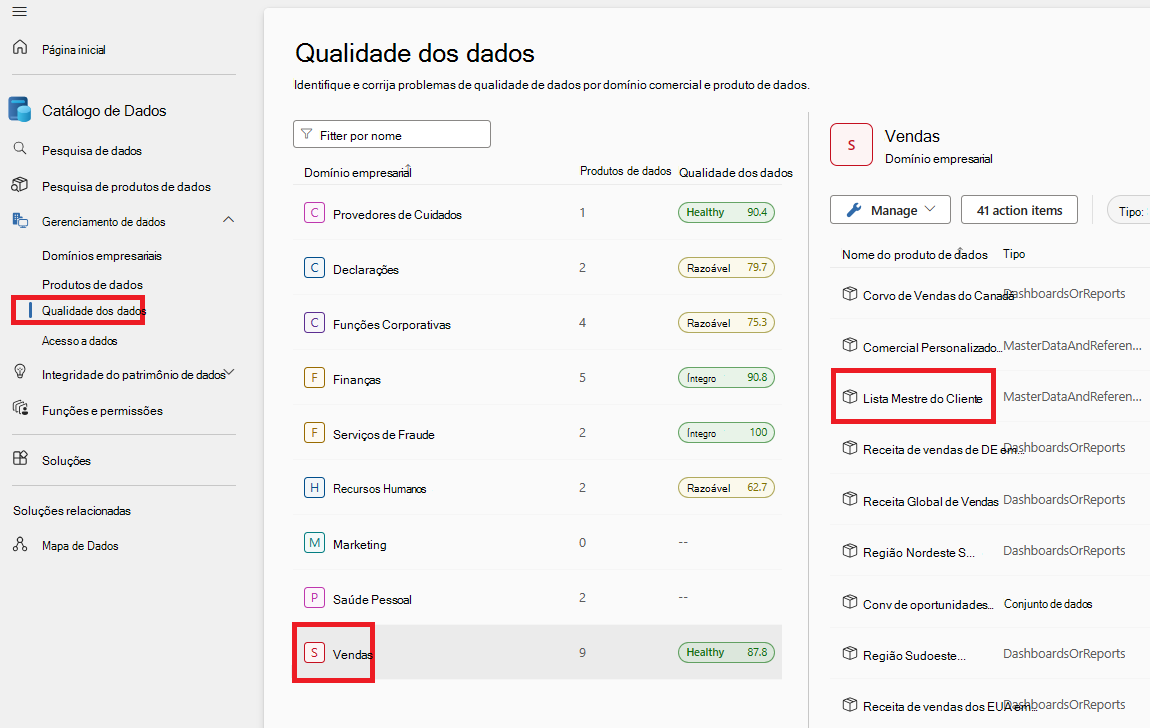
Selecione um recurso de dados na lista de recursos do produto de dados selecionado.
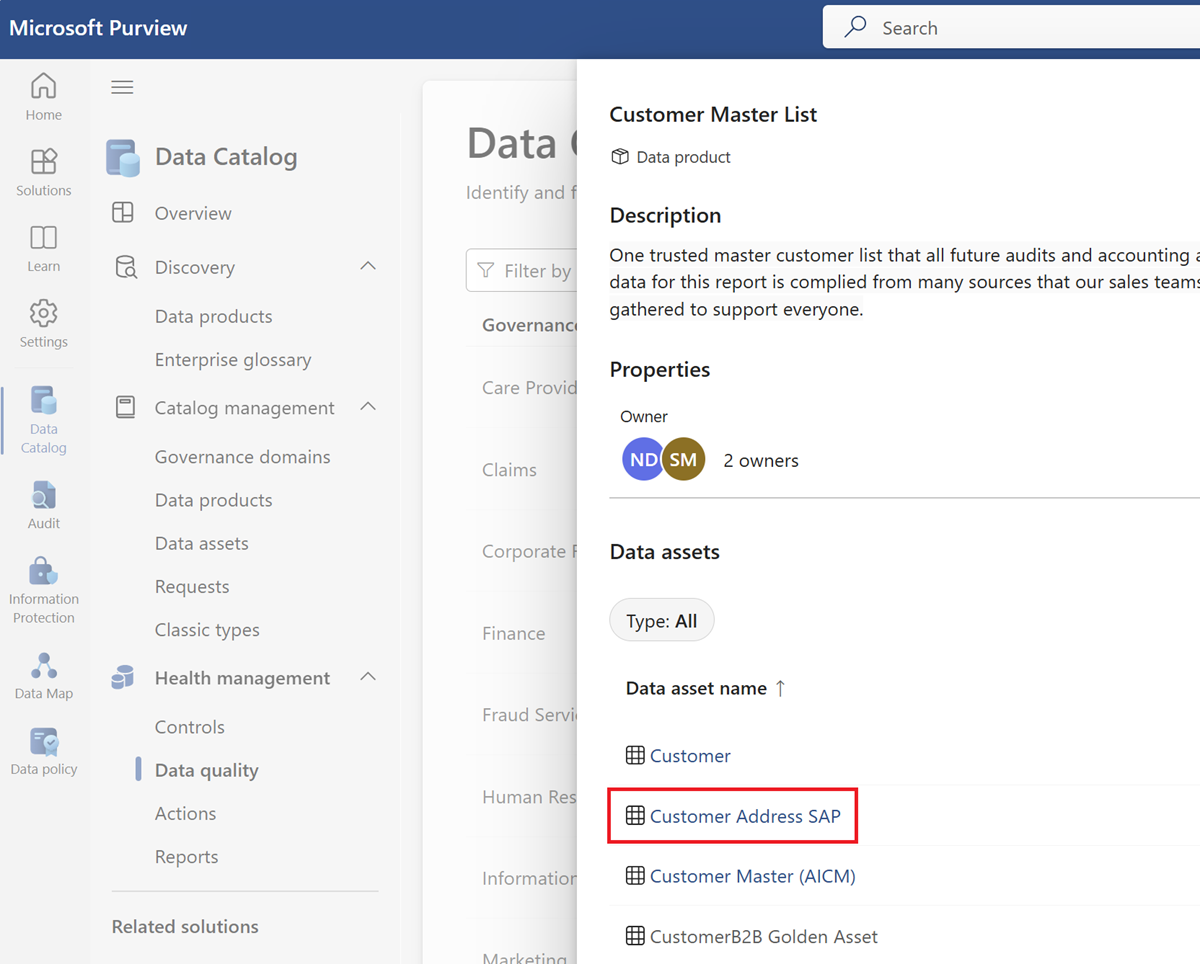
Selecione o separador de menu Regras para ver as regras existentes aplicadas ao recurso.
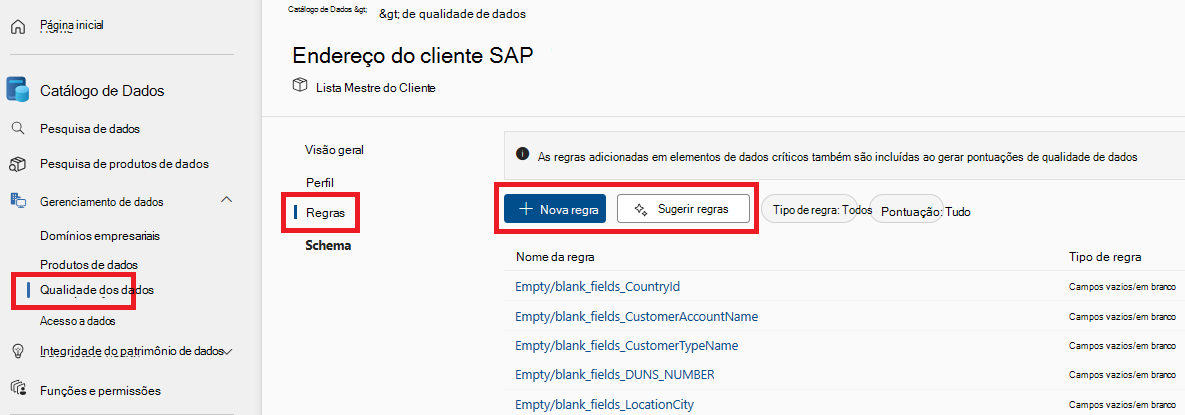
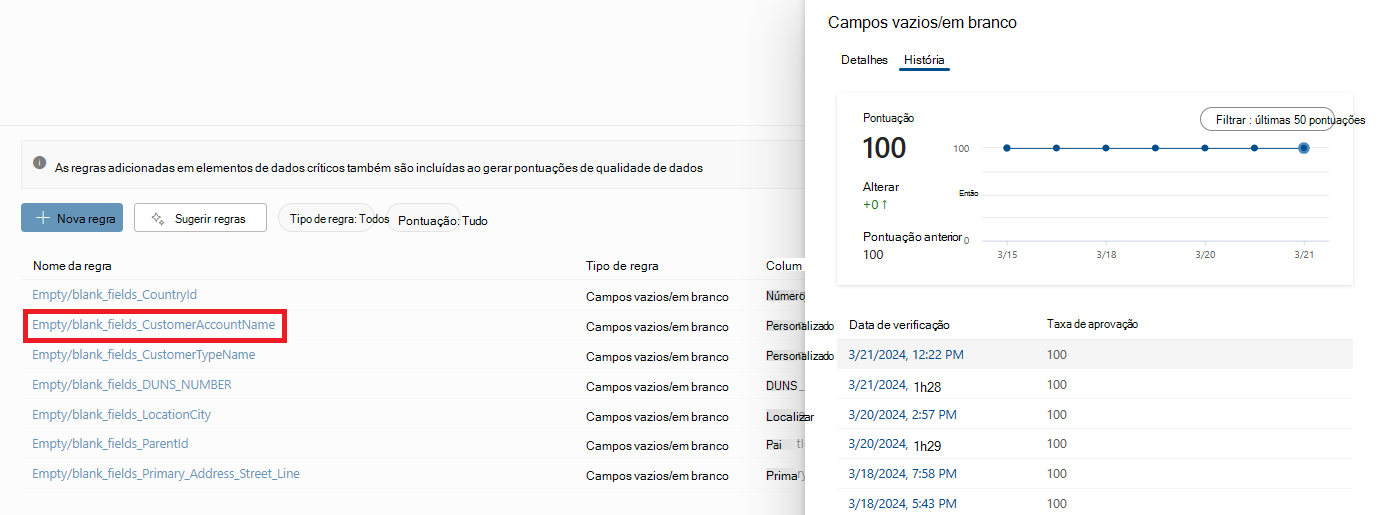
Selecione uma regra para navegar no histórico de desempenho da regra aplicada para o recurso de dados selecionado.




Regras de qualidade de dados disponíveis
Qualidade de Dados do Microsoft Purview ativa a configuração das regras abaixo, estas são regras de configuração inicial que oferecem uma forma de código baixo para não código para medir a qualidade dos seus dados.
| Regra | Definição |
|---|---|
| Atualização | Confirma que todos os valores estão atualizados. |
| Valores exclusivos | Confirma que os valores numa coluna são exclusivos. |
| Correspondência de formato de cadeia | Confirma que os valores numa coluna correspondem a um formato específico ou a outros critérios. |
| Correspondência do tipo de dados | Confirma que os valores numa coluna correspondem aos respetivos requisitos de tipo de dados. |
| Duplicar linhas | Verifica a existência de linhas duplicadas com os mesmos valores em duas ou mais colunas. |
| Campos vazios/em branco | Procura campos em branco e vazios numa coluna onde devem existir valores. |
| Pesquisa de tabelas | Confirma que um valor numa tabela pode ser encontrado na coluna específica de outra tabela. |
| Personalizados | Crie uma regra personalizada com o construtor de expressões visuais. |
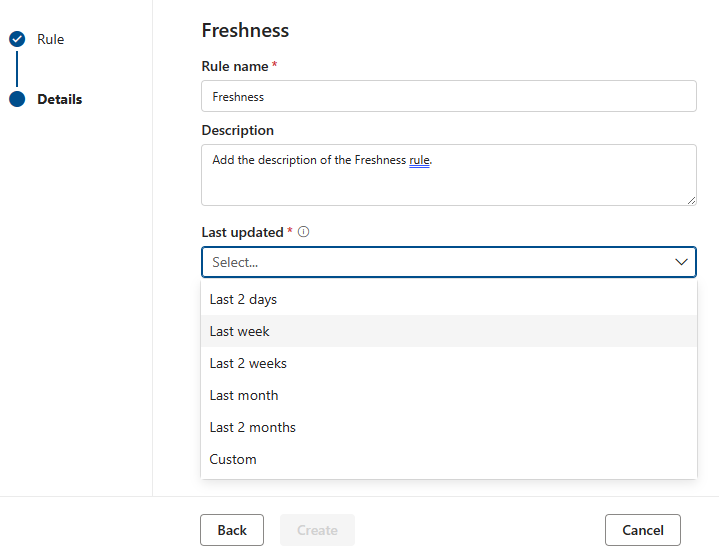
Atualização
O objetivo da regra de atualização é determinar se o recurso foi atualizado dentro do tempo esperado. Atualmente, o Microsoft Purview suporta a verificação da atualização ao consultar as datas da última modificação.
Observação
A classificação para a regra de atualização é 100 (passou) ou 0 (falhou). A regra de atualização não é suportada para Snowflake, Azure Databricks UC, Google BigQuery, Synapes e SQL do Azure.
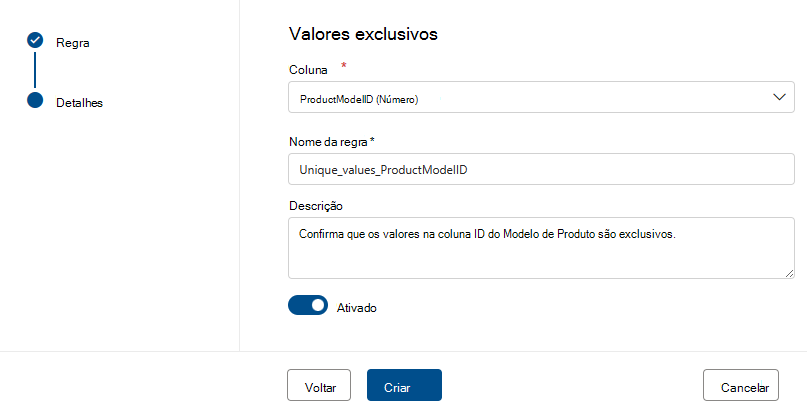
Valores exclusivos
A regra Valores exclusivos indica que todos os valores na coluna especificada têm de ser exclusivos. Todos os valores que são exclusivos "pass" e aqueles que não são tratados como falha. Se a regra Campos vazios/em branco não estiver definida na coluna, os valores nulos/vazios serão ignorados para efeitos desta regra.
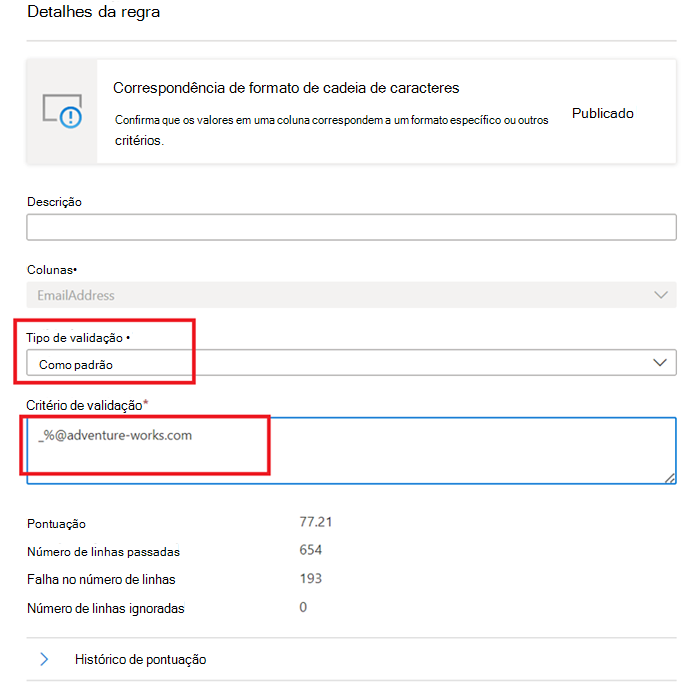
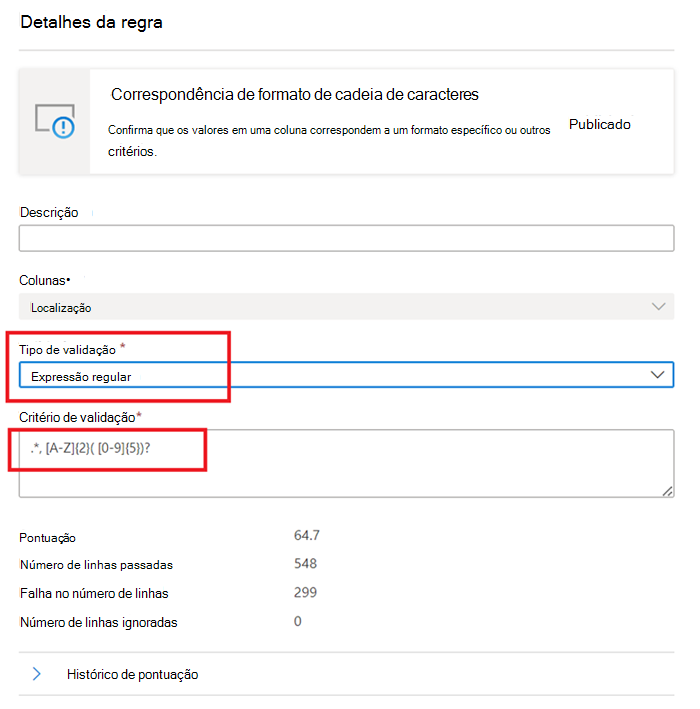
Correspondência de formato de cadeia
A regra De correspondência de formato verifica se todos os valores na coluna são válidos. Se a regra Campos vazios/em branco não estiver definida numa coluna, os valores nulos/vazios serão ignorados para efeitos desta regra.
Esta regra pode validar cada valor na coluna com três abordagens diferentes:
Enumeração – esta é uma lista de valores separada por vírgulas. Se o valor a ser avaliado não puder ser comparado a um dos valores listados, a marcar falha. É possível escapar vírgulas e barras invertidas com uma barra invertida:
\. Portanto,a \, b, ccontém dois valores que o primeiro éa , be o segundo éc.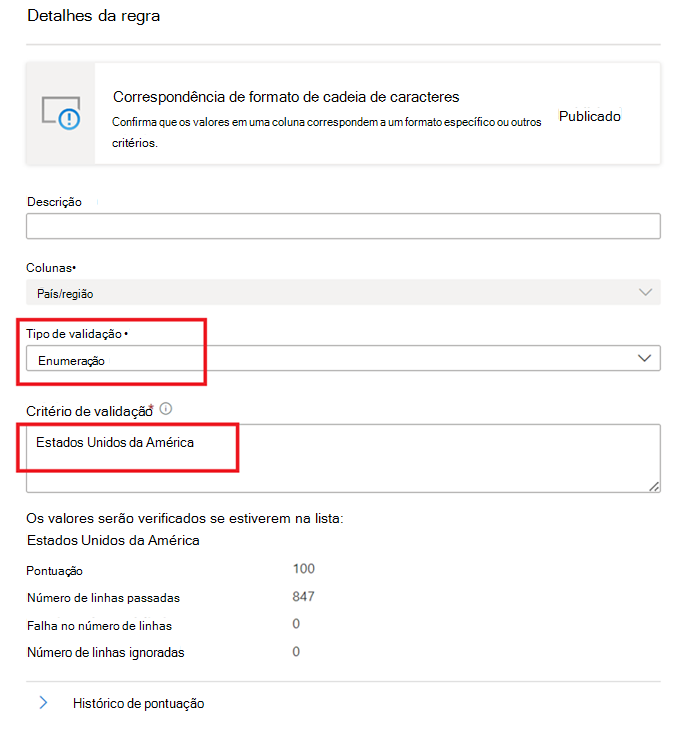
Padrão Like -
like(<string> : string, <pattern match> : string) => boolean
O padrão é uma cadeia que corresponde literalmente. As exceções são os seguintes símbolos especiais: _ corresponde a qualquer caráter na entrada (semelhante a . emposixexpressões regulares) % corresponde a zero ou mais carateres na entrada (semelhante a .* emposixexpressões regulares). O caráter de fuga é "". Se um caráter de escape preceder um símbolo especial ou outro caráter de escape, o caráter seguinte será literalmente correspondido. É inválido escapar a qualquer outro caráter.like('icecream', 'ice%') -> true
Expressão Regular –
regexMatch(<string> : string, <regex to match> : string) => boolean
Verifica se a cadeia corresponde ao padrão regex especificado. Utilize<regex>(aspas anteriores) para corresponder a uma cadeia sem escapar.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
Correspondência do tipo de dados
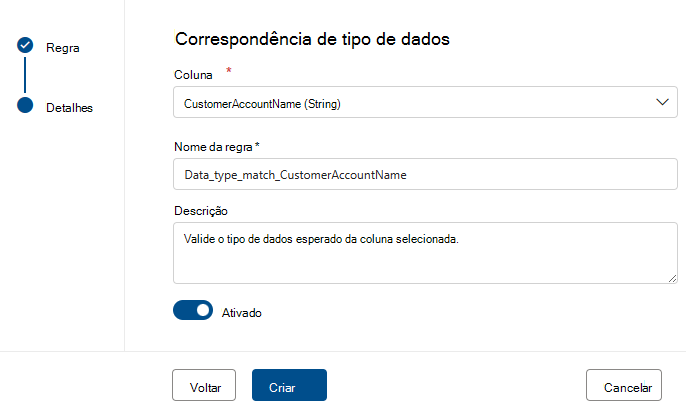
A regra De tipo de dados corresponde especifica o tipo de dados que a coluna associada deverá conter. Uma vez que o motor de regras tem de ser executado em várias origens de dados diferentes, não pode utilizar tipos nativos como BIGINT ou VARCHAR. Em vez disso, tem o seu próprio sistema de tipo para o qual traduz os tipos nativos. Esta regra indica ao motor de análise de qualidade para qual dos tipos incorporados o tipo nativo deve ser traduzido. O sistema de tipo de dados é retirado do sistema de tipo Fluxo de Dados do Azure utilizado no Azure Data Factory.
Durante uma análise de qualidade, todos os tipos nativos serão testados em relação ao tipo de correspondência de tipo de dados e, se não for possível traduzir o tipo nativo para o tipo de correspondência de tipo de dados, essa linha será tratada como estando em erro.
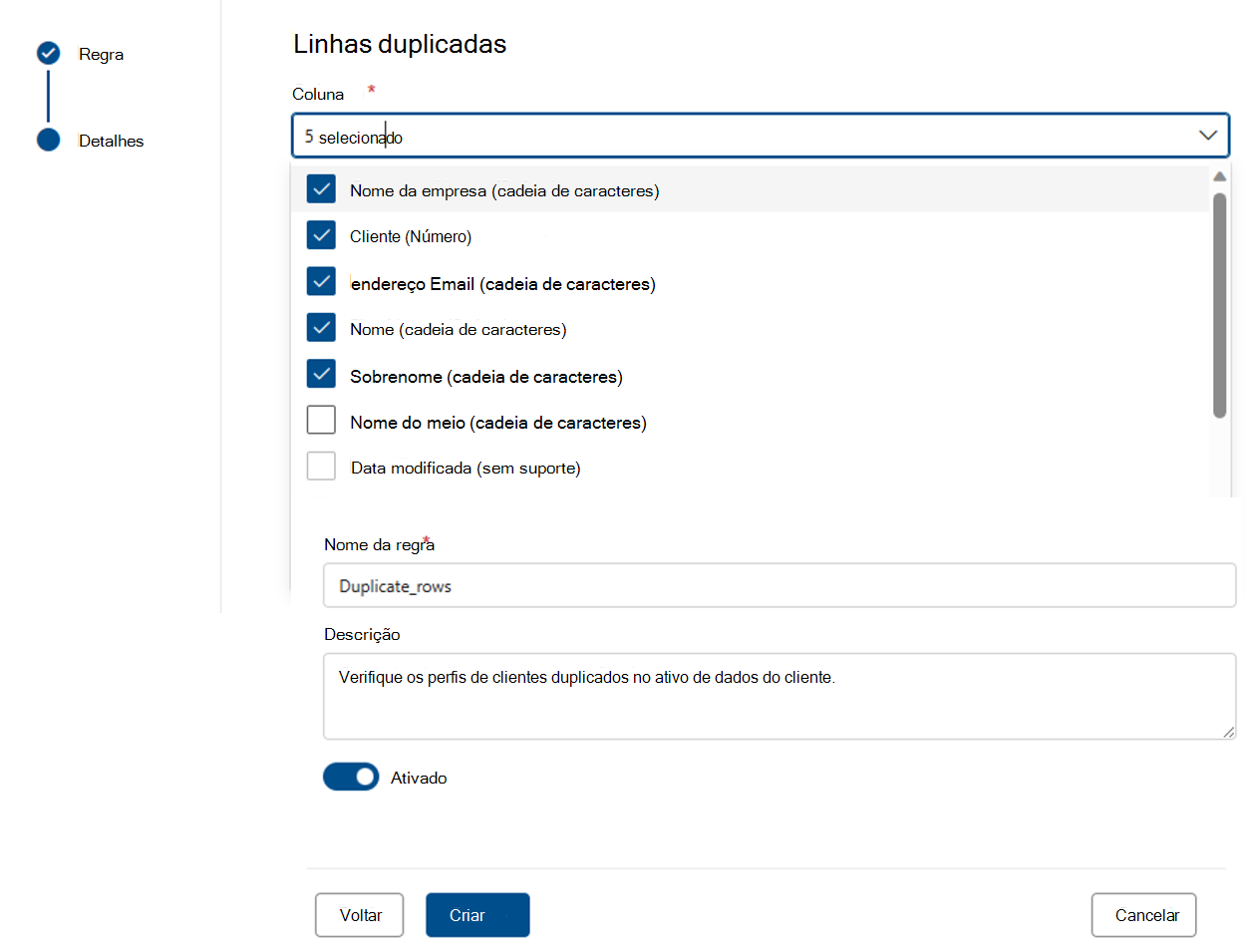
Duplicar linhas
A regra Linhas duplicadas verifica se a combinação dos valores na coluna é exclusiva para cada linha na tabela.
No exemplo abaixo, a expectativa é que a concatenação de _CompanyName, CustomerID, EmailAddress, FirstName e LastName produza um valor exclusivo para todas as linhas na tabela.
Cada recurso pode ter zero ou uma instância desta regra.
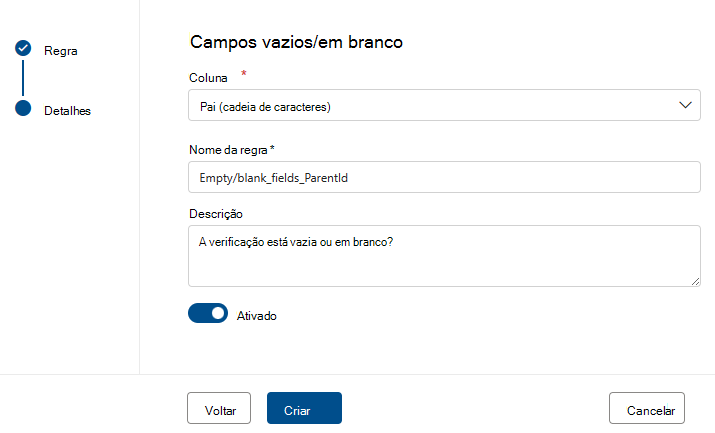
Campos vazios/em branco
A regra Campos vazios/em branco afirma que as colunas identificadas não devem conter quaisquer valores nulos e, no caso específico das cadeias, nenhum valor vazio ou apenas de espaço em branco. Durante uma análise de qualidade, qualquer valor nesta coluna que não seja nulo será tratado como correto. Esta regra afetará outras regras, como valores exclusivos ou Regras de correspondência de formato . Se esta regra não estiver definida numa coluna, essas regras quando executadas nessa coluna ignorarão automaticamente quaisquer valores nulos. Se esta regra estiver definida numa coluna, essas regras irão examinar valores nulos/vazios nessa coluna e considerá-los para efeitos de classificação.
Pesquisa de tabelas
A regra de Pesquisa de Tabela examinará cada valor na coluna na qual a regra está definida e compará-la-á com uma tabela de referência. Por exemplo, a tabela primária tem uma coluna denominada "localização" que contém cidades, estados e códigos postais na forma "cidade, distrito zip". Existe uma tabela de referência, denominada citystate, que contém todas as combinações legais de cidades, estados e códigos postais suportados no Estados Unidos. O objetivo é comparar todas as localizações na coluna atual com essa lista de referência para garantir que apenas estão a ser utilizadas combinações legais.
Para tal, primeiro escrevemos o "nome de citystatezip na caixa de diálogo de recursos de pesquisa. Em seguida, selecionamos o elemento pretendido e, em seguida, a coluna com que queremos comparar.
Observação
A tabela de referência ou o recurso de dados tem de pertencer ao mesmo domínio de governação. Não é permitido comparar um recurso de dados em diferentes domínios de governação.
Regras personalizadas
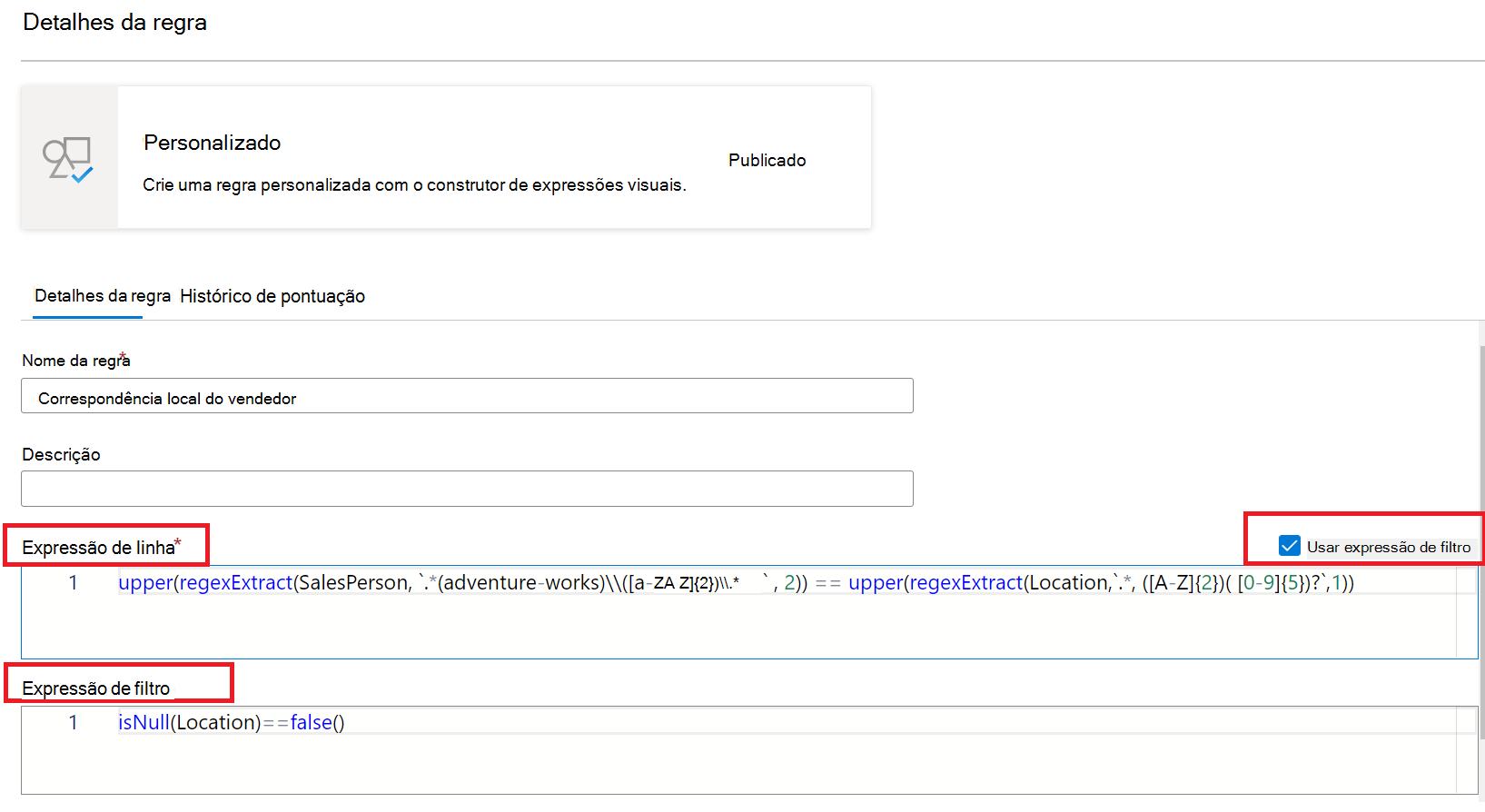
A regra Personalizada permite especificar regras que tentam validar linhas com base num ou mais valores nessa linha. A regra personalizada tem duas partes:
- A primeira parte é a expressão de filtro que é opcional e é ativada ao selecionar a caixa marcar por "Utilizar expressão de filtro". Esta é uma expressão que devolve um valor Booleano. A expressão de filtro será aplicada a uma linha e, se devolver verdadeiro, essa linha será considerada para a regra. Se a expressão de filtro devolver falso para essa linha, significa que a linha será ignorada para efeitos desta regra. O comportamento predefinido da expressão de filtro é transmitir todas as linhas, por isso, se não for especificada nenhuma expressão de filtro e não for necessária uma, todas as linhas serão consideradas.
- A segunda parte é a expressão de linha. Esta é uma expressão booleana aplicada a cada linha que é aprovada pela expressão de filtro. Se esta expressão devolver verdadeiro, a linha passa, se for falsa, é marcada como uma falha.
Exemplos de regras personalizadas
| Cenário | Expressão de linha |
|---|---|
| Valide se state_id é igual à Califórnia e aba_Routing_Number corresponde a um determinado padrão regex e a data de nascimento cai num determinado intervalo | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Verifique se VendorID é igual a 124 | {VendorID}=='124' |
| Verificar se fare_amount é igual ou superior a 100 | {fare_amount} >= "100" |
| Valide se fare_amount é superior a 100 e tolls_amount não é igual a 100 | {fare_amount} >= "100" || {tolls_amount} != "400" |
| Verificar se Classificação é inferior a 5 | Rating < 5 |
| Verificar se o número de dígitos no ano é 4 | length(toString(year)) == 4 |
| Comparar duas colunas bbToLoanRatio e bankBalance com marcar se os respetivos valores forem iguais | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Verifique se o número de carateres cortado e concatenado em firstName, lastName, LoanID, uuid é superior a 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Verifique se aba_Routing_Number corresponde a determinado padrão regex e se a data de transação inicial é maior do que 2022-11-12 e Se não for permitida é falsa e se a média de bankBalance é superior a 50000 e state_id é igual a 'Massachuse', 'Tennessee', 'Dakota do Norte' ou 'Albama' | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| Valide se aba_Routing_Number corresponde a determinado padrão regex e dateOfBirth está entre 1968-12-13 e 2020-12-13 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Verifique se o número de valores exclusivos no aba_Routing_Number é igual a 1000 000 e se o número de valores exclusivos no EMAIL_ADDR é igual a 1000 000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
A expressão de filtro e a expressão de linha são definidas com a linguagem de expressão Azure Data Factory, conforme apresentado aqui com o idioma definido aqui. No entanto, tenha em atenção que nem todas as funções definidas para a linguagem de expressão genérica do ADF estão disponíveis. A lista completa de funções disponíveis está na lista Funções disponível na caixa de diálogo de expressão. As seguintes funções definidas aqui não são suportadas: isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, pesquisa em cache e funções window.
Observação
<regex> (backquote) pode ser utilizado em expressões regulares incluídas em regras personalizadas para corresponder a cadeia sem escapar a carateres especiais. A linguagem de expressão regular baseia-se em Java e funciona conforme indicado aqui.
Esta página identifica os carateres que precisam de ser escapados.
Regras geradas automaticamente assistidas por IA
A geração de regras automatizadas assistidas por IA para medição da qualidade dos dados envolve a utilização de técnicas de inteligência artificial (IA) para criar automaticamente regras para avaliar e melhorar a qualidade dos dados. As regras geradas automaticamente são específicas do conteúdo. A maioria das regras comuns será gerada automaticamente para que os utilizadores não precisem de fazer tanto esforço para criar regras personalizadas.
Para navegar e aplicar regras geradas automaticamente:
- Selecione Sugerir regras na página de regras.
- Procure as regras sugeridas na lista.

- Selecione regras na lista de regras sugeridas para aplicar ao recurso de dados.

Próximas etapas
- Configure e execute uma análise de qualidade de dados num produto de dados para avaliar a qualidade de todos os recursos suportados no produto de dados.
- Reveja os resultados da análise para avaliar a qualidade atual dos dados do produto de dados.