Detecção de objetos usando Fast R-CNN
Sumário
- Resumo
- Instalação
- Executar o exemplo de toy
- Treinar dados do Pascal VOC
- Treinar CNTK Fast R-CNN em seus próprios dados
- Detalhes técnicos
- Detalhes do algoritmo
Resumo

Este tutorial descreve como usar o Fast R-CNN na API do CNTK Python. Fast R-CNN usando BrainScript e cnkt.exe é descrito aqui.
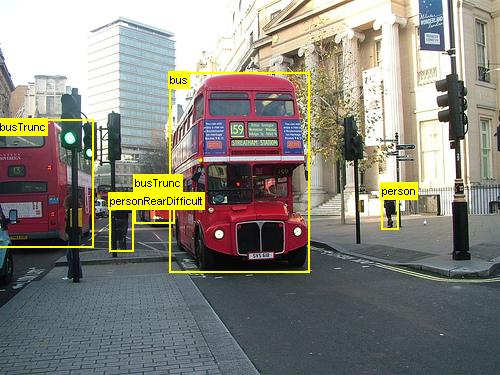
Os exemplos acima são imagens de exemplo e anotações de objeto para o conjunto de dados de supermercado (esquerda) e o conjunto de dados PASCAL VOC (direita) usado neste tutorial.
Fast R-CNN é um algoritmo de detecção de objetos proposto por Ross Girshick em 2015. O documento é aceito no ICCV 2015 e arquivado em https://arxiv.org/abs/1504.08083. O Fast R-CNN baseia-se no trabalho anterior para classificar com eficiência propostas de objeto usando redes convolucionais profundas. Em comparação com o trabalho anterior, o Fast R-CNN emprega um esquema de pooling de região de interesse que permite reutilizar os cálculos das camadas convolucionais.
Instalação
Para executar o código neste exemplo, você precisa de um ambiente do CNTK Python (consulte aqui para obter ajuda de instalação). Instale os seguintes pacotes adicionais em seu ambiente do cntk Python
pip install opencv-python easydict pyyaml dlib
Binários pré-compilados para regressão de caixa delimitadora e supressão não máxima
A pasta Examples\Image\Detection\utils\cython_modules contém binários pré-compilados que são necessários para executar o Fast R-CNN. As versões que estão atualmente contidas no repositório são Python 3.5 para Windows e Python 3.5, 3.6 para Linux, todos de 64 bits. Se você precisar de uma versão diferente, poderá compilá-la seguindo as etapas descritas em
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Copie os binários gerados cython_bbox e cpu_nms (e/ou gpu_nms) de $FRCN_ROOT/lib/utils para $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules.
Exemplo de dados e modelo de linha de base
Usamos um modelo AlexNet pré-treinado como base para o treinamento Fast-R-CNN (para VGG ou outros modelos base, veja Como usar um modelo de base diferente. O conjunto de dados de exemplo e o modelo AlexNet pré-treinado podem ser baixados executando o seguinte comando Python da pasta FastRCNN:
python install_data_and_model.py
- Saiba como usar um modelo de base diferente
- Saiba como executar o Fast R-CNN nos dados do Pascal VOC
- Saiba como executar o Fast R-CNN em seus próprios dados
Executar o exemplo de toy
Para treinar e avaliar a execução do Fast R-CNN
python run_fast_rcnn.py
Os resultados do treinamento com 2.000 ROIs no Supermercado usando AlexNet como modelo base devem ser semelhantes a estes:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
Para visualizar as caixas delimitadoras previstas e rótulos nas imagens, abra FastRCNN_config.py a partir da FastRCNN pasta e defina
__C.VISUALIZE_RESULTS = True
As imagens serão salvas na FastRCNN/Output/Grocery/ pasta se você executar python run_fast_rcnn.py.
Treinar no Pascal VOC
Para baixar os dados pascal e criar os arquivos de anotação para Pascal no formato CNTK, execute os seguintes scripts:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
Alterar o dataset_cfgget_configuration() método de run_fast_rcnn.py para
from utils.configs.Pascal_config import cfg as dataset_cfg
Agora você está definido para treinar os dados pascal VOC 2007 usando python run_fast_rcnn.py. Cuidado que o treinamento possa levar algum tempo.
Treinar em seus próprios dados
Preparar um conjunto de dados personalizado
Opção nº 1: Ferramenta de Marcação de Objeto Visual (recomendado)
A VOTT (Visual Object Tagging Tool) é uma ferramenta de anotação entre plataformas para marcar ativos de vídeo e imagem.

O VOTT fornece os seguintes recursos:
- Marcação assistida por computador e acompanhamento de objetos em vídeos usando o algoritmo de rastreamento do Camshift.
- Exportar marcas e ativos para o formato CNTK Fast-RCNN para treinar um modelo de detecção de objetos.
- Executar e validar um modelo de detecção de objeto CNTK treinado em novos vídeos para gerar modelos mais fortes.
Como anotar com VOTT:
- Baixar a versão mais recente
- Siga o Readme para executar um trabalho de marcação
- Depois de marcar marcas de exportação para o diretório do conjunto de dados
Opção nº 2: usando scripts de anotação
Para treinar um modelo CNTK Fast R-CNN em seu próprio conjunto de dados, fornecemos dois scripts para anotar regiões retangulares em imagens e atribuir rótulos a essas regiões.
Os scripts armazenarão as anotações no formato correto, conforme exigido pela primeira etapa de execução do Fast R-CNN (A1_GenerateInputROIs.py).
Primeiro, armazene suas imagens na estrutura de pastas a seguir
<your_image_folder>/negative- imagens usadas para treinamento que não contêm objetos<your_image_folder>/positive- imagens usadas para treinamento que contêm objetos<your_image_folder>/testImages- imagens usadas para testes que contêm objetos
Para as imagens negativas, você não precisa criar anotações. Para as outras duas pastas, use os scripts fornecidos:
- Execute
C1_DrawBboxesOnImages.pypara desenhar caixas delimitadoras nas imagens.- No conjunto
imgDir = <your_image_folder>de scripts (/positiveou/testImages) antes de executar. - Adicione anotações usando o cursor do mouse. Depois que todos os objetos em uma imagem são anotados, pressionar a tecla 'n' grava o arquivo .bboxes.txt e, em seguida, prossegue para a próxima imagem, 'u' desfaz (ou seja, remove) o último retângulo e 'q' encerra a ferramenta de anotação.
- No conjunto
- Execute
C2_AssignLabelsToBboxes.pypara atribuir rótulos às caixas delimitadoras.- No conjunto
imgDir = <your_image_folder>de scripts (/positiveou/testImages) antes de executar... - ... e adapte as classes no script para refletir suas categorias de objeto, por exemplo
classes = ("dog", "cat", "octopus"). - O script carrega esses retângulos anotados manualmente para cada imagem, exibe-os um por um e solicita que o usuário forneça a classe de objeto clicando no respectivo botão à esquerda da janela. Anotações de verdade terrestre marcadas como "indecisas" ou "excluídas" são totalmente excluídas do processamento adicional.
- No conjunto
Treinar no conjunto de dados personalizado
Depois de armazenar suas imagens na estrutura de pastas descrita e anotá-las, execute
python Examples/Image/Detection/utils/annotations/annotations_helper.py
depois de alterar a pasta nesse script para sua pasta de dados. Por fim, crie um MyDataSet_config.py na utils\configs pasta seguindo os exemplos existentes:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
Observe que __C.CNTK.PROPOSAL_LAYER_SCALES isso não é usado para Fast R-CNN, apenas para Faster R-CNN.
Para treinar e avaliar o Fast R-CNN em seus dados, altere o dataset_cfgget_configuration() método de run_fast_rcnn.py
from utils.configs.MyDataSet_config import cfg as dataset_cfg
e execute python run_fast_rcnn.py.
Detalhes técnicos
O algoritmo Fast R-CNN é explicado na seção detalhes do Algoritmo , juntamente com uma visão geral de alto nível de como ele é implementado na API do Python CNTK. Esta seção se concentra na configuração do Fast R-CNN e em como usar modelos base diferentes.
Parâmetros
Os parâmetros são agrupados em três partes:
- Parâmetros do detector (consulte
FastRCNN/FastRCNN_config.py) - Parâmetros do conjunto de dados (veja, por exemplo
utils/configs/Grocery_config.py) - Parâmetros de modelo base (veja por exemplo
utils/configs/AlexNet_config.py)
As três partes são carregadas e mescladas no get_configuration() método em run_fast_rcnn.py. Nesta seção, abordaremos os parâmetros do detector. Os parâmetros do conjunto de dados são descritos aqui, parâmetros de modelo base aqui. No seguinte, passamos pelos parâmetros mais importantes em FastRCNN_config.py. Todos os parâmetros também são comentados no arquivo. A configuração usa o EasyDict pacote que permite acesso fácil a dicionários aninhados.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
As propostas roi são computadas em tempo real na primeira época usando a implementação de pesquisa seletiva do dlib pacote. O número de propostas geradas é controlado pelo __C.NUM_ROI_PROPOSALS parâmetro. É recomendável usar cerca de 2.000 propostas. O cabeçalho de regressão só é treinado nesses ROIs que têm uma sobreposição (IoU) com uma caixa de verdade terrestre de pelo menos __C.BBOX_THRESH.
__C.INPUT_ROIS_PER_IMAGE especifica o número máximo de anotações de verdade por imagem. Atualmente, o CNTK exige definir um número máximo. Se houver menos anotações, elas serão adicionadas internamente. __C.IMAGE_WIDTH e __C.IMAGE_HEIGHT são as dimensões usadas para redimensionar e adicionar as imagens de entrada.
__C.TRAIN.USE_FLIPPED = True aumentará os dados de treinamento invertendo todas as imagens a cada outra época, ou seja, a primeira época tem todas as imagens regulares, a segunda tem todas as imagens invertidas e assim por diante. __C.TRAIN_CONV_LAYERS determina se as camadas convolucionais, desde a entrada até o mapa de recursos convolucionais, serão treinadas ou corrigidas. Corrigir os pesos da camada de conv significa que os pesos do modelo base são tomados e não modificados durante o treinamento. (Você também pode especificar quantas camadas de conv deseja treinar, consulte a seção Usando um modelo base diferente).
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD é o limite NMS usado para descartar caixas delimitadoras previstas sobrepostas na avaliação. Um limite inferior gera menos remoções e, portanto, mais caixas delimitadoras previstas na saída final. Se você definir __C.USE_PRECOMPUTED_PROPOSALS = True o leitor lerá ROIs pré-compilados de arquivos de texto. Isso é usado, por exemplo, para treinamento em dados voc pascal. Os nomes __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE de arquivo e __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE são especificados em Examples/Image/Detection/utils/configs/Pascal_config.py.
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
Os parâmetros acima estão configurando a pesquisa seletiva de dlib. Para obter detalhes, consulte a página inicial de dlib. Os parâmetros adicionais a seguir são usados para filtrar ROIs gerados w.r.t. comprimento lateral mínimo e máximo, área e proporção de aspectos.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
Se a pesquisa seletiva retornar mais ROIs do que as solicitadas, elas serão amostradas aleatoriamente. Se menos ROIs forem retornados, roIs adicionais serão gerados em uma grade regular usando o especificado __C.roi_grid_aspect_ratios.
Usando um modelo base diferente
Para usar um modelo base diferente, você precisa escolher uma configuração de modelo diferente no get_configuration() método de run_fast_rcnn.py. Dois modelos têm suporte imediatamente:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
Para baixar o modelo VGG16, use o script de download em <cntkroot>/PretrainedModels:
python download_model.py VGG16_ImageNet_Caffe
Se você quiser usar outro modelo base diferente, precisará copiar, por exemplo, o arquivo utils/configs/VGG16_config.py de configuração e modificá-lo de acordo com seu modelo base:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
Para investigar os nomes de nó do modelo base, você pode usar o plot() método de cntk.logging.graph. No momento, não há suporte para modelos ResNet, pois o pool de roi no CNTK ainda não dá suporte ao pool médio roi.
Detalhes do algoritmo
R-CNN rápido
R-CNNs for Object Detection foram apresentados pela primeira vez em 2014 por Ross Girshick et al., e foram mostrados para superar abordagens anteriores de última geração em um dos principais desafios de reconhecimento de objetos no campo: Pascal VOC. Desde então, foram publicados dois artigos de acompanhamento que contêm melhorias significativas de velocidade: Fast R-CNN e Faster R-CNN.
A ideia básica da R-CNN é pegar uma rede neural profunda que foi originalmente treinada para classificação de imagem usando milhões de imagens anotadas e modificá-la para fins de detecção de objeto. A ideia básica do primeiro artigo R-CNN é ilustrada na Figura abaixo (retirada do papel): (1) Dada uma imagem de entrada, (2) em uma primeira etapa, uma grande quantidade de propostas de região é gerada. (3) Essas propostas de região ou ROIs (Regiões de Interesses) são enviadas independentemente pela rede que gera um vetor de, por exemplo, valores de ponto flutuante de 4096 para cada ROI. Por fim, (4) aprende-se um classificador que usa a representação ROI flutuante 4096 como entrada e gera um rótulo e confiança para cada ROI.

Embora essa abordagem funcione bem em termos de precisão, é muito caro calcular, pois a Rede Neural precisa ser avaliada para cada ROI. O Fast R-CNN resolve essa desvantagem avaliando apenas a maior parte da rede (para ser específico: as camadas de convolução) uma única vez por imagem. De acordo com os autores, isso leva a uma aceleração de 213 vezes durante o teste e uma aceleração de 9x durante o treinamento sem perda de precisão. Isso é obtido usando uma camada de pool de ROI que projeta o ROI no mapa de recursos convolucionais e executa o pool máximo para gerar o tamanho de saída desejado que a camada a seguir está esperando.
No exemplo alexnet usado neste tutorial, a camada de pool de ROI é colocada entre a última camada convolucional e a primeira camada totalmente conectada. No código da API do Python do CNTK mostrado abaixo, isso é realizado clonando duas partes da rede, a conv_layers e a fc_layers. A imagem de entrada é então normalizada primeiro, enviada por push pela conv_layerscamada efc_layers, por fim, roipooling os cabeçalhos de previsão e regressão são adicionados que preveem o rótulo de classe e os coeficientes de regressão por ROI candidato, respectivamente.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
A implementação original do Caffe usada nos artigos R-CNN pode ser encontrada no GitHub: RCNN, Fast R-CNN e Faster R-CNN.
Treinamento SVM vs NN
Patrick Buehler fornece instruções sobre como treinar uma SVM na saída CNTK Fast R-CNN (usando os recursos 4096 da última camada totalmente conectada), bem como uma discussão sobre prós e contras aqui.
Pesquisa Seletiva
A Pesquisa Seletiva é um método para encontrar um grande conjunto de possíveis locais de objeto em uma imagem, independentemente da classe do objeto real. Ele funciona agrupando pixels de imagem em segmentos e executando clustering hierárquico para combinar segmentos do mesmo objeto em propostas de objeto.



Para complementar os ROIs detectados da Pesquisa Seletiva, adicionamos ROIs que cobrem uniformemente a imagem em diferentes escalas e proporções. A imagem à esquerda mostra uma saída de exemplo de Pesquisa Seletiva, em que cada local de objeto possível é visualizado por um retângulo verde. ROIs que são muito pequenos, muito grandes, etc. são descartados (meio) e, por fim, ROIs que cobrem uniformemente a imagem são adicionados (à direita). Esses retângulos são usados como ROIs (Regiões de Interesse) no pipeline R-CNN.
O objetivo da geração ROI é encontrar um pequeno conjunto de ROIs que, no entanto, cobrem o maior número possível de objetos na imagem. Essa computação deve ser suficientemente rápida e, ao mesmo tempo, encontrar locais de objeto em diferentes escalas e proporções. A Pesquisa Seletiva foi mostrada para ter um bom desempenho para essa tarefa, com boa precisão para acelerar as trocas.
NMS (supressão não máxima)
Os métodos de detecção de objetos geralmente geram várias detecções que cobrem totalmente ou parcialmente o mesmo objeto em uma imagem.
Esses ROIs precisam ser mesclados para poder contar objetos e obter seus locais exatos na imagem.
Isso é feito tradicionalmente usando uma técnica chamada NMS (Supressão Não Máxima). A versão do NMS que usamos (e que também foi usada nas publicações R-CNN) não mescla ROIs, mas tenta identificar quais ROIs melhor abrangem os locais reais de um objeto e descarta todos os outros ROIs. Isso é implementado selecionando iterativamente o ROI com maior confiança e removendo todos os outros ROIs que se sobrepõem significativamente a esse ROI e são classificados como sendo da mesma classe. O limite para a sobreposição pode ser definido em PARAMETERS.py (detalhes).
Resultados da detecção antes (esquerda) e depois (direita) Não Supressão Máxima:


mAP (precisão média média)
Depois de treinado, a qualidade do modelo pode ser medida usando critérios diferentes, como precisão, recall, precisão, área abaixo da curva etc. Uma métrica comum usada para o desafio de reconhecimento de objeto PASCAL VOC é medir a AP (Precisão Média) para cada classe. A descrição a seguir de Precisão Média é obtida de Everingham et. al. A média de precisão média (mAP) é calculada levando a média sobre os APs de todas as classes.
Para uma determinada tarefa e classe, a curva de precisão/recall é calculada a partir da saída classificada de um método. O recall é definido como a proporção de todos os exemplos positivos classificados acima de uma determinada classificação. Precisão é a proporção de todos os exemplos acima dessa classificação que são da classe positiva. A AP resume a forma da curva de precisão/recall e é definida como a precisão média em um conjunto de onze níveis de recall igualmente espaçados [0,0.1, . . . ,1]:
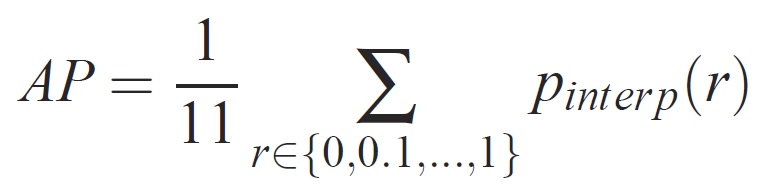
A precisão em cada nível de recall r é interpolada tomando a precisão máxima medida para um método para o qual o recall correspondente excede r:
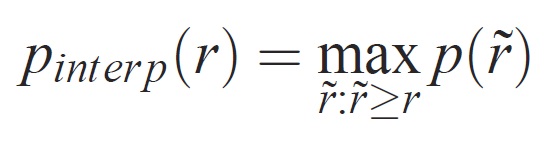
onde p( ̃r) é a precisão medida em recall ̃r. A intenção de interpolar a curva de precisão/recall dessa forma é reduzir o impacto dos "movimentos" na curva de precisão/recall, causado por pequenas variações na classificação de exemplos. Deve-se observar que, para obter uma pontuação alta, um método deve ter precisão em todos os níveis de recall – isso penaliza métodos que recuperam apenas um subconjunto de exemplos com alta precisão (por exemplo, exibições laterais de carros).