Várias GPUs e computadores
1. Introdução
Atualmente, o CNTK dá suporte a quatro algoritmos SGD paralelos:
Pré-requisitos
Para executar o treinamento paralelo, verifique se uma implementação da MPI (Interface de Passagem de Mensagem) está instalada:
No Windows, instale a versão 7 (7.0.12437.6) do MS-MPI (Microsoft MPI), uma implementação da Microsoft do padrão Interface de Passagem de Mensagem, desta página de download, marcada simplesmente como "Versão 7" no título da página. Clique no botão Baixar e selecione o tempo de execução (
MSMpiSetup.exe).No Linux, instale o OpenMPI versão 1.10.x. Siga as instruções aqui para compilá-lo por conta própria.
2. Configurando o treinamento paralelo no CNTK no Python
Para usar o SGD paralelo de dados no Python, o usuário precisa criar e passar um aprendiz distribuído para o treinador:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Para o loop de treinamento definido pelo usuário (em vez de training_session), os usuários precisam passar num_data_partitions e partition_index método para MinibatchSource.next_minibatch() que diferentes nós de MPI leiam dados de partições de dados diferentes (depois distributed_after que os exemplos forem lidos).
Observe que Communicator.finalize() deve ser chamado somente caso o treinamento distribuído seja concluído com êxito. Caso um trabalho distribuído falhe, esse método não deve ser chamado.
Para obter um exemplo totalmente funcional, consulte o exemplo de ConvNet.
3. Configurando o treinamento paralelo no CNTK no BrainScript
Para habilitar o treinamento paralelo no CNTK BrainScript, primeiro é necessário ativar a seguinte opção no arquivo de configuração ou na linha de comando:
parallelTrain = true
Em segundo lugar, o SGD bloco no arquivo de configuração deve conter um subconjunto nomeado ParallelTrain com os seguintes argumentos:
parallelizationMethod: valores legítimos (obrigatórios) sãoDataParallelSGD,BlockMomentumSGDeModelAveragingSGD. .Isso especifica qual algoritmo paralelo a ser usado.
distributedMBReading: (opcional) aceita o valor booliano:trueoufalse; o padrão éfalseÉ recomendável ativar a leitura de minibatch distribuído para minimizar o custo de E/S em cada trabalho. Se você estiver usando o leitor de Formato de Texto CNTK, Leitor de Imagem ou Leitor de Dados Composto, distributedMBReading deverá ser definido como true.
parallelizationStartEpoch: (opcional) aceita o valor inteiro; o padrão é 1.Isso especifica a partir de qual época, algoritmos de treinamento paralelos são usados; antes disso, todos os trabalhadores fazendo o mesmo treinamento, mas apenas um trabalhador tem permissão para salvar o modelo. Essa opção poderá ser útil se o treinamento paralelo exigir algum estágio de "início quente".
syncPerfStats: (opcional) aceita o valor inteiro; o padrão é 0.Isso especifica a frequência com que as estatísticas de desempenho serão impressas. Essas estatísticas incluem o tempo gasto na comunicação e/ou na computação em um período de sincronização, o que pode ser útil para entender o gargalo de algoritmos de treinamento paralelos.
0 significa que nenhuma estatística será impressa. Outros valores especificam a frequência com que as estatísticas serão impressas. Por exemplo,
syncPerfStats=5significa que as estatísticas serão impressas após cada 5 sincronizações.Um subconjunto que especifica detalhes de cada algoritmo de treinamento paralelo. O nome do subconjunto deve ser igual a
parallelizationMethod. (obrigatório)
O Python fornece mais flexibilidade e os usos são mostrados abaixo para diferentes métodos de paralelização.
4. Executando o treinamento paralelo com o CNTK
A paralelização no CNTK é implementada com o MPI.
4.1 Executando treinamento paralelo com o BrainScript
Considerando qualquer uma das configurações do BrainScript de treinamento paralelo acima, os seguintes comandos podem ser usados para iniciar um trabalho de MPI paralelo:
Treinamento paralelo no mesmo computador com Linux:
mpiexec --npernode $num_workers $cntk configFile=$configTreinamento paralelo no mesmo computador com o Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Treinamento paralelo em vários nós de computação com Linux:
Etapa 1: Criar um arquivo de host $hostfile usando seu editor favorito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Onde name_of_node(n) é simplesmente um nome DNS ou endereço IP do nó de trabalho.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Treinamento paralelo em vários nós de computação com o Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
onde $cntk deve se referir ao caminho do executável CNTK ($x é a maneira do shell do Linux substituir variáveis de ambiente, o equivalente %x% no shell do Windows).
4.2 Executando treinamento paralelo com Python
Exemplos de treinamento distribuído para CNTK v2 com Python podem ser encontrados aqui:
Dado um script training.py Python CNTK v2, os seguintes comandos podem ser usados para iniciar um trabalho de MPI paralelo:
Treinamento paralelo no mesmo computador com Linux:
mpiexec --npernode $num_workers python training.pyTreinamento paralelo no mesmo computador com o Windows:
mpiexec -n %num_workers% python training.pyTreinamento paralelo em vários nós de computação com Linux:
Etapa 1: Criar um arquivo de host $hostfile usando seu editor favorito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Onde name_of_node(n) é simplesmente um nome DNS ou endereço IP do nó de trabalho.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Treinamento paralelo em vários nós de computação com o Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
Treinamento de 5 Data-Parallel com SGD de 1 bit
O CNTK implementa a técnica de SGD de 1 bit [1]. Essa técnica permite distribuir cada minibatch sobre K os trabalhadores. Os gradientes parciais resultantes são então trocados e agregados após cada minibatch. "1 bit" refere-se a uma técnica desenvolvida na Microsoft para reduzir a quantidade de dados que são trocados por cada valor de gradiente para um único bit.
5.1 O algoritmo "SGD de 1 bit"
Trocar diretamente gradientes parciais após cada minibatch requer largura de banda de comunicação proibitiva. Para resolver isso, o SGD de 1 bit quantifica agressivamente cada valor de gradiente... para um único bit (!) por valor. Praticamente, isso significa que valores de gradiente grandes são recortados, enquanto valores pequenos são artificialmente inflados. Surpreendentemente, isso não prejudicará a convergência se, e somente se, um truque for usado.
O truque é que, para cada minibatch, o algoritmo compara os gradientes quantizados (que são trocados entre os trabalhadores) com os valores de gradiente originais (que deveriam ser trocados). A diferença entre os dois (o erro de quantização) é calculada e lembrada como o residual. Esse resíduo é adicionado à próxima minibatch.
Como conseqüência, apesar da quantização agressiva, cada valor de gradiente é eventualmente trocado com precisão total; apenas em um atraso. Experimentos mostram que, desde que esse modelo seja combinado com um início quente (um modelo de semente treinado em um pequeno subconjunto dos dados de treinamento sem paralelização), essa técnica tem mostrado que não leva a uma perda de precisão ou muito pequena, permitindo uma aceleração não muito longe de linear (o fator limitador é que as GPUs se tornam ineficientes ao calcular em sub-lotes muito pequenos).
Para obter a eficiência máxima, a técnica deve ser combinada com o dimensionamento automático de minibatch, em que de vez em quando, o treinador tenta aumentar o tamanho da minibatch. Avaliando um pequeno subconjunto da próxima época de dados, o treinador selecionará o maior tamanho de minibatch que não prejudica a convergência. Aqui, é útil que o CNTK especifique a taxa de aprendizagem e os hiperparâmetros de momento de forma agnóstica de tamanho minibatch.
5.2 Usando o SGD de 1 bit no BrainScript
O SGD de 1 bit em si não tem nenhum parâmetro além de habilitá-lo e depois da época em que ele deve começar. Além disso, o dimensionamento automático de minibatch deve ser habilitado. Eles são configurados adicionando os seguintes parâmetros ao bloco SGD:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Observe que Data-Parallel SGD também pode ser usado sem quantização de 1 bit. No entanto, em cenários típicos, especialmente cenários em que cada parâmetro de modelo é aplicado apenas uma vez como para um DNN de avanço de feed, isso não será eficiente devido às altas necessidades de largura de banda de comunicação.
A seção 2.2.3 abaixo mostra os resultados do SGD de 1 bit em uma tarefa de fala, em comparação com o método SGD Block-Momentum que é descrito em seguida. Ambos os métodos não têm ou quase nenhuma perda de precisão em velocidade quase linear.
5.3 Usando o SGD de 1 bit no Python
Para usar o SGD paralelo de dados no Python, opcionalmente com o SGD de 1 bit, o usuário precisa criar e passar um aprendiz distribuído para o treinador:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Alterar num_quantization_bits para 32 durante a criação de distributed_learner faz com que ele use SGD de Data-Parallel não quantificado. Não há necessidade de início quente neste caso.
SGD de 6 Block-Momentum
O SGD do Block-Momentum é a implementação da "atualização e filtragem do modelo em sentido bloqueado", ou BMUF, algoritmo, short Block Momentum [2].
6.1 O algoritmo SGD Block-Momentum
A figura a seguir resume o procedimento no algoritmo Block-Momentum.

6.2 Configurando Block-Momentum SGD no BrainScript
Para usar Block-Momentum SGD, é necessário ter um subconjunto nomeado BlockMomentumSGD no SGD bloco com as seguintes opções:
syncPeriod. Isso é semelhante ao inModelAveragingSGD, que especifica asyncPeriodfrequência com que uma sincronização de modelo é executada. O valorBlockMomentumSGDpadrão é 120.000.resetSGDMomentum. Isso significa que, após cada ponto de sincronização, o gradiente suavizado usado no SGD local será definido como 0. O valor padrão dessa variável é verdadeiro.useNesterovMomentum. Isso significa que a atualização de momento no estilo Anrov é aplicada no nível do bloco. Consulte [2] para obter mais detalhes. O valor padrão dessa variável é verdadeiro.
O momento do bloco e a taxa de aprendizado de bloco geralmente são definidos automaticamente de acordo com o número de trabalhadores usados, ou seja,
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Nossa experiência indica que essas configurações geralmente geram convergência semelhante à do algoritmo SGD padrão de até 64 GPUs, que é o maior experimento que executamos. Também é possível especificar manualmente esses parâmetros usando as seguintes opções:
blockMomentumAsTimeConstantespecifica a constante de tempo do filtro de passagem baixa na atualização do modelo de nível de bloco. É calculado como:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateespecifica a taxa de aprendizado de bloco.
Veja a seguir um exemplo da seção de configuração do SGD Block-Momentum:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Usando Block-Momentum SGD no BrainScript
1. Ajustar novamente os parâmetros de aprendizagem
Para obter uma taxa de transferência semelhante por trabalho, é necessário aumentar o número de amostras em uma minibatch proporcional ao número de trabalhadores. Isso pode ser feito ajustando
minibatchSizeounbruttsineachrecurrentiter, dependendo se a randomização do modo de quadro é usada.Não é necessário ajustar a taxa de aprendizado (ao contrário de Model-Averaging SGD, consulte abaixo).
É recomendável usar Block-Momentum SGD com um modelo de início quente. Em nossas tarefas de reconhecimento de fala, a convergência razoável é obtida ao iniciar de modelos de semente treinados em 24 horas (8,6 milhões de amostras) a 120 horas (43,2 milhões de amostras) dados usando o SGD padrão.
2. Experimentos asr
Usamos o SGD Block-Momentum e os algoritmos SGD de Data-Parallel (1 bit) para treinar DNNs e LSTMs em uma tarefa de reconhecimento de fala de 2600 horas e comparamos as precisões de reconhecimento de palavras versus fatores de velocidade. As tabelas e os números a seguir mostram os resultados (*).
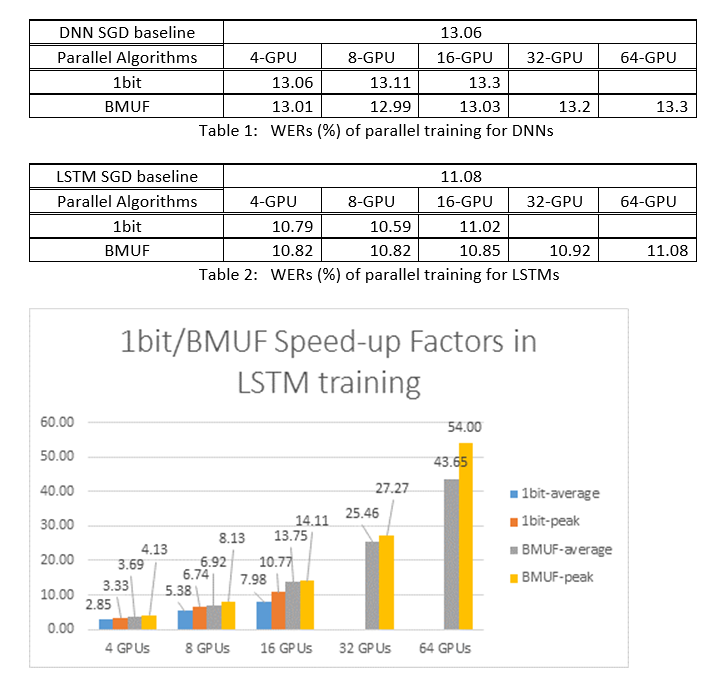
(*): Fator de alta velocidade: para SGD de 1 bit, medido pelo fator de velocidade máxima (em comparação com a linha de base do SGD) obtido em uma minibatch; for Block Momentum, medido pela velocidade máxima obtida em um bloco; Fator de velocidade média: o tempo decorrido na linha de base do SGD dividido pelo tempo decorrido observado. Essas duas métricas são introduzidas devido à latência em E/S pode afetar muito a medição média do fator de aceleração, especialmente quando a sincronização é executada no nível do mini-lote. Ao mesmo tempo, o fator de velocidade máxima é relativamente robusto.
3. Ressalvas
É recomendável definir
resetSGDMomentumcomo true; caso contrário, geralmente leva à divergência do critério de treinamento. Redefinir o momento do SGD para 0 após cada sincronização de modelo essencialmente corta a contribuição dos últimos minibatches. Portanto, é recomendável não usar um grande momento de SGD. Por exemplo, parasyncPeriod120.000, observamos uma perda de precisão significativa se o impulso usado para SGD for 0,99. Reduzir o momento do SGD para 0,9, 0,5 ou até mesmo desabilitá-lo completamente dá precisões semelhantes às que podem ser obtidas pelo algoritmo SGD padrão.Block-Momentum SGD atrasa e distribui atualizações de modelo de um bloco em blocos subsequentes. Portanto, é necessário garantir que as sincronizações de modelo sejam executadas com frequência suficiente no treinamento. Uma verificação rápida é usar
blockMomentumAsTimeConstant. É recomendável que o número de exemplos de treinamento exclusivosNatendam à seguinte equação:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
A aproximação decorre dos seguintes fatos: (1) O momento do bloco geralmente é definido como (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Usando Block-Momentum no Python
Para habilitar Block-Momentum no Python, da mesma forma que o SGD de 1 bit, o usuário precisa criar e passar um aprendiz distribuído de impulso de bloco para o treinador:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Para obter um exemplo totalmente funcional, consulte o exemplo de ConvNet.
7 Model-Averaging SGD
O SGD de Média de Modelos é uma implementação do algoritmo de média do modelo detalhado em [3,4] sem o uso de gradiente natural. A ideia aqui é permitir que cada trabalho processe um subconjunto de dados, mas a média dos parâmetros de modelo de cada trabalho após um período especificado.
Model-Averaging SGD geralmente converge mais lentamente e para um ideal pior, em comparação com o SGD de 1 bit e Block-Momentum SGD, portanto, não é mais recomendado.
Para usar Model-Averaging SGD, é necessário ter um subconjunto nomeado ModelAveragingSGD no SGD bloco com as seguintes opções:
syncPeriodespecifica o número de amostras que cada trabalho precisa processar antes que uma média de modelo seja realizada. O valor padrão é 40.000.
7.1 Usando Model-Averaging SGD no BrainScript
Para tornar o SGD Model-Averaging eficiente e eficiente, os usuários precisam ajustar alguns hipermetrâmetros:
minibatchSizeounbruttsineachrecurrentiter. Suponha quenos trabalhadores estejam participando da configuração do SGD Model-Averaging, a implementação de leitura distribuída atual carregará1/n-th da minibatch em cada trabalho. Portanto, para garantir que cada trabalho produza a mesma taxa de transferência que o SGD padrão, é necessário ampliar o tamanhonda minibatch -fold. Para modelos treinados usando a randomização do modo quadro, isso pode ser obtido aumentandominibatchSizepornvezes; para modelos são treinados usando a randomização do modo de sequência, como RNNs, alguns leitores precisam aumentarnbruttsineachrecurrentiterporn.learningRatesPerSample. Nossa experiência indica que, para obter convergência semelhante à do SGD padrão, é necessário aumentar emlearningRatesPerSampletemposn. Uma explicação pode ser encontrada em [2]. Como a taxa de aprendizagem é aumentada, é necessário um cuidado extra para garantir que o treinamento não divergue — e essa é, de fato, a principal ressalva de Model-Averaging SGD. Você pode usar asAutoAdjustconfigurações para recarregar o melhor modelo anterior se um aumento no critério de treinamento for observado.início quente. Descobriu-se que Model-Averaging SGD geralmente converge melhor se for iniciado a partir de um modelo de semente treinado pelo algoritmo SGD padrão (sem paralelização). Em nossas tarefas de reconhecimento de fala, a convergência razoável é obtida ao iniciar de modelos de semente treinados em 24 horas (8,6 milhões de amostras) a 120 horas (43,2 milhões de amostras) dados usando o SGD padrão.
Veja a seguir um exemplo da seção de ModelAveragingSGD configuração:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Usando Model-Averaging SGD no Python
Esse é um trabalho em andamento.
8 treinamento de Data-Parallel com o servidor de parâmetros
O servidor de parâmetros é uma estrutura amplamente usada no aprendizado de máquina distribuído [5][6][7]. O benefício mais importante que ele traz é o treinamento paralelo assíncrono com muitos trabalhadores. Ele apresenta o servidor de parâmetros como um repositório de modelos distribuído. Em vez de aproveitar diretamente os primitivos do AllReduce para sincronizar atualizações de parâmetro entre os trabalhadores, a estrutura do servidor de parâmetros fornece aos usuários as interfaces como "Adicionar" e "Obter" para permitir que os trabalhadores locais atualizem e recuperem parâmetros globais do servidor de parâmetros. Dessa forma, os trabalhadores locais não precisam esperar uns pelos outros durante o processo de treinamento, o que economiza muito tempo, especialmente quando o número de trabalhadores é grande.
Além disso, como os servidores de parâmetros são uma estrutura distribuída que armazena parâmetros de modelo, os trabalhadores só podem recuperar os parâmetros necessários durante o processo de treinamento em mini-lote, isso traz uma flexibilidade muito boa no método de treinamento distribuído de design e também aumenta a eficiência ao realizar o treinamento com atualizações de modelo esparsas. Nesta versão, nos concentraremos primeiro no treinamento paralelo assíncrono, depois daremos mais introdução sobre como aproveitar a estrutura do servidor de parâmetros para um treinamento de modelo eficiente com atualizações esparsas.
8.1 Usando Data-Parallel ASGD
- Para usar servidores de parâmetros para o SGD assíncrono (abbr. como ASGD), você deve criar o CNTK com suporte do Multiverso , o Multiverso é uma estrutura de servidor de parâmetros geral para a tarefa de aprendizado de máquina distribuída desenvolvida pela equipe do Microsoft Research Asia.
Clone Code: clone o código na pasta raiz do CNTK usando:
git submodule update --init Source/Multiverso
Linux: crie com--asgd=yesno processo de configuração.Windows: adicioneCNTK_ENABLE_ASGDao ambiente do sistema e defina o valor comotrue
- início quente. Em alguns casos, é melhor ter o treinamento de modelo assíncrono iniciado a partir de um modelo de semente (que é treinado pelo algoritmo SGD padrão). De certa forma, o SGD assíncrono traz mais ruído para o treinamento devido às atualizações atrasadas do assíncrono entre os trabalhadores. Alguns modelos são muito sensíveis a esse ruído no início, o que pode resultar em divergência de treinamento de modelo. Sob tal circunstância, um começo quente é necessário.
8.2 Configurando Data-Parallel ASGD no BrainScript
Para usar Data-Parallel ASGD no CNTK, é necessário ter um DataParallelASGD de sub-bloco no bloco SGD com as seguintes opções
-
syncPeriodPerWorkers. Ele especifica o número de exemplos que cada trabalhador precisa processar antes de se comunicar com os servidores de parâmetros. O valor padrão é 256. É recomendado como tamanho de minibatch. É óbvio que a sincronização frequente levará a um alto custo de comunicação significativo. Em nosso teste, não é necessário definir o valor como 1 na maioria dos casos.
-
usePipeline. Ele especifica se ativa o pipeline de recuperação de modelo e computação local. Ativar o pipeline aumentará significativamente a taxa de transferência geral do treinamento, pois ocultará parte ou todo o custo de comunicação. No entanto, às vezes, pode diminuir a taxa de convergência, pois mais atraso será introduzido adicionando pipeline. No geral, a hora do relógio será salva na maioria dos casos com pipeline.
-
AdjustLearningRateAtBeginning. De acordo com o artigo publicado recentemente [5], o treinamento do ASGD é menos estável, e é necessário usar uma taxa de aprendizagem muito menor para evitar explosões ocasionais da perda de treinamento, portanto, o processo de aprendizagem se torna menos eficiente. No entanto, descobrimos que o uso de uma taxa de aprendizagem mais baixa não é necessário para todas as tarefas. E para essas tarefas sensíveis no início, iniciamos o treinamento com pequena taxa de aprendizado e o ampliamos gradualmente no estágio inicial do processo de treinamento até atingir a taxa de aprendizado inicial usada no SGD normal. Dessa forma, a precisão final corresponderá ao SGD com a velocidade do ASGD. Portanto, fornecemos essa opção para que os usuários do ASGD aproveitem esse truque. É um subconjunto no DataParallelASGD com dois parâmetros: adjustCoefficient e adjustNBMiniBatch. A lógica é que a taxa de aprendizagem começa a partir de adjustCoefficient da taxa de aprendizado inicial do SGD e aumenta por ajusteCoefficient da taxa de aprendizagem inicial do SGD a cada mini-lotes adjustNBMiniBatch .
Veja a seguir um exemplo da seção de DataParallelASGD configuração:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Configurando Data-Parallel ASGD no Python
Esse é um trabalho em andamento.
8.4 Experimentos
A figura a seguir mostra os experimentos para testar o ASGD com o conjunto de dados CIFAR-10. O modelo usado neste experimento é uma ResNet de 20 camadas. O algoritmo assíncrono reduz o custo em esperar por todos os nós de trabalho. O ASGD, nesse caso, é claramente mais rápido do que os algoritmos síncronos, como MA e SSGD. *Nos experimentos, todos os modos paralelos sincronizam os parâmetros a cada iteração (atualização em mini-lote). E para o SSGD, usamos atualizações de parâmetro de 32 bits. O algoritmo assíncrono ganha uma vantagem significativa em termos de taxa de transferência de treinamento medida pela velocidade de processamento de exemplo, especialmente quando o número do nó de trabalho sobe para 16.
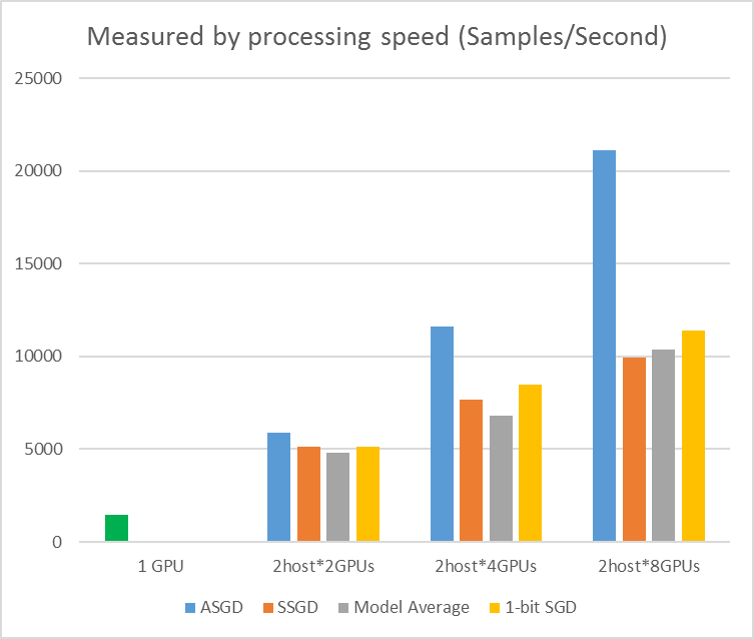 Figura 2.4 a velocidade para diferentes métodos de treinamento
Figura 2.4 a velocidade para diferentes métodos de treinamento
Referências
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li e Dong Yu, "descendente de gradiente estocástico de 1 bit e seu aplicativo para treinamento distribuído de DNNs de fala em paralelo de dados", em Proceedings of Interspeech, 2014.
[2] K. Chen e Q. Huo, "Treinamento escalonável de máquinas de aprendizado profundo por treinamento de bloco incremental com otimização paralela intra-bloco e filtragem de atualização de modelo em sentido bloqueado", no Proceedings of ICASSP, 2016.
[3] M. Zinkevich, M. Weimer, L. Li e A. J. Smola, "Descendente de gradiente estocástico paralelizado", em Proceedings of Advances in NIPS, 2010, pp. 2595-2603.
[4] D. Povey, X. Zhang e S. Khudanpur, "Treinamento paralelo de DNNs com gradiente natural e média de parâmetros", em Proceedings of the International Conference on Learning Representations, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Redes profundas distribuídas em larga escala. Em Avanços nos sistemas de processamento de informações neurais, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen e Alexander Smola. "Servidor de parâmetros para aprendizado de máquina distribuído." No Workshop nips do Big Learning, vol. 6, p. 2. escrito por Tomas Mikolov e colaboradores em 2013.