Cluster K-means
Importante
O suporte para o Machine Learning Studio (clássico) terminará em 31 de agosto de 2024. É recomendável fazer a transição para o Azure Machine Learning até essa data.
A partir de 1º de dezembro de 2021, você não poderá criar recursos do Machine Learning Studio (clássico). Até 31 de agosto de 2024, você pode continuar usando os recursos existentes do Machine Learning Studio (clássico).
- Confira informações sobre como mover projetos de machine learning do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning.
A documentação do ML Studio (clássico) está sendo desativada e pode não ser atualizada no futuro.
Configura e inicializa um modelo de clustering K-means
Categoria: Machine Learning/Inicializar modelo/clustering
Observação
Aplica-se a: Somente Machine Learning Studio (clássico)
Módulos semelhantes do tipo "arrastar e soltar" estão disponíveis no designer do Azure Machine Learning.
Visão geral do módulo
Este artigo descreve como usar o módulo clustering K-Means no Machine Learning Studio (clássico) para criar um modelo de clustering K-means não treinado.
K-means é um dos algoritmos de aprendizado não supervisionado mais simples e mais conhecidos, e pode ser usado para uma variedade de tarefas de aprendizado de máquina, como detectar dados anormais, clustering de documentos de texto e análise de um conjunto de dados antes de usar outros métodos de classificação ou regressão. Para criar um modelo de clustering, adicione este módulo ao experimento, conecte um conjunto de dados e defina parâmetros como o número de clusters esperado, a métrica de distância a ser usada na criação dos clusters e assim por diante.
Depois de configurar os hiperparâmetros do módulo, conecte o modelo não treinado aos módulos Treinar Modelo de Clustering ou Clustering de Varredura para treinar o modelo nos dados de entrada fornecidos. Como o algoritmo K-means é um método de aprendizado não supervisionado, uma coluna de rótulo é opcional.
- Se seus dados incluírem um rótulo, você poderá usar os valores de rótulo para orientar a seleção dos clusters e otimizar o modelo.
- Se os dados não tiverem nenhum rótulo, o algoritmo criará clusters que representam as categorias possíveis, com base apenas nos dados.
Dica
Se os dados de treinamento tiverem rótulos, considere usar um dos métodos de classificação supervisionados fornecidos no Machine Learning. Por exemplo, você pode comparar os resultados de clustering com os resultados ao usar um dos algoritmos de árvore de decisão multiclasse.
Noções básicas sobre clustering k-means
Em geral, o clustering usa técnicas iterativas para agrupar casos em um conjunto de dados em clusters que contenham características semelhantes. Esses agrupamentos são úteis para explorar dados, identificando anomalias nos dados e criar previsões. Modelos de clustering também podem ajudar a identificar relações em um conjunto de dados que você pode não derivar logicamente por meio de navegação ou simples observação. Por esses motivos, clustering é frequentemente usado nas fases iniciais da tarefa de aprendizado de máquina para explorar os dados e descobrir correlações inesperadas.
Ao configurar um modelo de clustering usando o método k-means, você deve especificar um número de destino k indicando o número de centroides desejados no modelo. O centroide é um ponto representativo de cada cluster. O algoritmo K-means atribui cada ponto de dados de entrada a um dos clusters minimizando a soma de quadrados dentro do cluster.
Ao processar os dados de treinamento, o algoritmo K-means começa com um conjunto inicial de centroides escolhidos aleatoriamente, que servem como pontos de partida para cada cluster e aplica o algoritmo de Lloyd para refinar iterativamente os locais dos centroides. O algoritmo K-means para de criar e refinar os clusters quando ele atende a uma ou mais das seguintes condições:
Os centroides se estabilizam, o que significa que as atribuições de cluster para pontos individuais não mudam mais e o algoritmo convergiu em uma solução.
O algoritmo é concluído executando o número especificado de iterações.
Depois de concluir a fase de treinamento, use o módulo Atribuir Dados a Clusters para atribuir novos casos a um dos clusters encontrados pelo algoritmo k-means. A atribuição de cluster é executada calculando a distância entre o novo caso e o centroide de cada cluster. Cada novo caso é atribuído ao cluster com o centroide mais próximo.
Como configurar o cluster K-Means
Adicione o módulo Clustering K-Means ao seu experimento.
Especifique como você deseja que o modelo seja treinado definindo a opção Criar modo de aprendizagem.
Parâmetro único: se você souber os parâmetros exatos que deseja usar no modelo de clustering, poderá fornecer um conjunto específico de valores como argumentos.
Intervalo de parâmetros: se você não tiver certeza dos melhores parâmetros, poderá encontrar os parâmetros ideais especificando vários valores e usando o módulo Clustering de Varredura para encontrar a configuração ideal.
O treinador itera em várias combinações das configurações fornecidas e determina a combinação de valores que produz os resultados clustering ideais.
Para Número de Centroides, digite o número de clusters com os quais você deseja que o algoritmo comece.
Não há garantia de que o modelo produza exatamente esse número de clusters. O algorithn começa com esse número de pontos de dados e itera para encontrar a configuração ideal, conforme descrito na seção Notas Técnicas .
Se você estiver executando uma varredura de parâmetro, o nome da propriedade será alterado para Intervalo para Número de Centroides. Você pode usar o Construtor de Intervalos para especificar um intervalo ou pode digitar uma série de números que representam diferentes números de clusters a serem criados ao inicializar cada modelo.
As propriedades Inicialização ou Inicialização para varredura são usadas para especificar o algoritmo usado para definir a configuração inicial do cluster.
Primeiro N: alguns números iniciais de pontos de dados são escolhidos no conjunto de dados e usados como os meios iniciais.
Também chamado de método Forgy.
Aleatório: O algoritmo coloca aleatoriamente um ponto de dados em um cluster e, em seguida, calcula a média inicial para ser o centroide dos pontos atribuídos aleatoriamente do cluster.
Também chamado de método de partição aleatória .
K-means++ : Esse é o método padrão para inicializar clusters.
O algoritmo K-means ++ foi proposto em 2007 por David Arthur e Sergei Vassilvitskii para evitar clustering ruins pelo algoritmo k-means padrão. K-means ++ melhora em K-means padrão usando um método diferente para escolher os centros de cluster iniciais.
K-Means++Fast: uma variante do algoritmo K-means ++ que foi otimizada para clustering mais rápido.
Uniformemente: centroides estão localizados equidistantes uns dos outros no espaço d-Dimensional de n pontos de dados.
Usar coluna de rótulo: os valores na coluna de rótulo são usados para orientar a seleção de centroides.
Para Semente de número aleatório, opcionalmente, digite um valor a ser usado como semente para a inicialização do cluster. Esse valor pode ter um efeito significativo na seleção de cluster.
Se você usar uma varredura de parâmetro, poderá especificar que várias sementes iniciais sejam criadas para procurar o melhor valor de semente inicial. Para Número de sementes a serem limpas, digite o número total de valores de semente aleatória a serem usados como pontos de partida.
Para Métrica, escolha a função a ser usada para medir a distância entre os vetores de cluster ou entre os novos pontos de dados e os centroides escolhidos aleatoriamente. O Machine Learning dá suporte às seguintes métricas de distância do cluster:
Euclidiana: A distância Euclidiana normalmente é usada como uma medida de dispersão de cluster para clusters K-means. Essa métrica é preferencial porque minimiza a distância média entre pontos e os centroides.
Cosseno: a função cosseno é usada para medir a similaridade do cluster. A similaridade cosseno é útil em casos em que você não se importa com o comprimento de um vetor, apenas seu ângulo.
Para iterações, digite o número de vezes que o algoritmo deve iterar sobre os dados de treinamento antes de finalizar a seleção de centroides.
Você pode ajustar esse parâmetro para equilibrar precisão versus tempo de treinamento.
Para Atribuir modo de rótulo, escolha uma opção que especifica como uma coluna de rótulo, se presente no conjunto de dados, deve ser tratada.
Como o clustering K-means é um método de aprendizado de máquina não supervisionado, os rótulos são opcionais. No entanto, se o conjunto de dados já tiver uma coluna de rótulo, você poderá usar esses valores para orientar a seleção dos clusters ou pode especificar que os valores sejam ignorados.
Ignorar coluna de rótulo: Os valores na coluna de rótulo são ignorados e não são usados na criação do modelo.
Preencher valores ausentes: Os valores de coluna de rótulo são usados como recursos para ajudar a criar os clusters. Se alguma linha estiver sem um rótulo, o valor será atribuído usando outros recursos.
Substituir do mais próximo ao centro: Os valores de coluna de rótulo são substituídos por valores de rótulo previstos, usando o rótulo do ponto mais próximo do centroide atual.
Treinar o modelo.
Se você definir Criar modo de aprendizagem como Parâmetro único, adicione um conjunto de dados marcado e treine o modelo usando o módulo Treinar modelo de clustering.
Se você definir Criar modo de treinador como Intervalo de Parâmetros, adicione um conjunto de dados marcado e treine o modelo usando Clustering de Varredura. Você pode usar o modelo treinado usando esses parâmetros ou pode anotar as configurações de parâmetro a serem usadas ao configurar um aprendiz.
Resultados
Depois de concluir a configuração e o treinamento do modelo, você terá um modelo que pode ser usado para gerar pontuações. No entanto, há várias maneiras de treinar o modelo e várias maneiras de exibir e usar os resultados:
Capturar um instantâneo do modelo em seu espaço de trabalho
Se você usou o módulo Treinar Modelo de Clustering
- Clique com o botão direito no módulo Treinar modelo de clustering.
- Selecione Modelo treinado e clique em Salvar como Modelo Treinado.
Se você usou o módulo Clustering de Varredura para treinar o modelo
- Clique com o botão direito do mouse no módulo Clustering de Varredura .
- Selecione Modelo mais bem treinado e clique em Salvar como Modelo Treinado.
O modelo salvo representará os dados de treinamento no momento em que você salvou o modelo. Se você atualizar posteriormente os dados de treinamento usados no experimento, ele não atualizará o modelo salvo.
Ver uma representação visual dos clusters no modelo
Se você usou o módulo Treinar Modelo de Clustering
- Clique com o botão direito do mouse no módulo e selecione Conjunto de dados de resultados.
- Selecione Visualizar.
Se você usou o módulo Clustering de Varredura
Adicione uma instância do módulo Atribuir Dados a Clusters e gere pontuações usando o modelo Melhor Treinado.
Clique com o botão direito do mouse no módulo Atribuir Dados a Clusters , selecione Conjunto de dados de resultados e selecione Visualizar.
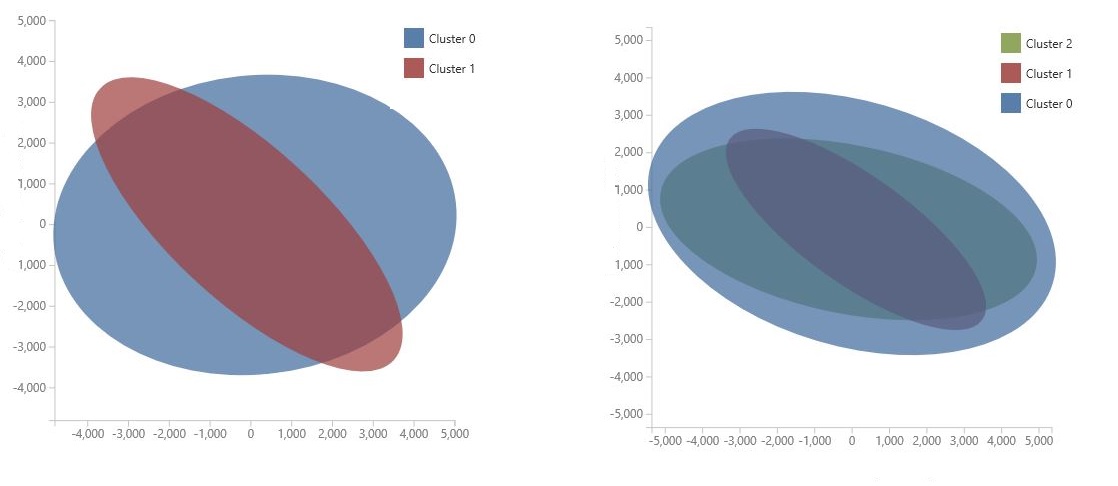
O gráfico é gerado usando a Análise de Componente Principal, que é uma técnica na ciência de dados para compactar o espaço de recursos de um modelo. O gráfico mostra alguns conjuntos de recursos, compactados em duas dimensões, que caracterizam melhor a diferença entre os clusters. Examinando visualmente o tamanho geral do espaço de recurso para cada cluster e quanto os clusters se sobrepõem, você pode ter uma ideia do desempenho do modelo.
Por exemplo, os gráficos PCA a seguir representam os resultados de dois modelos treinados usando os mesmos dados: o primeiro foi configurado para gerar dois clusters e o segundo foi configurado para gerar três clusters. Nesses gráficos, você pode ver que aumentar o número de clusters não necessariamente melhorou a separação das classes.
Dica
Use o módulo Clustering de Varredura para escolher o conjunto ideal de hiperparâmetros, incluindo a semente aleatória e o número de centroides iniciais.
Veja a lista de pontos de dados e os clusters aos quais eles pertencem
Há duas opções para exibir o conjunto de dados com resultados, dependendo de como você treinou o modelo:
Se você usou o módulo Clustering de Varredura para treinar o modelo
- Use a caixa de seleção no módulo Clustering de Varredura para especificar se deseja ver os dados de entrada junto com os resultados ou ver apenas os resultados.
- Quando o treinamento for concluído, clique com o botão direito do mouse no módulo e selecione Conjunto de dados de resultados (número de saída 2)
- Clique em Visualizar.
Se você usou o módulo Treinar Modelo de Clustering
- Adicione o módulo Atribuir Dados a Clusters e conecte o modelo treinado à entrada à esquerda. Conecte um conjunto de dados à entrada à direita.
- Adicione o módulo Converter em Conjunto de Dados ao seu experimento e conecte-o à saída de Atribuir Dados a Clusters.
- Use a caixa de seleção no módulo Atribuir Dados a Clusters para especificar se deseja ver os dados de entrada junto com os resultados ou ver apenas os resultados.
- Execute o experimento ou execute apenas o módulo Converter em Conjunto de Dados .
- Clique com o botão direito do mouse em Converter em Conjunto de Dados, selecione Conjunto de dados resultados e clique em Visualizar.
A saída contém as colunas de dados de entrada primeiro, se você as incluiu, e as seguintes colunas para cada linha de dados de entrada:
Atribuição: a atribuição é um valor entre 1 e n, em que n é o número total de clusters no modelo. Cada linha de dados pode ser atribuída a apenas um cluster.
DistancesToClusterCenter no.n: esse valor mede a distância do ponto de dados atual até o centroide do cluster. Uma coluna separada na saída para cada cluster no modelo treinado.
Os valores para a distância do cluster baseiam-se na métrica de distância selecionada na opção Métrica para medir o resultado do cluster. Mesmo que você execute uma varredura de parâmetros no modelo de clustering, apenas uma métrica poderá ser aplicada durante a varredura. Se você alterar a métrica, poderá obter valores de distância diferentes.
Visualizar distâncias dentro do cluster
No conjunto de dados de resultados da seção anterior, clique na coluna de distâncias para cada cluster. O Studio (clássico) exibe um histograma que visualiza a distribuição de distâncias para pontos dentro do cluster.
Por exemplo, os histogramas a seguir mostram a distribuição de distâncias de cluster do mesmo experimento, usando quatro métricas diferentes. Todas as outras configurações para a varredura de parâmetro eram as mesmas. A alteração da métrica resultou em um número diferente de clusters em um modelo.
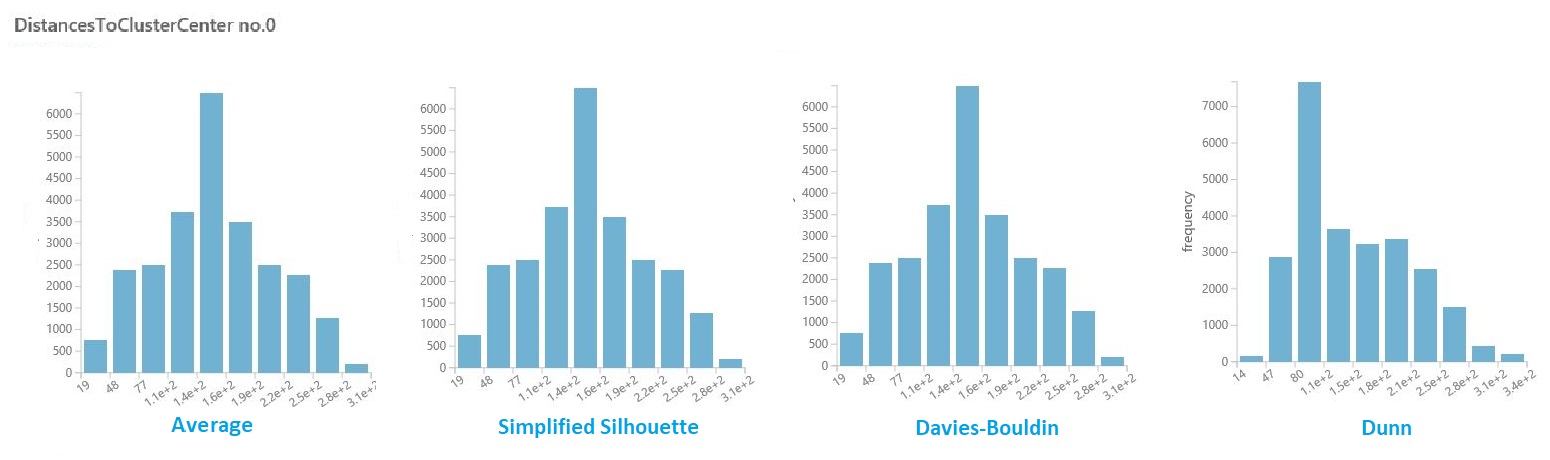
Em geral, você deve escolher uma métrica que maximize a distância entre pontos de dados em classes diferentes e minimize distâncias dentro de uma classe. Você pode usar os meios pré-computados e outros valores no painel Estatísticas para orientá-lo nesta decisão.
Dica
Você pode extrair meios e outros valores usados em visualizações usando o módulo do PowerShell para Machine Learning.
Ou use o módulo Executar Script R para calcular uma matriz de distância personalizada.
Dicas para gerar o melhor modelo de clustering
Sabe-se que o processo de propagação usado durante clustering pode afetar significativamente o modelo. Propagação significa o posicionamento inicial de pontos em centroides potentes.
Por exemplo, se o conjunto de dados contiver muitas exceções e uma exceção for escolhida para propagar os clusters, nenhum outro ponto de dados caberá bem com esse cluster e o cluster poderá ser um singleton: ou seja, um cluster com apenas um ponto.
Há várias maneiras de evitar esse problema:
Use uma varredura de parâmetro para alterar o número de centroides e experimentar vários valores de semente.
Crie vários modelos, variando a métrica ou iterando mais.
Use um método como pca para localizar variáveis que têm um efeito prejudicial sobre clustering. Consulte o exemplo Localizar empresas semelhantes para obter uma demonstração dessa técnica.
Em geral, com clustering modelos, é possível que qualquer configuração determinada resulte em um conjunto de clusters otimizado localmente. Em outras palavras, o conjunto de clusters retornados pelo modelo se ajusta apenas aos pontos de dados atuais e não é generalizável para outros dados. Se você usou uma configuração inicial diferente, o método K-means pode encontrar uma configuração diferente, talvez superior.
Importante
Recomendamos que você sempre experimente os parâmetros, crie vários modelos e compare os modelos resultantes.
Exemplos
Para obter exemplos de como o K-means clustering é usado no Machine Learning, consulte estes experimentos na Galeria de IA do Azure:
Agrupar dados de íris: compara os resultados de Clustering K-Means e Regressão Logística Multiclasse para uma tarefa de classificação.
Exemplo de quantização de cores: cria vários modelos K-means com parâmetros diferentes para encontrar a compactação de imagem ideal.
Clustering: Empresas semelhantes: varia o número de centroides para encontrar grupos de empresas semelhantes no S&P500.
Observações técnicas
Dado um número específico de clusters (K) para localizar para um conjunto de pontos de dados de D dimensões com N pontos de dados, o algoritmo K-means cria os clusters da seguinte maneira:
O módulo inicializa uma matriz K-by-D com os centroides finais que definem os clusters K encontrados.
Por padrão, o módulo atribui os primeiros pontos de dados K para os clusters K .
Começando com um conjunto inicial de centroides K, o método usa o algoritmo de Lloyd para refinar de forma iterativa os locais dos centróides.
O algoritmo termina quando os centróides estabilizarem ou quando um número especificado de iterações for concluído.
Uma métrica de similaridade (por padrão, a distância Euclidiana) é usada para atribuir a cada ponto de dados para o cluster que tem o centroide mais próximo.
Aviso
- Se você passar um intervalo de parâmetros para Treinar Modelo de Clustering, ele usará apenas o primeiro valor na lista de intervalos de parâmetros.
- Se você passar um único conjunto de valores de parâmetro para o módulo Clustering de Varredura , quando ele espera um intervalo de configurações para cada parâmetro, ele ignora os valores e usa os valores padrão para o aprendiz.
- Se escolher a opção Intervalo de Parâmetros e inserir um único valor para um parâmetro, esse valor único especificado será usado em toda a varredura, mesmo que outros parâmetros sejam alterados em um intervalo de valores.
Parâmetros do módulo
| Nome | Intervalo | Type | Padrão | Descrição |
|---|---|---|---|---|
| Número de centroides | >=2 | Integer | 2 | Número de centroides |
| Métrica | Lista (subconjunto) | Métrica | Euclidiana | Métrica selecionada |
| Inicialização | Lista | Método de inicialização de centroides | K-Means++ | Algoritmo de inicialização |
| Iterações | >=1 | Integer | 100 | Número de iterações |
Saídas
| Nome | Tipo | Descrição |
|---|---|---|
| Modelo não treinado | Interface ICluster | Modelo de clustering K-Means não treinado |
Exceções
Para obter uma lista de todas as exceções, consulte Códigos de erro do módulo do Machine Learning.
| Exceção | Descrição |
|---|---|
| Erro 0003 | Ocorrerá uma exceção se uma ou mais das entradas for nula ou estiver vazia. |
Confira também
Clustering
Atribuir Dados a Clusters
Treinar Modelo de Clustering
Clustering de varredura